
How to Finetune Whisper for Speech-to-Text Transcription
Whisper Fine-tuning for speech-to-text transcription can be complicated if you don't know what to do. Use MonsterAPI's fine-tuning & deployment pipeline to streamline the process.


Speech-to-text transcription has grown increasingly popular, enabling users to convert spoken language into written text for accessibility, subtitles, content creation, and more. OpenAI’s Whisper is one of the leading models for this task, but it can be made even more effective through fine-tuning, allowing it to perform better in specific domains, accents, or environments.
In this blog, we'll guide you through the process of fine-tuning Whisper for your specific transcription needs, utilizing the MonsterAPI Fine-tuner to streamline the process.
Step-by-Step Guide to Fine-tuning Whisper
- Prepare Your Dataset
- To fine-tune Whisper, you’ll need a well-prepared dataset consisting of paired audio and corresponding transcripts. MonsterAPI supports an easy-to-use dataset preparation interface.
- Visit the dataset preparation guide to understand the required format and best practices for creating a high-quality dataset for fine tuning.
- Make sure your dataset is clean, properly labeled, and includes diverse audio samples matching your use case (such, various accents, speakers, or environments).
- Access the Fine-tuning Section on MonsterAPI
- Sign in to your MonsterAPI account and navigate to the fine-tuning section.
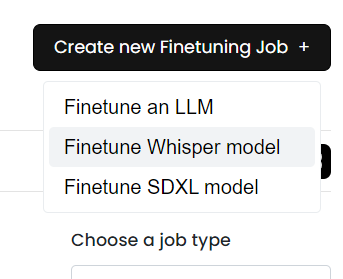
- Click on "Create New Fine-tuning Job" and select Finetune Whisper model.
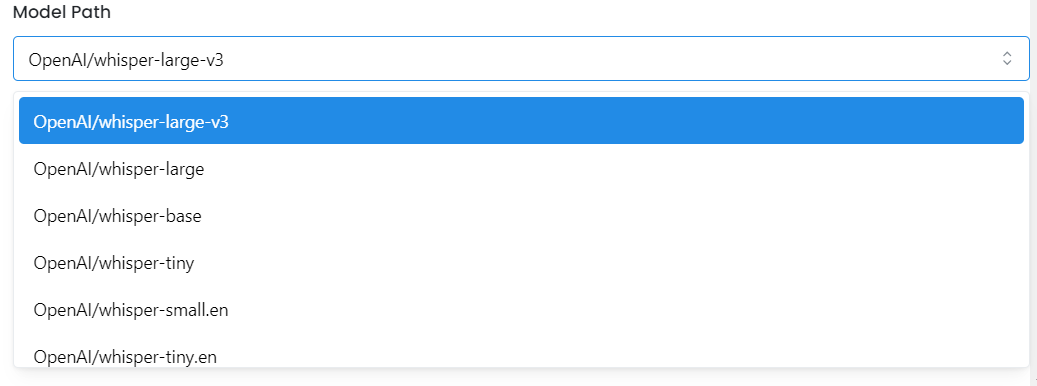
- Choose your model path from all the models available for fine-tuning. MonsterAPI offers over 14 Whisper models, allowing you to select the one that best fits your task.
