
How to finetune Llama 2 LLM


LLaMA 2 is an impressive family of pre-trained and fine-tuned Large Language Models (LLMs) released by Meta AI ranging from 7B to 70B parameters (7B, 13B, 70B).
As successors to the already impressive LLaMA 1, these newer versions are more refined, offering a host of enhancements that have everyone in the NLP community talking.
With a massive corpus containing 40% more tokens than its predecessor, Llama 2 models have a profound grasp of context, boasting an impressive context length of 4K tokens.
In this guide, we'll walk you through the process of fine-tuning LLaMA 2 - 7B model using the CodeAlpaca-20k Dataset, all at a fraction of the cost, using Monster API's No-Code LLM-Finetuner.
But first, what is CodeAlpaca-20k Dataset?
The CodeAlpaca-20k Dataset is a rich collection of Coding Questions and their corresponding correct answers. It is provided as a JSON file, where each set of instructions is represented as a dictionary containing three fields:
- Instruction: This field describes the specific coding task the language model should perform.
- Input: Optionally, some instructions are accompanied by an "input" field, which provides additional context for the given task.
- Output: The "output" field contains the correct answer to the instruction, generated using OpenAI's text-davinci-003 model.
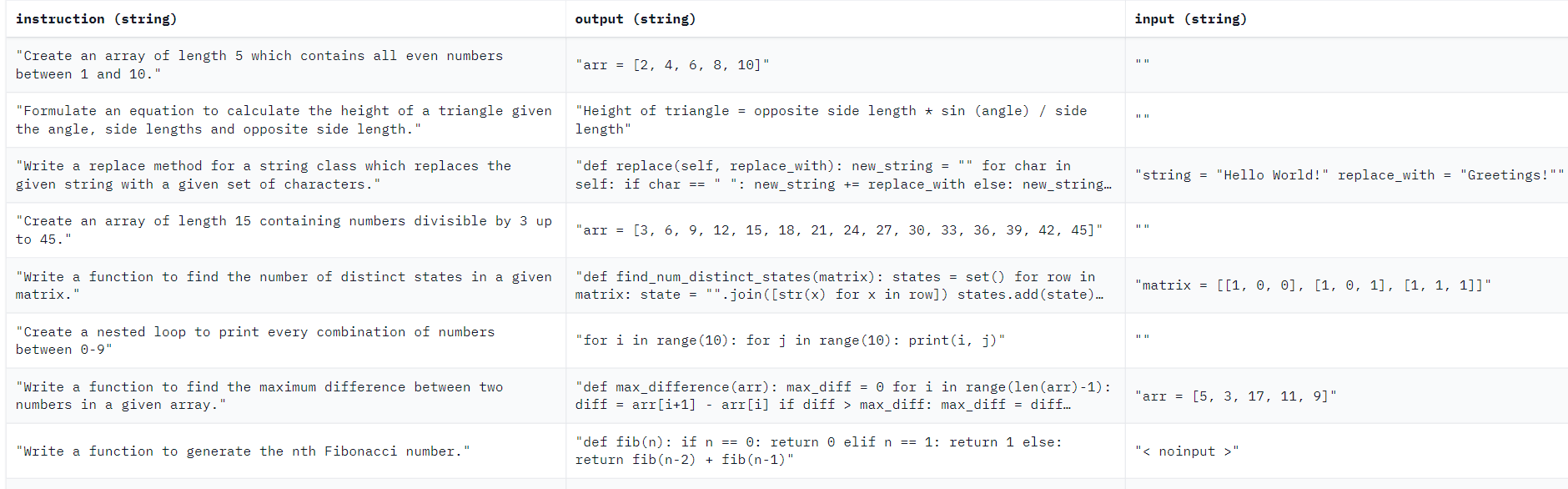
We will leverage the diversity and richness of the CodeAlpaca-20k Dataset to fine-tune the powerful LLaMA 2 - 7B model to develop a coding chatbot.
What is LLM Fine-Tuning and why is it so important?
Language models like LLaMA are initially trained on vast amounts of general language data to learn patterns, grammar, and context. So they're able to perform a lot of basic tasks incredibly well. However, if you want best results on a particular task, you'd need to fine-tune the model on your dataset.
