
Outperforming SOTA LLMs for Less than the Cost of a Coffee with Monster Tuner
Finetuning Mistral 7B LLM using Monster Tuner to outperform SOTA LLMs like Falcon and Zephyr.



At MonsterAPI, we used our no-code LLM fine tuner to enhance open-source models like Mistral-7B, Falcon-7B, and Zephyr-7B. We aimed to make them more human-like in responding to user instructions, similar to ChatGPT. Hence we finetuned said models on the HuggingFace no_robots dataset using our no-code LLM finetuner.
The Finetuned Mistral LLM demonstrated superior performance compared to the state-of-the-art (SOTA) in three benchmarks, namely Average, ARC, and Hellaswag. While our fine-tuned Zephyr model outperformed existing models in TruthfulQA.
The best part? Each experiment costs less than a cup of coffee — no coding required!
Here is the gist of benchmarking metrics:

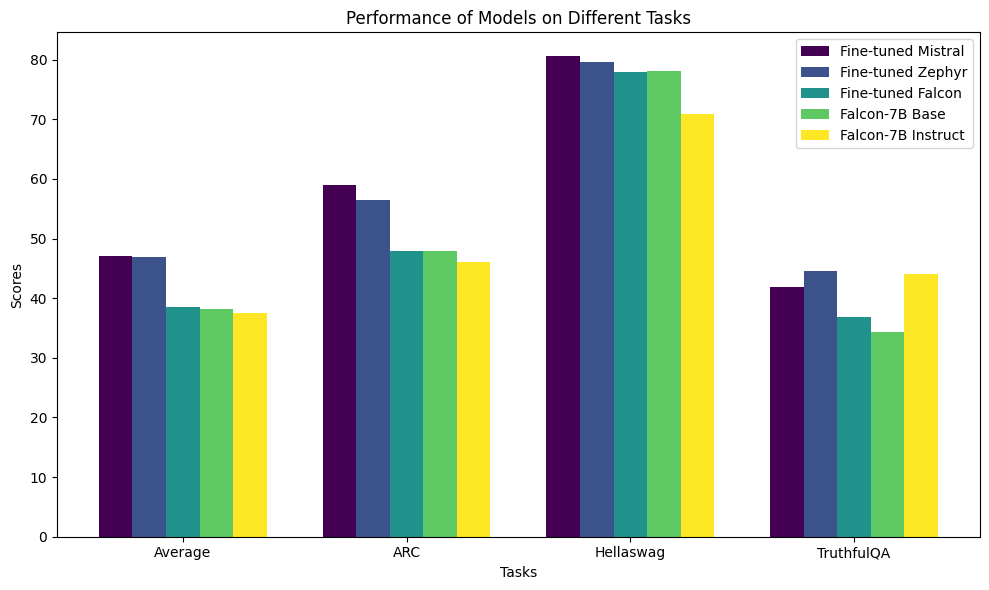
The figure depicts fine-tuned model performance across benchmarks.
- Finetuned Mistral 7B leads with an average score of 47.04, closely followed by Finetuned Zephyr 7B model at 46.86.
- Falcon models hover around 38, while the pre-trained base model "Falcon-7B Instruct" scores lowest at 37.47.
- Finetuned Mistral excels in ARC (58.96) and Hellaswag (80.57);
- Fineetuned Zephyr dominates in TruthfulQA (44.6).
- Falcon-7B Base and Fine-tuned Falcon tie in ARC (47.87).
- Falcon-7B Instruct lags in Hellaswag (70.85) but competes well in TruthfulQA (44.08).
Access all our Finetuned Models here:
MonsterAPI HuggingFace repository
Detailed Study:
Let's dive into the specifics of our process and the valuable takeaways gained from this experiment!
Dataset Used -
We used the no_robots dataset – a high-quality collection of 10,000 instructions and demonstrations crafted by skilled human annotators. It's perfect for supervised fine-tuning (SFT), teaching language models to follow instructions accurately.
