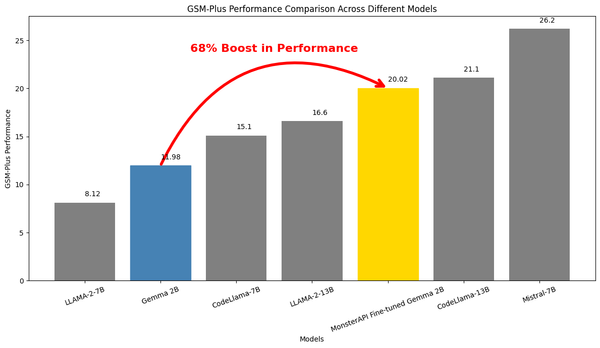
In this case study, we explore how a smaller, fine-tuned model like Gemma-2B can perform better than larger models while being far more efficient and fast. Using MonsterAPI's No-Code LLM fine-tuner - MonsterTuner, we finetuned Gemma-2B specifically for mathematical reasoning tasks, and we achieved a 68% performance boost over the