Fine-tuning comes to the rescue, allowing users to enhance the model's performance in three crucial ways:
• More Accurate
• Context-Aware
• Aligned with the target application.
By Fine-tuning LLaMa 2, you can tailor the pre-trained models to give you the desired results for particular tasks. Fine-tuning is the most effective way of transferring their general language knowledge to the specialized task of your choice.
However, fine-tuning an LLM is not as easy as it looks on the surface. Developers may encounter several obstacles when attempting to fine-tune foundational language models like GPT-J or LLaMA.
Challenges in Current LLM Fine-tuning Landscape
- Complex Setups: Configuring GPUs and software dependencies for fine-tuning foundational models can be intricate and time-consuming, necessitating manual management and setup.
- Memory Constraints: Fine-tuning large language models demands significant GPU memory, which can be limiting for developers with resource constraints.
- GPU Costs: The expenses associated with GPU usage for fine-tuning can be costly, making it a luxury not all developers can afford.
- Lack of Standardized Methodologies: The absence of standardized practices can make the fine-tuning process frustrating and time-consuming, as developers may need to navigate through various documentation and forums to find the best approach.
As a result, it can be challenging for developers to tailor a model to meet their specific needs. Nevertheless, despite these challenges, fine-tuning remains a crucial step in harnessing the full potential of LLMs.
How you can use Monster API to help solve the challenges?
MonsterAPI has simplified and effectively made the often intricate fine-tuning process straightforward and quick, reducing the complex setup to a simple, easy-to-follow UI native approach.
With MonsterAPI's no-code LLM FineTuner, those challenges are effectively addressed. Here's how it benefits you:
- Simplified Setup: MonsterAPI provides a user-friendly, intuitive interface that completely removes the effort of setting up a GPU environment for Fine-tuning by deploying your finetuning jobs automatically on pre-configured GPU instances. Thus, eliminating the need for manual hardware specifications and low-level configurations.
- Optimized Memory Utilization: MonsterAPI FineTuner optimizes memory usage during the process, making large language model Fine-tuning manageable even with limited GPU memory.
- Low-cost GPU Access: Monster API offers access to its decentralized GPU network, providing on-demand access to affordable GPU instances, reducing the overall cost and complexity associated with Fine-tuning LLMs.
- Standardized workflow: The platform provides predefined tasks and recipes, guiding developers through the Fine-tuning process without the need to search through extensive documentation and forums. It also allows for flexibility to create custom tasks.
How to get started with finetuning LLMs like Llama 2?
In just five simple steps, you can set up your fine-tuning task and experience remarkable results.
So, let's get started and explore the process together!
1. Select a Language Model for Finetuning
Choose from popular open-source models like Llama 2 7B, GPT-J 6B, or StableLM 7B.

- Upload Dataset
Next, choose from pre-defined tasks or create a custom one to suit your needs. If your task is unique, choose the "Other" option to create a custom task.
In the next field, choose the dataset you want to use. You can either use a HuggingFace dataset or upload your custom dataset.
Select task type and choose dataset
- Specify Hyper-parameters
Monster API simplifies the process by pre-filling most of the hyper-parameters based on your selected LLM. You have the freedom to customize parameters such as epochs, learning rate, cutoff length, warmup steps, and more.
