
Using ORPO to Improve LLM Fine-tuning with MonsterAPI
ORPO is an innovative algorithm that simplifies the LLM fine-tuning process by directly integrating preference alignment into a single-step supervised fine-tuning. Here's how you can fine-tune LLMs with ORPO using MonsterAPI.

Fine-tuning large language models (LLMs) to align with user preferences is crucial for enhancing their performance and usability. Traditional methods like Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO) have been employed to ensure models generate desirable responses. However, these methods often involve complex, multi-stage processes that can be resource-intensive.
Enter ORPO (Odds Ratio Preference Optimization), an innovative algorithm simplifying the fine-tuning process by directly integrating preference alignment into a single-step supervised fine-tuning. In this discussion, we will explore how ORPO can be a crucial advantage in LLM fine-tuning and how its integration into MonsterAPI’s LLM Fine-tuner enhances LLM fine-tuning performance, making the process more efficient and effective.
Understanding ORPO
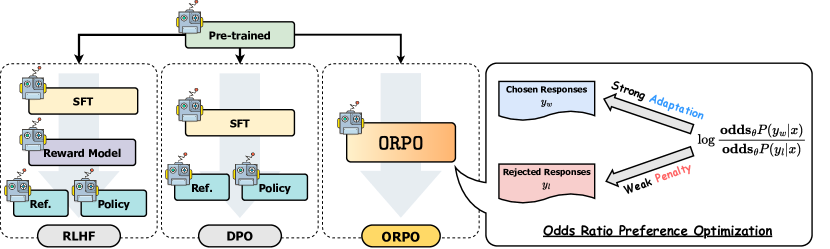
ORPO is a preference optimization technique that incorporates an odds ratio-based penalty into the conventional negative log-likelihood (NLL) loss function during supervised fine-tuning (SFT). This penalty helps distinguish between favored and disfavored responses, thereby optimizing the model to generate preferred outputs.
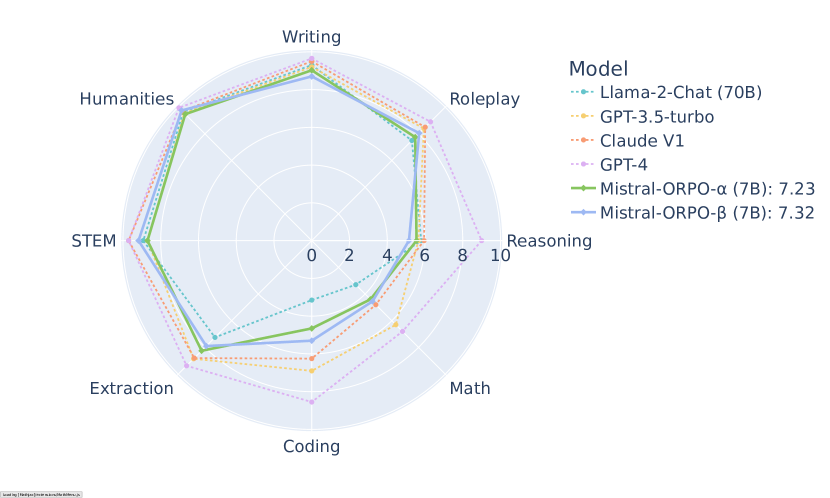
The key advantage of ORPO is its simplicity and efficiency, eliminating the need for a separate reference model and additional training phases. Empirical and theoretical analyses in the paper demonstrate that ORPO effectively aligns models to human preferences across various model sizes, from 125M to 7B parameters. The authors also highlight that ORPO surpasses the performance of state-of-the-art models in several benchmarks, such as AlpacaEval2.0 and MT-Bench, showcasing its effectiveness and scalability.
Benefits of Using ORPO
- No Need for a Reference Model
Traditional preference alignment methods, such as Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO), often require a reference model for comparing chosen and rejected responses. ORPO simplifies this process by eliminating the need for a reference model, reducing the computational resources required, and simplifying the training pipeline.
- Integrated Preference Alignment
ORPO incorporates preference alignment directly into the supervised fine-tuning (SFT) process. This integrated approach ensures that the model not only learns the desired domain but also aligns with user preferences simultaneously, leading to more efficient training.
- Effective Penalization of Undesired Responses:
By using an odds ratio-based penalty, ORPO effectively penalizes the model for generating disfavored responses. This penalty helps the model differentiate between favored and disfavored outputs, leading to better alignment with human preferences.
- Improved Performance on Benchmark Tasks
ORPO has demonstrated superior performance in various benchmark tasks, outperforming state-of-the-art models that use traditional fine-tuning methods. For instance, it achieved higher scores on AlpacaEval2.0 and MT-Bench, indicating its effectiveness in generating preferred outputs.
- Resource Efficiency
ORPO's approach to preference alignment is resource-efficient because it avoids the multi-stage processes and extensive hyperparameter tuning typically required in RLHF. This efficiency makes it more scalable and applicable to larger models without significantly increasing computational costs.
- Higher Win Rates in Preference Evaluations
The empirical results show that ORPO models have higher win rates in preference evaluations against models fine-tuned with standard SFT, PPO, and DPO. This indicates that ORPO better aligns with human preferences and generates more favorable outputs.
- Maintaining Domain Adaptation Role of SFT
ORPO preserves the domain adaptation benefits of SFT while simultaneously aligning the model with user preferences. This dual benefit ensures that the model remains highly relevant to the target domain while adhering to preferred response styles.
- Less Overfitting Risk
ORPO's odds ratio mechanism provides a balanced way to adjust the model's output probabilities, reducing the risk of overfitting specific training examples. This balanced approach helps in maintaining the model's generalization capabilities.
In a recent study conducted by us, we fine-tuned llama-3.1 8B on the Intel/orca_dpo_pairs dataset using ORPO and benchmarked it on MuSR and GPQA benchmarks. The results obtained demonstrated the incredible efficiency of ORPO while used properly. The fine-tuned llama-3.1 8B model was able to beat llama 3.1 70B by about 17% on MuSR and about 7% on GPQA with a cost of just $2.69. You can read more about this study here.
How to Fine-tune LLMs on MonsterAPI with ORPO
As we mentioned above, ORPO enhances fine-tuning results significantly. Here's how you can enhance the quality of your fine-tuned models using MonsterTuner and ORPO:
- Choose a Model
Login to your MonsterAPI account, if you don't have one, you can create one here. Once you've created an account, go to the fine-tuning section on the dashboard > finetune a LLM.
When a new window opens up, choose a model you want to fine-tune, give the fine-tuning job a name, and click "next".
- Upload a dataset
In the next step, choose the task type for which you want to fine-tune your model and upload a dataset. You can choose a custom dataset or upload a HuggingFace dataset. Click next.
- Set-up Hyper-parameters
In the next step, you can set up the Hyper-parameters or go forward with the default hyper-parameters. Before, you move to the next step, click on "preference optimization with ORPO".
Confirm all the settings and launch the fine-tuning job.
That's it, that's all it takes to fine-tune a model on MonsterAPI.
Conclusion
ORPO offers a powerful way to fine-tune large language models, balancing efficiency and performance. By integrating optimal regularization and pruning, you can develop models that are not only accurate but also efficient and scalable.
As you experiment with ORPO, you’ll discover the nuances of tailoring this technique to your specific needs, leading to better and more cost-effective AI solutions.