
Build a Retrieval-Augmented Generation ChatBot in 10 Minutes using MonsterAPI


Retrieval Augmented Generation (RAG) is a technique that generates answers to pre-existing queries by combining pre-established rules or parameters (non-parametric memory) with external data from the internet (parametric memory).
By responding in natural language conversations with contextually relevant responses, RAG bots are revolutionizing user interactions. We'll dive into the realm of RAG bots in this blog, explaining what they are and how to use MonsterAPI to quickly and easily create one in a matter of minutes.

Pipeline for developing a RAG Bot from Scratch
Building a RAG bot from scratch involves a multi-step process:
- Large Language Model (LLM) Deployment: To start, set up an LLM API endpoint on GPU instances which can be a time-consuming and complex process. Also setting up GPU infrastructure and preparing the environment for model deployment are two tasks that demand experience.
Example: Steps of deploying a model on a cloud like AWS.
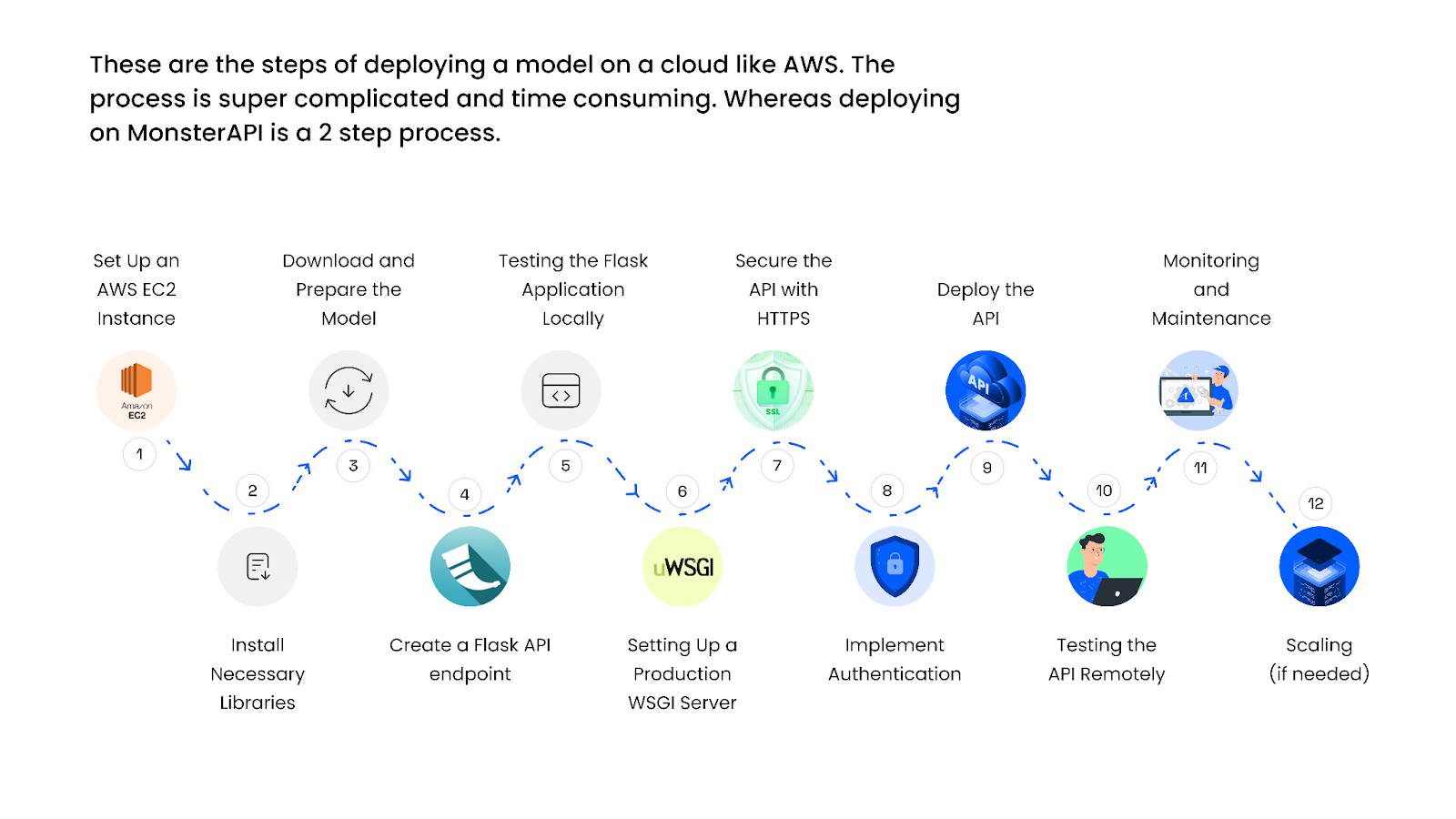
- Scaling Configuration: Put in place a scaling configuration to manage variations in user demand. To guarantee peak performance, load balancers, and auto-scaling policies may need to be configured.
- Llama Index Integration: For effective data retrieval, integrate with Llama Index or any other RAG system/framework to enable efficient context retrieval and chunking of large context for LLMs with limited context windows. This entails configuring indexing systems and establishing linkages to data sources to facilitate easy access to relevant data.
- Establish a chat user interface (UI) to help users communicate with the bot. This could entail using APIs to integrate with already-existing chat systems or creating a unique chat experience.
Building a RAG Bot with MonsterAPI:
Building a RAG bot with MonsterAPI streamlines the development process with the following steps:
- Incorporation of Monster Deploy: To easily deploy an LLM, use Monster Deploy. Simply select your desired LLM, click 'deploy' on your MonsterAPI Deploy dashboard, and you'll have an LLM API endpoint ready to handle queries within moments. Once deployed, you'll receive an authentication token and URL to access the LLM endpoints seamlessly. This one-click Deploy solution from MonsterAPI streamlines the deployment process, offering optimized API endpoints for enhanced throughput at a reduced cost.
- Llama Index Integration: MonsterDeploy's integration with LlamaIndex provides direct access to your deployed LLMs within the LlamaIndex framework. This seamless integration optimizes data loading and indexing, allowing efficient parsing of large document contexts. The system then sends this context to query your deployed LLM endpoints, ensuring seamless data retrieval and indexing, ultimately enhancing the performance of your bots.
- Chat UI Integration: Supply the URL and auth token of your deployed LLM in our Chainlit chat UI for immediate use.
MonsterAPI simplifies the integration of LLM deployment with RAG integration and chat User interface, allowing for seamless user interaction without the need for setting up complex UI and RAG systems.

