improving inference times Achieving 62x Faster Inference than HuggingFace with MonsterDeploy In this case study, we compare the inference times of Hugging Face and MonsterDeploy. Here's how we achieved 50X faster inference than Hugging Face.
Artificial intelligence vs machine learning Artificial Intelligence vs Machine Learning vs Deep Learning - A Comprehensive Guide In this guide, we break down the difference between AI, ML, & DL. Dive deep into what these technologies mean, their application, and the challenges surrounding them.
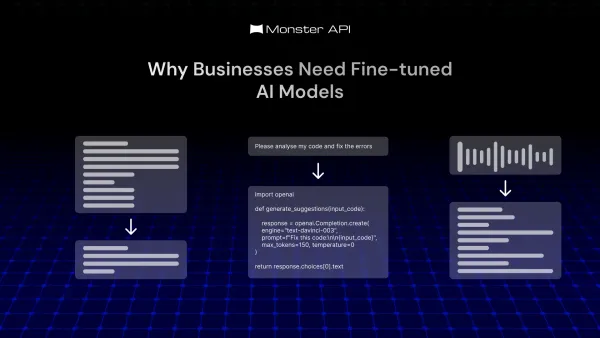
LLM fine-tuning 5 Reasons Your Business Needs a Fine-Tuned AI Model Businesses can streamline their operations with fine-tuned LLMs. Not only that, they can do so much more. Read why businesses need fine-tuned LLMs in our comprehensive guide.
AI image tools 7 Best AI Image Generators for Creators and Marketers Which is the best AI image generation model? We've chosen the top 7 models that help marketers create high-definition images with simple text prompts.
AI statistics 2024 100+ Essential AI Statistics You Should Know for 2024 AI, the definitive technology of today & probably the future is changing life as we know it. The AI market is exploding and will continue to do so in the future. The growth of AI market can’t just be described in words. This is why we’ve compiled interesting
image to video Best 7 Image-to-Video AI Models in 2024 In this guide, we've compiled the best image-to-video models that can create stunning videos out of images. Here's our pick of the top image-to-video models.
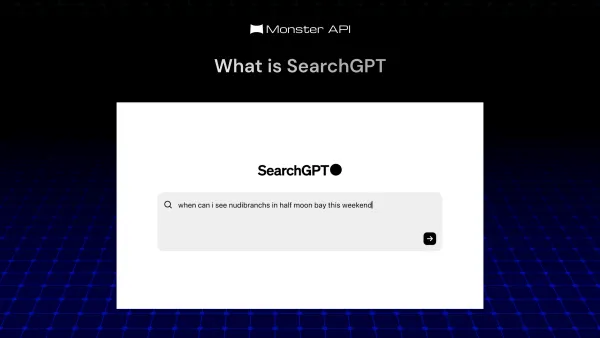
searchGPT What is SearchGPT? Google’s Latest Opponent SearchGPT is the newest entry in the search engine space from OpenAI. In this guide, we're exploring what SearchGPT is and how it may change the search engine space forever.
LLMs for coding The Best Large Language Models (LLMs) for Coding: A Comprehensive Guide In this guide, we're covering all the best Large Language models you can use for code generation, their unique features, and how they boost productivity.
code development with AI How to Improve Code Suggestions With AI-Powered Development Tools In this guide, we’ll talk about the intricacies of improving code suggestions from AI tools, addressing both current inadequacies and potential pathways for enhancement.
llm evaluation performance How to Evaluate LLM Performance Using MonsterAPI Evaluating your LLM performance is essential to ensure you get quality output. Here's how to evaluate your LLM's performance with MonsterAPI.
image classification models Best Image Classification Models in 2024 You can find pre-trained models that can accomplish any task you want. These models, trained on a large corpus of data can capture patterns and features. There are models made specifically for image classifications. Using pre-trained models, developers can save on time and cost. Instead of doing hours of manual
llama 3.1 finetuning Building a Sarcastic Chatbot: A Case Study in Fine-Tuning and Deployment with MonsterAPI We ran a fun experiment and fine-tuned the LLaMa 3.1 8B model to create a sarcastic chatbot. Here's a complete breakdown of how we did it, and the fun results we got.