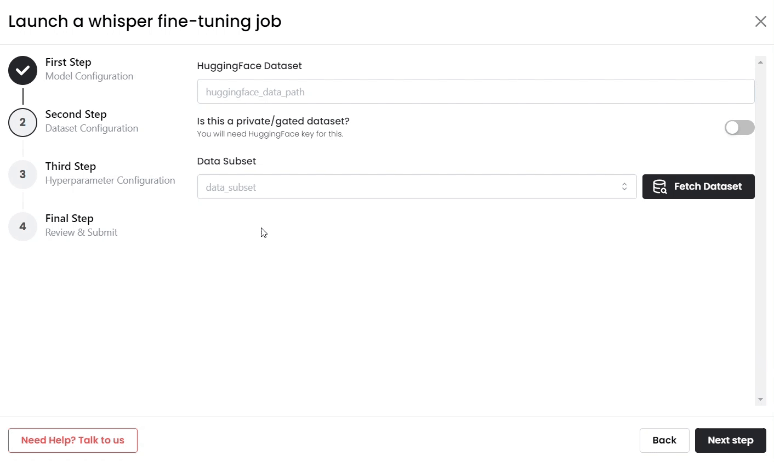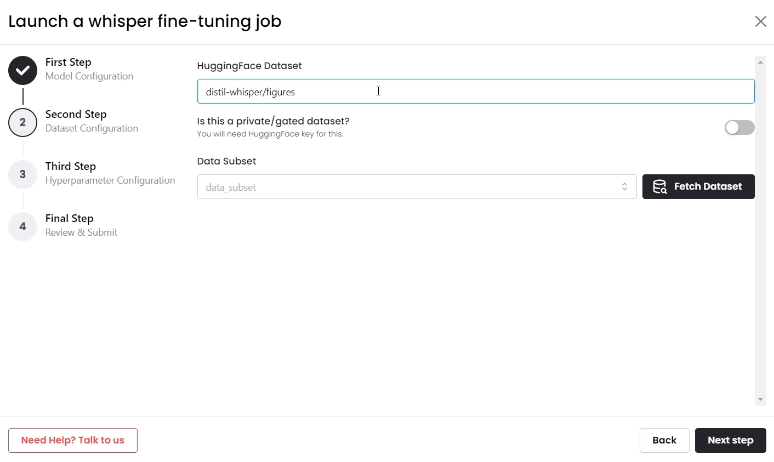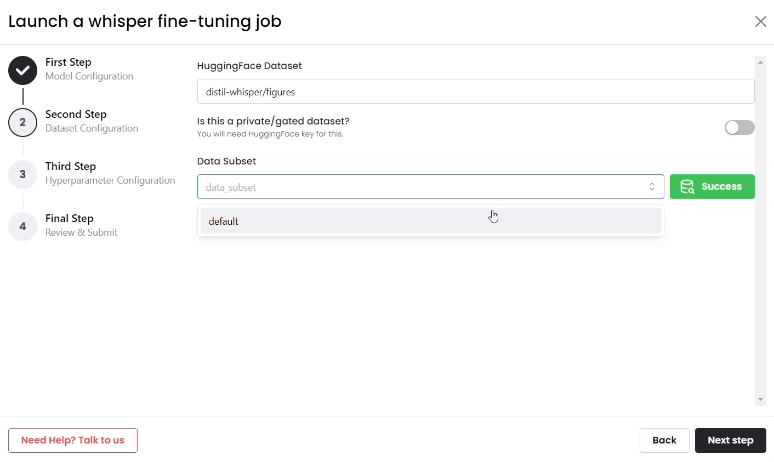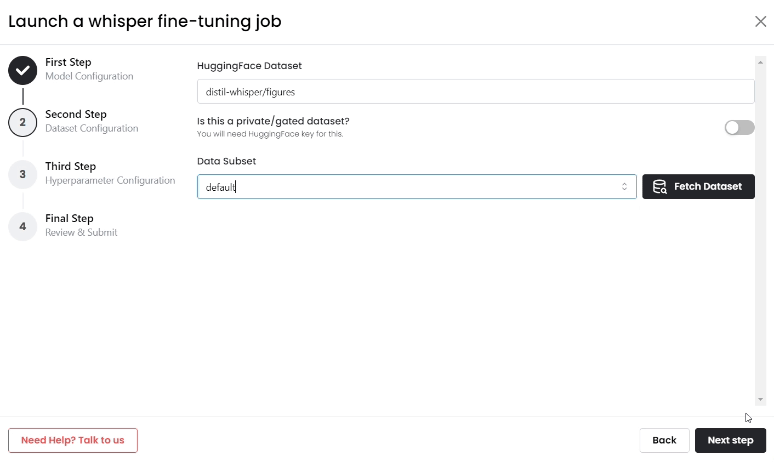
- Upload Your Dataset
- Upload the Hugging Face dataset, click on "Fetch Dataset," and then choose the dataset subset for fine-tuning.
- Configure Fine-tuning Settings
- Choose your training parameters, such as epochs, learning rate, and max length. If you’re unsure, MonsterAPI provides recommendations for optimal configurations based on your dataset size and computational resources.
