
RAG vs Fine-Tuning: Choosing the Right Approach for Your LLM
RAG involves combining information retrieval with generative language models. Fine-tuning includes training a pre-trained LLM on a specific dataset to suit a particular task. Here's when to use RAG vs Fine-tuning.

Large Language Models (LLMs) have revolutionized the field of natural language processing, but their effectiveness is heavily reliant on the underlying approach used to adapt them to specific tasks or domains.
Two prominent methods for tailoring LLMs are Retrieval-Augmented Generation (RAG) and fine-tuning. While both aim to enhance model performance, they differ significantly in their methodologies, strengths, and weaknesses.
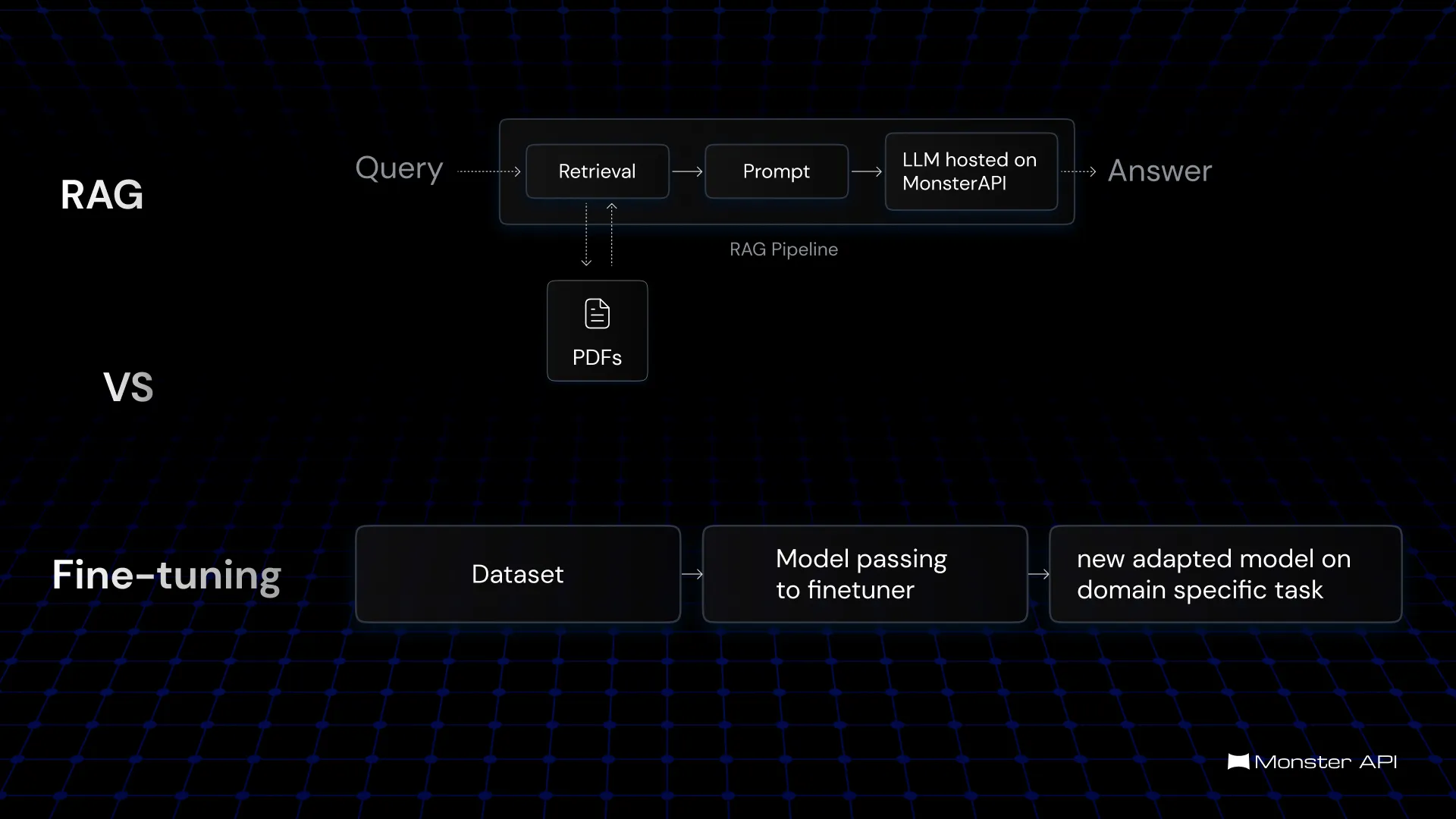
Retrieval-Augmented Generation (RAG) involves combining information retrieval with generative language models. This approach leverages a search engine or database to retrieve relevant information based on a user query. The retrieved information is then provided as context to the LLM, which generates a response. RAG excels in handling dynamic data environments where information changes frequently.
Fine-tuning involves training a pre-trained LLM on a specific dataset to adapt its behavior to a particular task or domain. This process adjusts the model's parameters to align with the desired output. Fine-tuning is effective for static datasets and allows for greater customization of the model's behavior.
When to Use RAG vs Fine-Tuning
- Retrieval-augmented generation (RAG) combines retrieval and generative techniques to build conversational agents with exceptional capabilities.
- RAG systems can access and process information from vast document repositories while maintaining a natural conversational flow.
- RAG is not possible without fine-tuning, as the models used are instruction-tuned variants of existing foundational models.
- Fine-tuning enables the LLM to decipher and execute user instructions across diverse tasks.
- This is particularly advantageous for conversational agents designed to navigate heterogeneous document classes while retaining a memory-backed, natural dialogue.