SDXL fine-tuning How to Fine-tune SDXL for Avatar Generation on MonsterAPI Convert your images into classy avatars by fine-tuning SDXL In just 3 steps, fine-tune SDXL and make your personal avatar generation agent.
Llama 3.2 Comprehensive Guide for Instruction Fine-tuning of LLaMa 3.2 using MonsterAPI In this blog, we'll teach you how to fine-tune a llama-3.2 model to generate code using the alpaca Python coding dataset. We'll use LORA, which preserves the pre-trained model knowledge while facilitating its seamless learning of new things.
Whisper Finetuning How to Finetune Whisper for Speech-to-Text Transcription Whisper Fine-tuning for speech-to-text transcription can be complicated if you don't know what to do. Use MonsterAPI's fine-tuning & deployment pipeline to streamline the process.
finetuning sdxl How to run a fine-tuned image generation SDXL model? Fine-tuning the SDXL model for your use case is complicated. Deploying the finetuned SDXL model is even more complex. So, we created this step by step guide on how to run SDXL model.
Data augmentation How to Build a Dataset for LLM Fine-tuning Building the right dataset for LLM fine-tuning makes all the performance for LLM fine-tuning. Here's how to build a dataset for LLM fine-tuning.
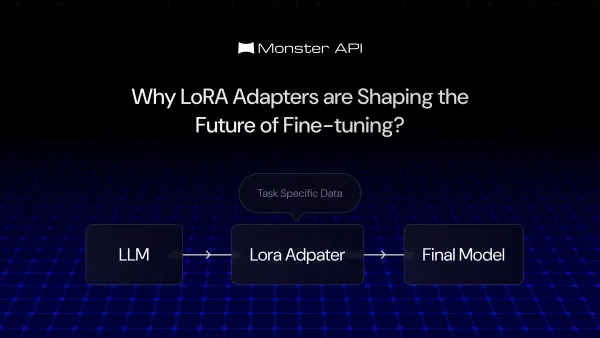
LoRA Finetuning 5 Reasons Why LoRA Adapters are the Future of Fine-Tuning LoRA (Low-Rank Adaption) is a game-changing solution for optimizing the fine-tuning of large language models. Here's how LoRA adapters are future of fine-tuning.
Apple intelligence Apple Intelligence Unveiled: The Next-Gen AI Driving Personalized Experiences Apple intelligence has taken the tech world by storm. Apple has showcased Apple Intelligence's incredible capabilities. Here's everything you need to know about Apple Intelligence.
llm deployment Deploying Large Language Models: Navigating the Unknown Deploying a large language model to fit a use case can be extremely challenging. Here are all the best practices to consider during LLM deployment.
gemma 2 2b Fine-tuning Gemma-2–2B-it for Translation In this guide, we're showing you how to fine-tune a Gemma 2 2B model for English to Hindi translation.
perplexity score Using Perplexity to eliminate known data points In this guide, we're covering the most reliable metric to determine how important are data points in the cluster for training an LLM.
dataset thinning Dataset Thinning for faster fine-tuning of LLMs The quantity of the dataset is often confused with the quantity. Datasets with large corpus of data aren't the best when it comes to fine-tuning. Here's how to speed up fine-tuning and improve the performance of your model with dataset thinning.
instruction pretraining Instruction Pre-Training of Language models using Monster-API Pre-training is a crucial step in the development of large-scale language models, forming the bedrock upon which their language understanding and generation capabilities are built.
llm leaderboard Top 12 LLM Leaderboards to Help You Choose the Right Model Here's our pick of the best-rated open LLM leaderboards. With these models, you can choose the right model for your AI model.