Advantages of Deploying a Private LLM Endpoint with MonsterAPI:
Deploying a private LLM endpoint with MonsterAPI offers numerous advantages:
- Enhanced Security: Keep your model and data secure within your private endpoint, accessible only through your deployment’s auth key.
- Cost-Effectiveness: MonsterAPI provides cost-effective solutions for deploying and managing LLMs by integrating our affordable GPU cloud optimised for higher throughput, thus reducing infrastructure costs.
- Scalability: Your LLM deployments automatically scale bi-directionally on demand, ensuring optimal performance during peak usage.
- Customization: Tailor your LLM deployment to specific requirements, including GPU and RAM configurations, to optimize performance, costs and resource utilization.
- Advanced Monitoring: Gain insights into LLM performance and usage metrics with MonsterAPI's comprehensive monitoring and analytics features.
- Fine-tuned LLM Deployments: Monster Deploy enables you to deploy fine-tuned LLMs as API endpoints. Thus reducing the need to set up complex custom pipelines for fine-tuning and deploying LLMs at scale.
Here is a Step-by-Step Guide:
Step 1: Sign up for a Monster API account and create an LLM deployment using their one-click solution “MonsterDeploy”
Step 2: Once the deployment is live, copy the endpoint URL and authentication key
Step 3: Paste these values into ChainLit's interface to set up your chat UI and then you are good to go.
Conclusion:
Building a RAG bot has never been easier, thanks to MonsterAPI's robust platform. With just a few simple steps, you can deploy your own RAG bot in a matter of minutes.
Sign up for MonsterAPI today and unleash the power of conversational AI in your applications.