- Fine-tuning LLMs on extensive and varied datasets can present challenges, including insufficient dataset size or scope, which can degrade performance.
- Fine-tuning is especially effective for specializing the LLM in a particular domain, such as coding or instruction following.
- Fine-tuning can transform a versatile but generic LLM into a domain-specific powerhouse, adept at handling specific tasks.
- Fine-tuning can also enable a basic text-generation model to comprehend and follow instructions, making it ideal for conversational agents.
- During RAG, the LLM typically receives a large prompt, with over 80% of the prompt consisting of retrieved-context and the rest being instructions.
- Large prompts can significantly delay generation time and increase application costs.
- Fine-tuning is preferred in cases where it is possible to avoid the drawbacks of large prompts in RAG.
Hybrid Approaches
It's important to note that RAG and fine-tuning are not mutually exclusive. In many cases, a hybrid approach combining both techniques can yield optimal results. For example, you could use RAG to retrieve relevant information and then fine-tune a smaller model on this retrieved data for specific tasks.
Ultimately, the best approach depends on the specific requirements of your application. By carefully considering the factors outlined in this blog, you can choose the best method for enhancing your LLM's capabilities.
RAG with MonsterAPI
MonsterAPI has integration with both LlamaIndex and Haystack now let us see how we can do RAG using monster API and LlamaIndex:
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.monsterapi import MonsterLLM
## Step 1: Data Indexing with LlamaIndex
### Load and prepare data sources (PDFs, HTML, etc.)
documents = SimpleDirectoryReader('path_to_your_data').load_data()
### Chunk data into manageable segments
nodes = SentenceSplitter().split(documents)
### Create an index by converting chunks into vectors
index = VectorStoreIndex.from_documents(nodes)
## Step 2: Setting Up Retrieval with LlamaIndex
### Initialize the MonsterLLM for text generation
llm = MonsterLLM(model_name="your_model_name_here")
### Encode and query to retrieve top-matching document chunks
query_text = "Explain Retrieval-Augmented Generation"
response = llm.query(query_text)
print(response)
## Step 3: Generating Responses with MonsterLLM
### Combine query and retrieved context into a prompt
prompt = "Explain the concept of Retrieval-Augmented Generation."
### Generate a response using the augmented context
response = llm.complete(prompt)
print(response)
Fine-Tuning with MonsterAPI
Here is how you can simply fine-tune a large language model on a dataset of your own choice using monster API:
## API endpoint for fine-tuning
url = "https://api.monsterapi.ai/v1/finetune/llm"
## Payload configuration for fine-tuning the model
payload = {
"deployment_name": "OpenELM_fine_tuning", # Name for the deployment
"pretrainedmodel_config": { # Configuration for the pre-trained model
"model_path": "apple/OpenELM-450M", # Path to the pre-trained model
"use_lora": True, # Use LoRA for fine-tuning
"lora_r": 8, # LoRA rank
"lora_alpha": 16, # LoRA scaling factor
"lora_dropout": 0, # Dropout rate for LoRA
"lora_bias": "none", # Bias configuration for LoRA
"use_quantization": False, # Whether to use quantization
"use_unsloth": False, # Option to use unsloth
"use_gradient_checkpointing": False, # Gradient checkpointing for memory efficiency
"parallelization": "nmp" # Type of parallelization
},
"data_config": { # Configuration for the dataset
"data_path": "tatsu-lab/alpaca", # Path to the dataset
"data_subset": "default", # Subset of the dataset to use
"data_source_type": "hub_link", # Type of data source
"prompt_template": "Here is an example on how to use tatsu-lab/alpaca dataset ### Input: {instruction} ### Output: {output}", # Prompt template for data
"cutoff_len": 512, # Maximum length of the input sequence
"prevalidated": False # Whether the data is prevalidated
},
"training_config": { # Training configuration
"early_stopping_patience": 5, # Patience for early stopping
"num_train_epochs": 1, # Number of training epochs
"gradient_accumulation_steps": 1, # Steps for gradient accumulation
"warmup_steps": 50, # Warmup steps for learning rate scheduler
"learning_rate": 0.001, # Learning rate
"lr_scheduler_type": "reduce_lr_on_plateau", # Type of learning rate scheduler
"group_by_length": False # Whether to group data by length
},
"logging_config": { "use_wandb": False }, # Logging configuration
"hf_config": { "hf_token": "<HF TOKEN>" }, # Hugging Face token for authentication
"accessorytasks_config": { # Additional tasks configuration
"run_eval_report": False, # Whether to run evaluation report
"run_quantize_merge": False # Whether to run quantize and merge
}
}
### Headers for the API request
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer <MONSTER API TOKEN>"
}
### Send a POST request to the API to start fine-tuning
response = requests.post(url, json=payload, headers=headers)
### Print the response from the API
print(response.text)
Final Take
To sum it up RAG and Fine-Tuning have their unique usages but they overlap quite a bit RAG being dependent on fine-tuning. RAG is widely used for building chatbots over private knowledge sources provided you have a good enough fine-tuned model to answer user queries.
The important thing to note is that RAG is not centered around LLM they are rather centered around retrieval; the success of RAG is directly proportional to the success of your retrieval step.
Fine-tuning is widely adapted to instruction tuning, code generation, and domain adaptation tasks. RAG is a method that emerged out of fine-tuning where we don't have to worry about the generation which has been taken care of by fine-tuning prior.
If your use case doesn’t care about generation but rather about the factual correctness of the generation RAG is the way to go. If you wish to fundamentally adapt a model to a new task, fine-tuning is the way to go.