
Gemma-2B LLM fine tuned on MonsterAPI outperforms LLaMA 13B on Maths reasoning

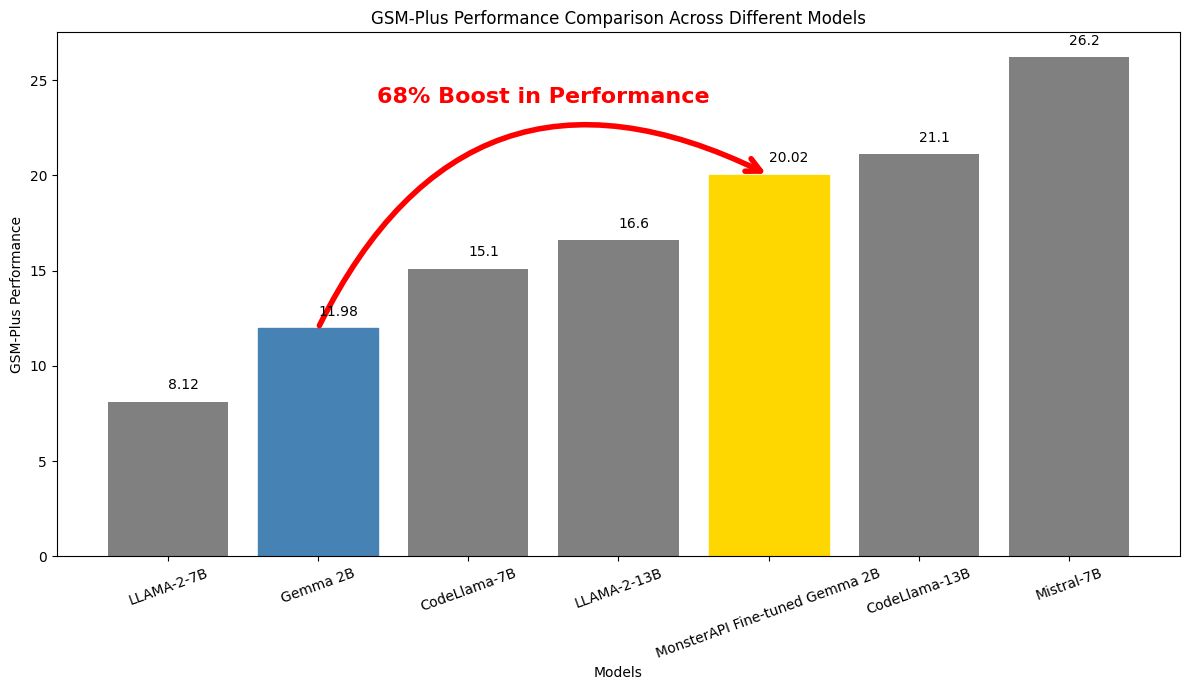
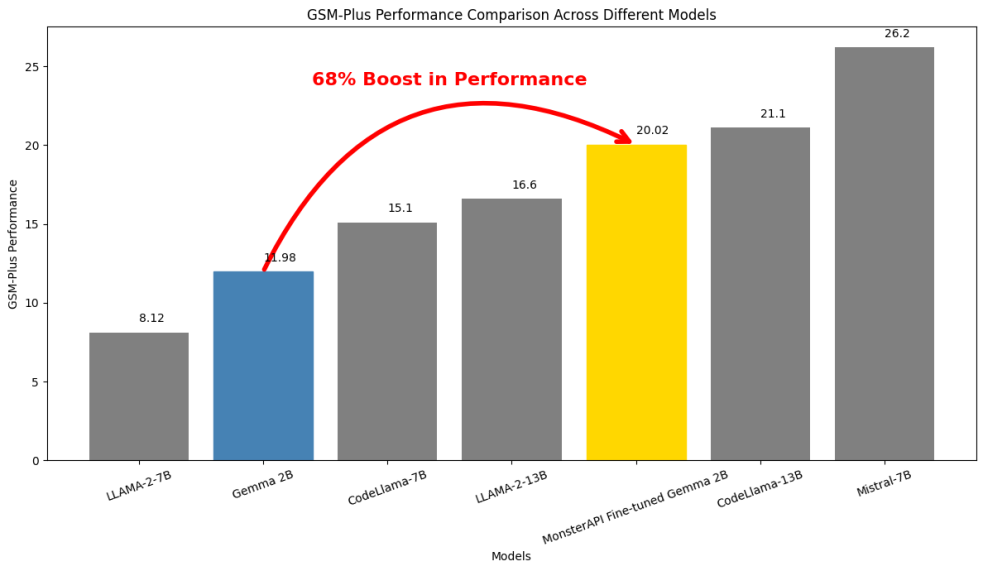
In this case study, we explore how a smaller, fine-tuned model like Gemma-2B can perform better than larger models while being far more efficient and fast. Using MonsterAPI's No-Code LLM fine-tuner - MonsterTuner, we finetuned Gemma-2B specifically for mathematical reasoning tasks, and we achieved a 68% performance boost over the base model. Here's a rundown:
But First, Meet Gemma
Gemma, a family of lightweight, state-of-the-art open models from Google, has garnered attention for its performance in various LLM tasks. In this study, we evaluate their performance on the challenging GSM Plus benchmark, which systematically assesses mathematical reasoning capabilities.
Fine-tuning Process
Gemma-2B underwent fine-tuning on the Microsoft/Orca-Math-Word-Problems-200K dataset for 10 epochs using MonsterAPI's MonsterTuner service. This process aimed to optimize Gemma-2B's capabilities specifically for mathematical problem-solving tasks.
Why GSM Plus Benchmark matters?
The GSM Benchmark rigorously tests Large Language Models' (LLMs) proficiency in addressing grade school mathematics, providing a robust framework for evaluating their capacity for mathematical reasoning and problem-solving. This benchmark not only gauges a model's ability to find correct solutions but also serves as a benchmark for comparing the mathematical intellect across diverse models, establishing a high standard for computational understanding and application in educational contexts.
Benchmarking Performance on GSM Plus
The performance of Gemma-2B and the standard Gemma model was evaluated on the GSM Plus benchmark, which assesses mathematical reasoning through various perspectives:
