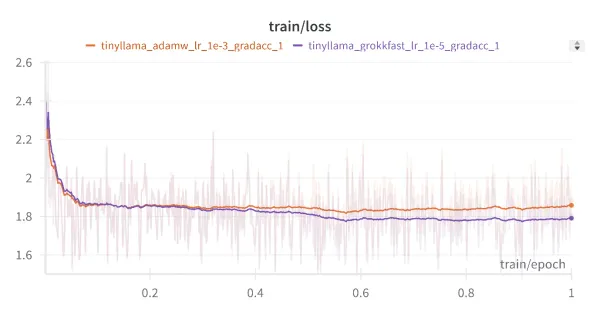
Serving large language models (LLMs) in production environments poses significant challenges, including high memory consumption, latency issues, and the need for efficient resource management. These challenges often result in suboptimal performance and scalability problems, hindering the deployment of LLMs in real-world applications.
vLLM addresses these challenges by optimizing memory management