
Unsloth & SDPA Integrated in MonsterAPI for 2x LLM Finetuning Performance Boost

Finetuning LLMs to fit your business use case is crucial for building powerful Generative AI applications. Whether you’re developing a ChatGPT alternative or Chatbot for customer support or an email copywriting AI model, finetuning plays a critical role in improving the performance and quality for your specific application needs.
However, there are a lot of limitations that plague the LLM finetuning process. At MonsterAPI, we’re making LLM finetuning easier and more accessible for everyone with our no-code LLM finetuner with in-built optimizations for faster processing with Flash Attention 2, LoRA/QLoRA auto-configuration and optimized GPU deployments for cost reduction.
We’ve taken it one step further by integrating Unsloth and SDPA within MonsterTuner to speed up the finetuning process and increase the context length for supported LLMs.
In this case study, we’ll highlight the performance boost and context length improvements in LLMs using Unsloth and SDPA integration.
What is Unsloth?
Unsloth is an innovative approach designed to combat the inefficiencies and redundancies often present in large language models.
The term "sloth" metaphorically refers to the slow and redundant processes that can plague machine learning models, leading to suboptimal performance and increased computational costs.
Unsloth, therefore, aims to streamline these processes, making models faster, more efficient, and less resource-intensive.
Benefits of using UnSloth in LLM Fine-tuning:
1. Enhanced Efficiency: By removing redundant computations and optimizing data flow, Unsloth significantly improves the efficiency of LLMs. This leads to faster response times and reduced latency, crucial for real-time applications such as chatbots and virtual assistants.