Score Achievement: Gemma-2B achieved a remarkable score of 20.02 on the GSM Plus benchmark.
- This represents a 68% improvement over its baseline model performance.
- Notably, it outperformed larger models like LLaMA-2-13B and Code-LLaMA-7B
This result suggests that targeted fine-tuning can lead to significant improvements in model performance.

Gemma-2B exhibited higher accuracy in numerical variation, arithmetic variation, problem understanding, distractor insertion, and critical thinking, highlighting its superior proficiency in mathematical reasoning tasks.
Key Takeaways
- Gemma-2B for my real-time applications?
Gemma-2B excels in combining high performance with efficiency, making it a standout choice for applications where inference speed is crucial. Its ability to deliver quick and accurate results without the heavy computational load of larger models makes it ideal for real-time processing.
- Can smaller models outperform larger ones?
Absolutely, smaller models like Gemma-2B can outshine larger ones when fine-tuned for specific tasks. Gemma-2B demonstrates this by leading in mathematical reasoning, thanks to focused optimization.
- Implications for NLP practitioners?
Gemma-2B's success highlights the essential role of fine-tuning in enhancing model performance. It proves that targeted fine-tuning can significantly boost efficiency and accuracy in mathematical problem-solving tasks.
Replicate this Experiment yourself
- How to finetune a LLM and deploy it - [Complete Blog]
- How to finetune a Large Language Model - [Detailed Guide]
- How to deploy a Large Language Model - [Easy Guide]
Conclusion
This case study reveals that fine-tuning a model like Gemma-2B for a specific task can yield impressive results, rivaling or even surpassing larger models. It's a compelling example of how targeted optimization can make the most of a model's capabilities.