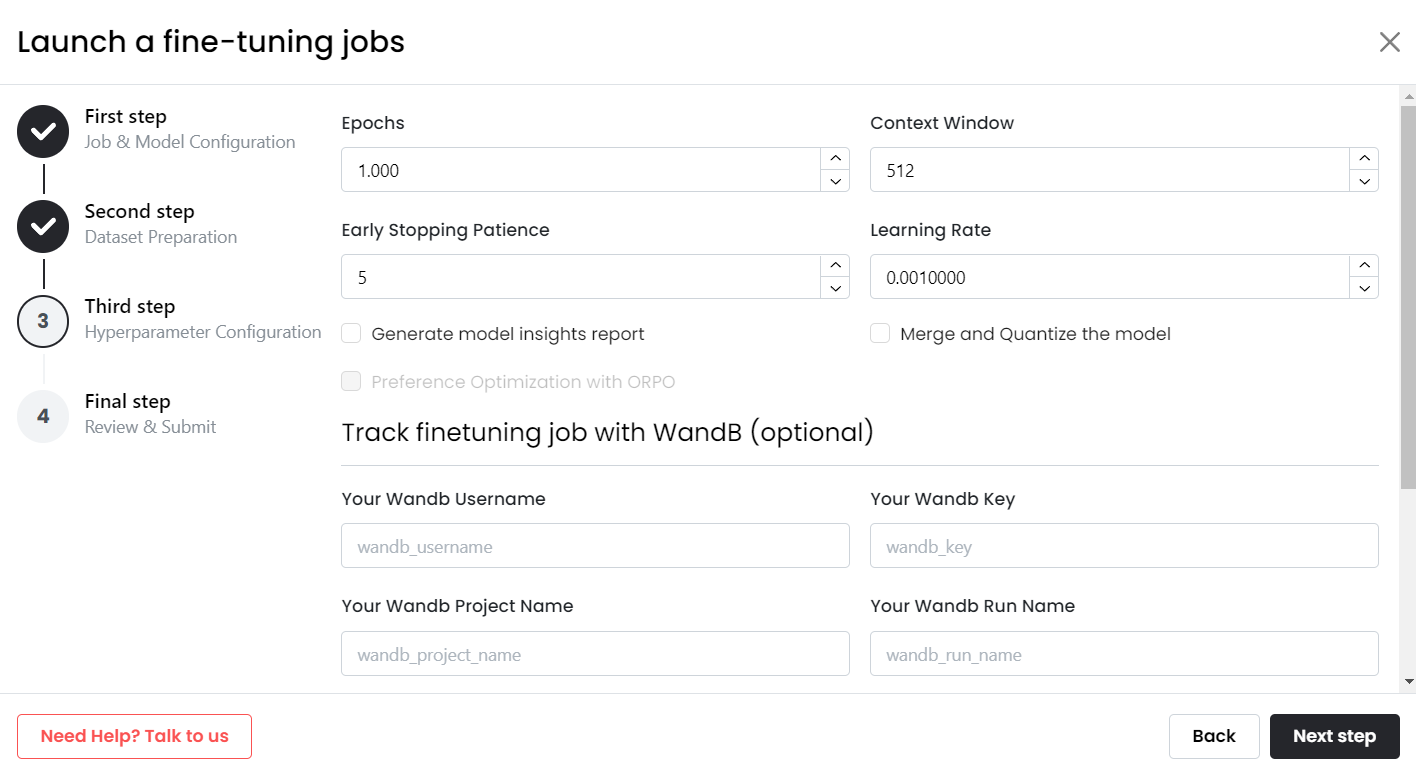
- Review and Submit Finetuning Job
After setting up all the parameters, you can review everything on the summary page. Once you've double checked the details, submit the job. From there, we take care of the rest.
That’s it! In just 3 easy steps, your job is submitted for FineTuning an LLM of your choice. After successfully setting up your fine-tuning job using Monster API, you can monitor the performance through detailed logs on WandB.
Outcome of using MonsterAPI LLM Finetuner:
We were able to fine-tune LLaMA 2 - 7B Base Model on CodeAlpaca-20k Dataset for 5 epochs to develop a Coding Chatbot for as low as $16.
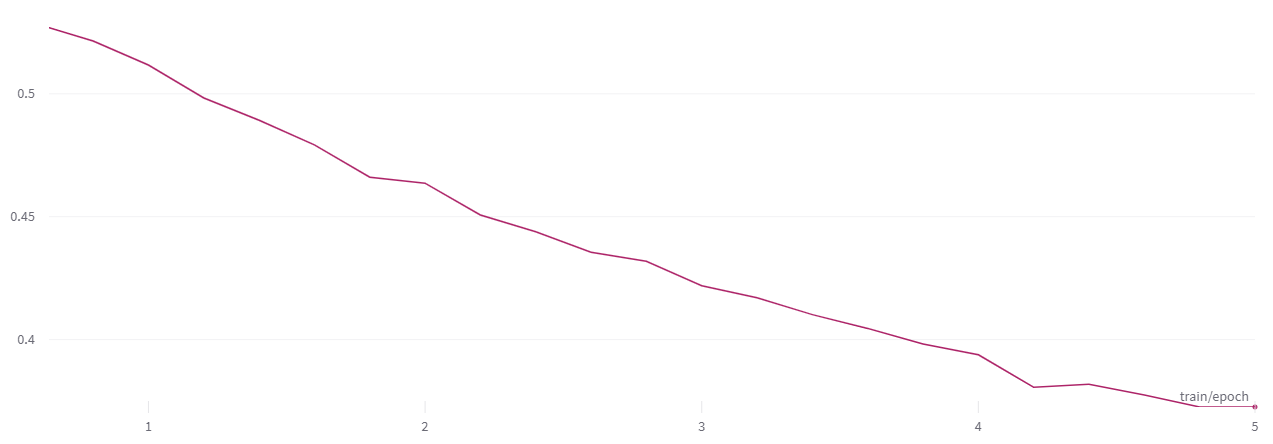
The results of our fine-tuning job turned out to be impressive, as the model learnt and adapted to the chosen task of "Instruction-finetuning" on the specified Code generation dataset. Over 4 hours with 5 epochs, we achieved significant progress. For a visual representation, attached are relevant graphs of our finetuning job using WandB Metrics, showing the training loss and evaluation loss.