2. Reduced Computational Costs: Training and fine-tuning LLMs require substantial computational resources. Unsloth helps reduce these costs by minimizing unnecessary operations and lowering energy consumption and hardware requirements.
3. Improved Model Performance: Unsloth enhances the performance of LLMs by ensuring that the models focus on relevant information, leading to more accurate and contextually appropriate outputs. This is particularly important in applications where precision and reliability are critical.
4. Scalability: As the size and complexity of LLMs grow, integrating Unsloth becomes essential for maintaining scalability. By optimizing the underlying processes, Unsloth allows for smoother scaling of models without proportional increases in computational demands.
MonsterAPI x Unsloth:
To boost the performance of LLMs during the fine-tuning process, we’ve integrated Unsloth into our solution. This means that Unsloth will be automatically enabled for the models it supports such as the LLaMa Series of models
We’ve fine-tuned some of the latest models with and without Unsloth to highlight the difference in performance.
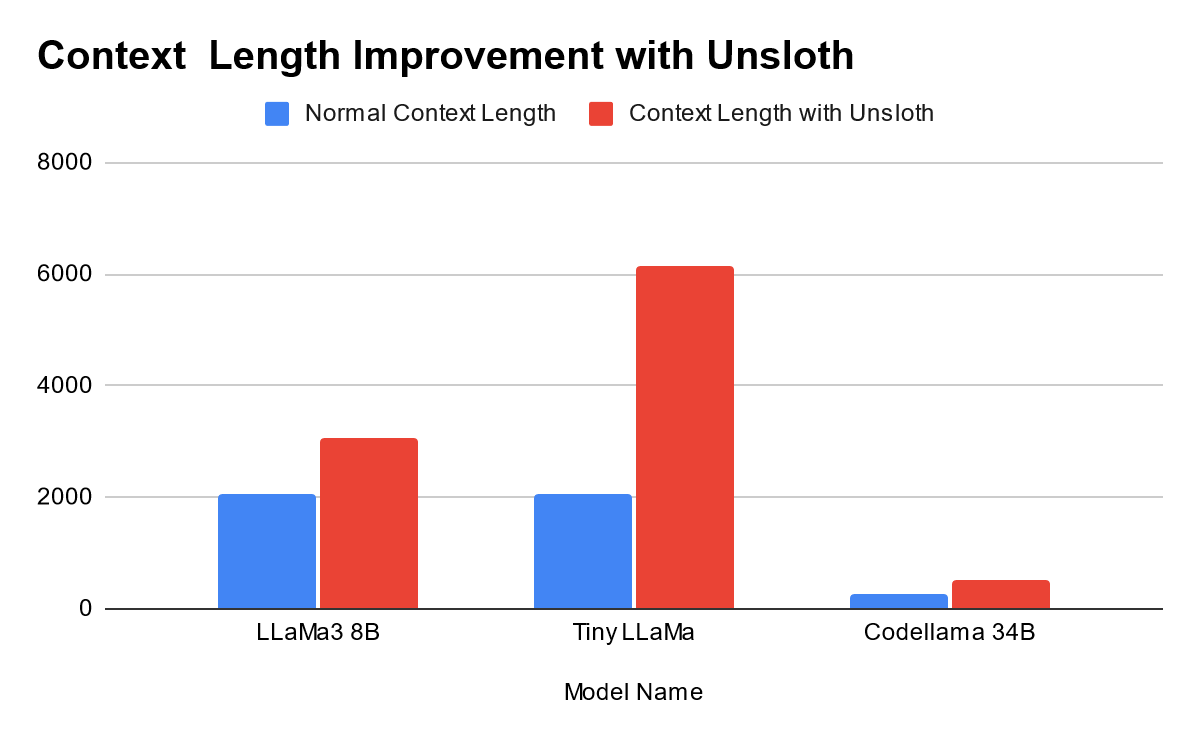
- LLaMa3 8B
- Normal max context length supported - 2048
- Max context length supported with Unsloth - 3072
- Tiny LLaMa
- Normal context length supported - 2048
- Tiny LLaMa context length with Unsloth - 6144
- Codellama 34B
- Normal context length supported - 256
- Max context length supported with Unsloth - 512
Improved Performance of LLMs Using Unsloth
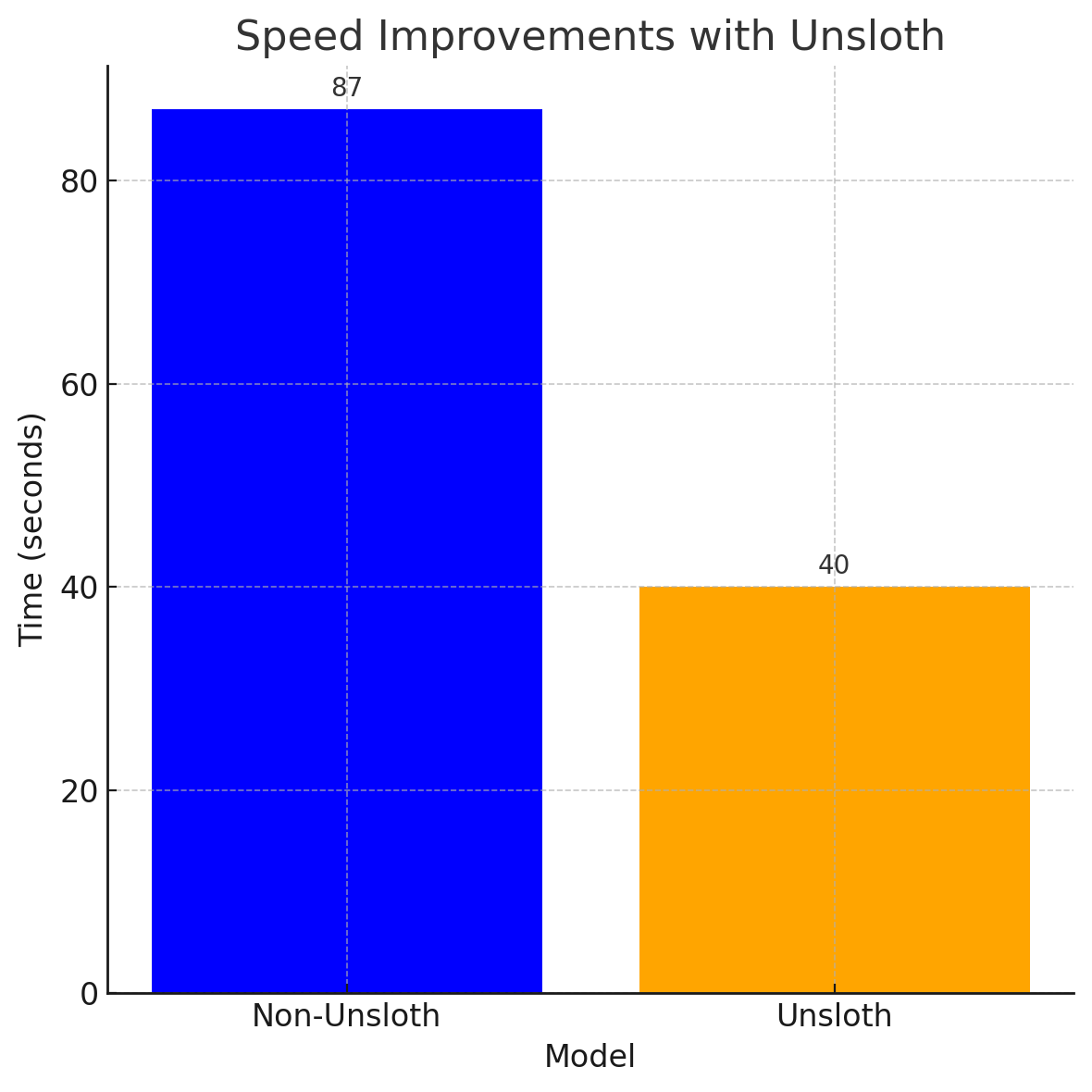
Also, with UnSloth we have seen good speed improvements with the larger models. The non-Unsloth variant takes 87 seconds to complete the benchmark test. While the Unsloth-optimized one can do it in 40 sec. A 100%+ improvement
What is SDPA?
