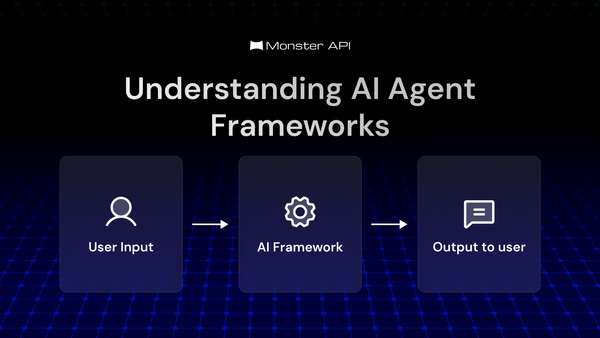
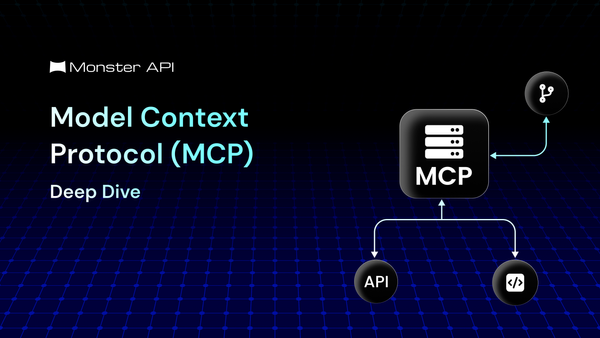
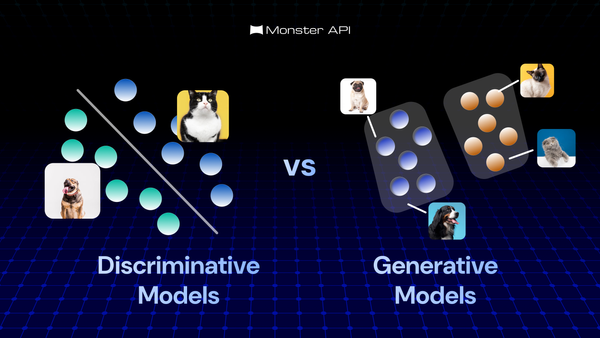
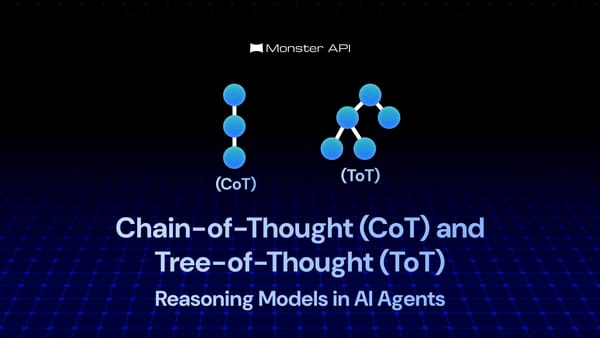
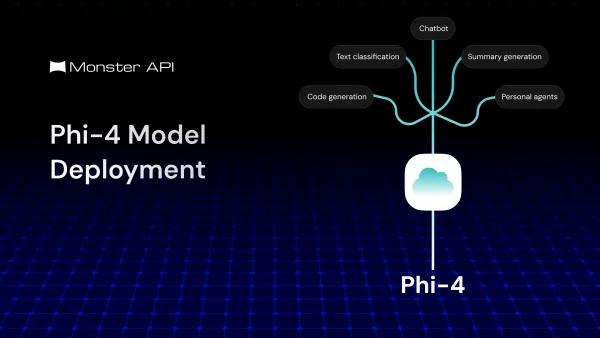
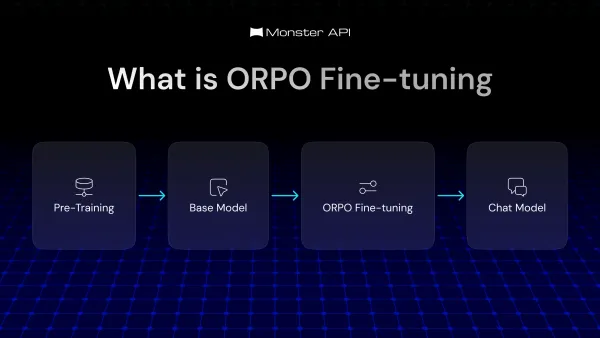
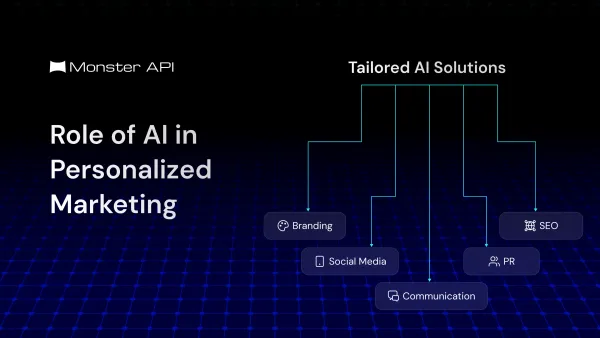
The Model Context Protocol (MCP) is an open, standardized protocol that defines how AI models can interact with external tools, data sources, and memory systems in a structured, controlled, and context-aware manner. This blog breaks down its architecture, flow, and practical challenges.