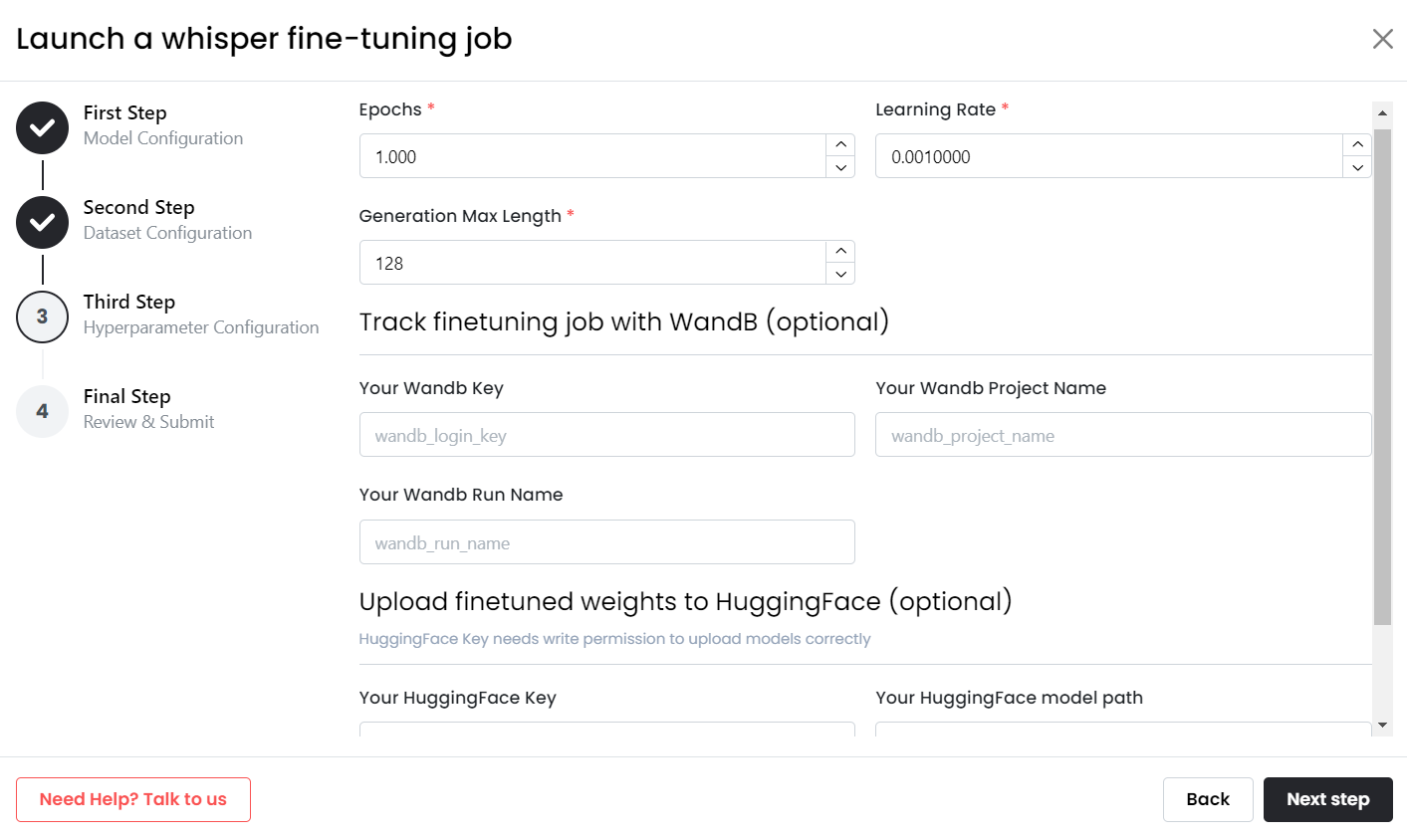
- MonsterAPI also allows you to monitor training progress, providing detailed logs and alerts to help you track performance during the fine-tuning process.
For more details, check the Whisper fine-tuning guide.
- Start the Fine-tuning Process
- Once you have set your hyperparameters, click "Next" and review your configuration to start fine-tuning.
- The process can take some time after you submit it, depending on the size of your dataset and the parameters you choose. MonsterAPI uses its robust infrastructure to ensure that fine-tuning jobs are completed efficiently.
Conclusion
Whisper's speech-to-text transcription performance can be significantly improved by fine-tuning it for specialized domains, accents, or audio environments. MonsterAPI makes the entire process seamless, from dataset preparation to model fine-tuning and deployment. Whether you are transcribing interviews, podcasts, or industry-specific jargon, MonsterAPI allows you to easily customize Whisper and deploy it at scale.
Begin fine-tuning Whisper today to unleash the power of a personalized transcription model tailored to your specific requirements.