SDPA (Scaled Dot-Product Attention), is a key component of Transformer models in NLP(natural language processing). It computes attention scores between queries and key-value pairs, scales them, and produces a weighted sum of values.
This mechanism allows models to dynamically focus on different parts of the input sequence, enhancing their ability to understand context and relationships within the data.
Benefits of Using SDPA in LLM Finetuning
Using Scaled Dot-Product Attention (SDPA) in Large Language Model (LLM) fine-tuning offers several benefits that enhance the model's performance and adaptability. Here are the key benefits:
- Efficient Computation
The scaling factor in SDPA prevents the dot products from growing too large and helps maintain stable gradients.
( \sqrt{d_k} )
This leads to more efficient and stable training, especially when dealing with large-dimensional data.
- Improved Focus
SDPA enables the model to focus on the most relevant parts of the input sequence by computing attention scores that highlight important tokens. This selective attention mechanism helps the model prioritize essential information, leading to better performance on specific tasks.
- Parallelization and Speed
SDPA allows for parallel computation of attention scores for all tokens in the sequence, making it computationally efficient and faster compared to sequential processing methods. This is crucial for handling large datasets and long sequences typical in LLM tasks.
- Enhanced Representation Learning
SDPA is used in conjunction with multi-head attention mechanisms, which enable the model to learn different representation subspaces. This multi-faceted approach captures diverse aspects of the input data, improving the richness and quality of the learned representations.
- Scalability
SDPA scales well with the size of the model. As models become larger and more complex, the ability to efficiently compute and apply attention across many heads and layers becomes increasingly important.
- Better Handling of Long-Range Dependencies
Unlike traditional RNNs that struggle with long-range dependencies due to vanishing gradient issues, SDPA can directly relate tokens regardless of their distance in the sequence. This ability to model long-range dependencies is crucial for tasks that require understanding context spread across long text segments.
MonsterAPI x SDPA:
To further enhance the context length and performance speed ups during the LLM fine-tuning process, we have integrated SDPA in Monster Tuner. SDPA would be automatically enabled for all models that are not supported by Flash Attention 2.
Improved LLM Performance with SDPA
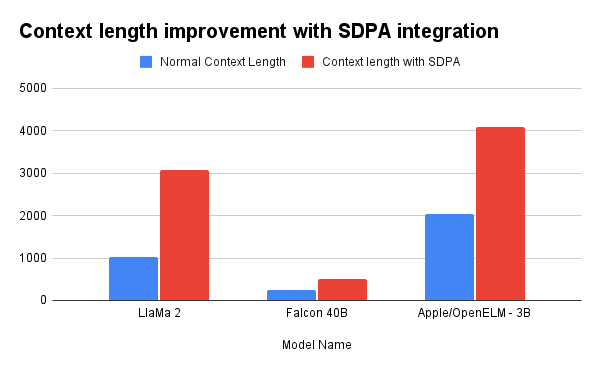
- LlaMa 2
- Max context length without SDPA - 1024
- Max context length with SDPA - 3072
- Falcon 40B
- Max context length without SDPA - 256
- Max context length with SDPA - 512
- Apple/OpenELM-3B
- Max context length without SDPA - 2048
- Max context length with SDPA - 4096
Note:
All the experiments have been performed with a 40 GB variant of A100. The results may vary when running on different GPUs, with even the scope of bigger context length support on bigger GPUs like A6000 and A100 80GB.
Conclusion:
By addressing the inefficiencies inherent in large models, Unsloth & SDPA not only enhances performance and reduces costs but also paves the way for more accessible, sustainable, and innovative AI technologies. Integrating Unsloth and SDPA in LLM finetuning workflow delivers a significant enhancement in performance speed and context length for bigger use cases where more tokens are required for the context. This makes Monster Tuner even more capable of supporting enterprise use cases for building and deploying custom and efficient Large language models.
FAQs
- What is Unsloth?
Unsloth is a method designed to enhance the efficiency of Language Learning Models (LLMs) by reducing computational latency and improving processing speed. It achieves this by optimizing various internal mechanisms of the model, such as token handling and parallel processing.
- What is SDPA?
SDPA stands for Scaled Dot-Product Attention, a core component in transformer-based models. SDPA is used to calculate attention scores, which help the model focus on relevant parts of the input sequence when generating predictions.
- What are the key benefits of using Unsloth?
The key benefits of using Unsloth include:
- Reduced latency and faster response times.
- Improved overall efficiency of LLM operations.
- Enhanced ability to handle larger datasets and more complex queries.