Train Loss:
The training loss converged to 0.4583, with the moving average settling at 0.4913. The loss curve illustrates the training progress of the fine-tuned LLM over time. It showcases the decrease in loss values as the model learns and adapts to the dataset.

Evaluation Loss:
These WandB Metrics graphs offer valuable insights into the fine-tuning process, allowing for a detailed analysis of various aspects such as loss, learning rate, GPU power usage, GPU memory access, GPU temperature, etc.
Putting the model to Test -
After successfully fine-tuning the language model using MonsterAPI's LLM FineTuner, it was time to put the model to the test.
We conducted a comprehensive evaluation to assess its performance and suitability for real-world applications. To gain valuable insights, we compared its performance against the base model using the same prompts.
The evaluation included a variety of tasks, ensuring a thorough examination of the fine-tuned model's capabilities.
Input Prompt:
Construct an HTML form with five input fields: Name, Username, Password, Email, and Phone number.

In the HTML form construction task, the fine-tuned model demonstrated enhanced accuracy and context awareness, producing well-structured and error-free forms. The base model, on the other hand, struggled to generate the HTML code.
Input Prompt:
Write a MySQL query to insert new records in an 'Employees' table. Table Name: Employees Records to add: Name: John, Age: 28, Job Title: Programmer Name: Alice, Age: 24, Job Title: Designer

Similarly, when tasked with writing MySQL queries for record insertion, the fine-tuned model showcased remarkable proficiency in generating syntactically correct queries tailored to the provided data. In comparison, the base model produced queries with incomplete syntax.
The fine-tuned model's ability to understand the nuances of coding tasks and thus provide accurate and contextually relevant outputs showcased the benefits of fine-tuning language models.
Download the Fine-Tuned Model weights from Hugging Face
Cost Analysis of Finetuning Llama 2 on MonsterAPI:
The fine-tuning process through MonsterAPI's LLM FineTuner is incredibly streamlined and cost-effective. With just a few clicks to set up and configure, your job is ready to go in less than 30 seconds, all at a budget-friendly cost of just $16.
In comparison, replicating a similar experiment on 3xV100s on a traditional cloud could cost close to $40, alongside demanding significant setup time and manual effort from the developer. Our approach ensures you can achieve exceptional results without unnecessary financial burden.
With Monster API, the entire fine-tuning experience becomes 2.5 X more cost-effective compared to traditional cloud options. The savings you experience with Monster API will significantly increase as you scale, allowing you to achieve exceptional results without the unnecessary financial burden.
The Benefits of using MonsterAPI LLM finetuner:
The true value of our no-code LLM FineTuner lies in its dedication to simplifying and democratizing the use of large language models (LLMs).
By addressing common barriers like technical complexities, memory constraints, high GPU costs, and lack of standardized practices, our platform makes AI model fine-tuning accessible and efficient for all.
In doing so, it empowers developers to fully leverage LLMs, fostering the development of more sophisticated AI applications.
Ready to finetune an LLM for your business needs?
Sign up on MonsterAPI to get free credits and try out our no-code LLM Finetuning solution today!
For more details, check out the LLM Fine-tuning documentation Finetuning an LLM.