LLMs involved in this case study:
Falcon-7B: A specialized causal decoder-only model with 7 billion parameters, crafted by TII and trained on 1,500B tokens of RefinedWeb bolstered with curated corpora.
Mistral 7B: A versatile model consistently outperforming Llama 2 13B and often surpassing Llama 1 34B across multiple benchmarks. Excelling in coding tasks, it matches CodeLlama 7B's performance while maintaining proficiency in diverse English language tasks.
Zephyr: A refined iteration of Mistral-7B, marking a significant leap in AI-driven assistance. Developed to create a more compact language model that effectively aligns with user intent.
What makes Zephyr-7B exceptional is its achievement without any human annotation. Notably, it outperforms Llama2-Chat-70B, a top open-access RLHF-based model, particularly in chat-related tasks.
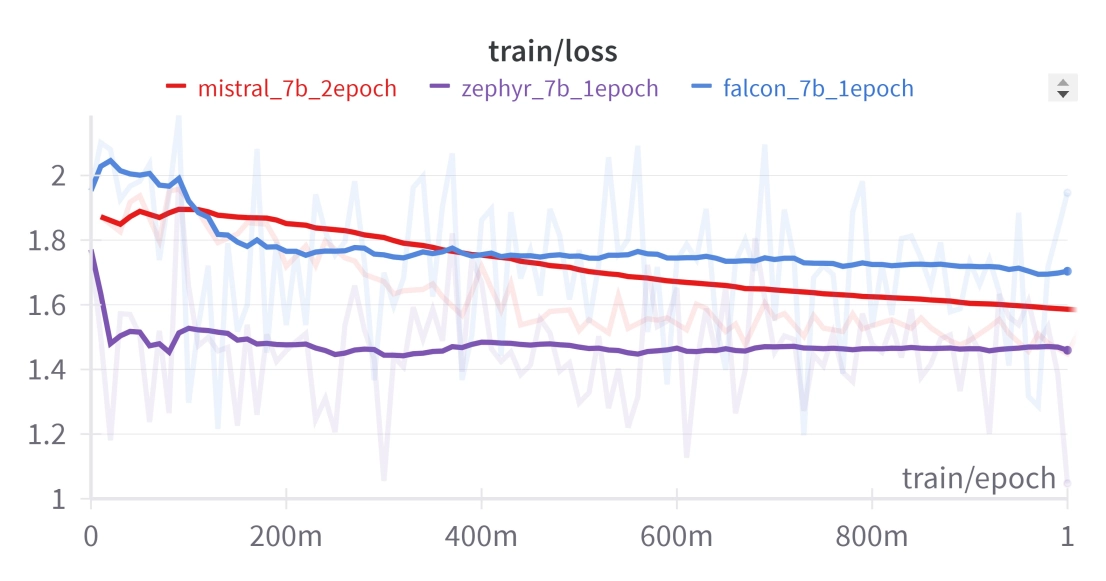
Training Metrics:
The experiment utilized the No_Robots dataset. The resulting loss metrics showcase significant progress and improvement across the models during fine-tuning.
We conducted a fine-tuning experiment involving Falcon, Zephyr, and Mistral models. All except Mistral, underwent a single epoch of training, which underwent 2 epochs.
Hyperparameter Details -
Checkout out Documentation on How to easily finetune LLMs using MonsterTuner
Detailed Benchmarking Results:
We conducted a comparison between the Mistral 7B Base model and its finetuned counterpart across various benchmarks, analyzing their performance as follows:
- ARC Challenge (AI2 Reasoning Challenge): This test evaluates the model's capacity to solve complex queries using reasoning skills.
- Hellaswag (Common-Sense Reasoning): This benchmark measures the model's ability to predict the most appropriate following sentence within a given context.
- TruthfulQA (Factual Accuracy): This evaluation examines the model's accuracy in delivering truthful and factually correct responses.
Key Insights:
After fine-tuning, Mistral achieves the highest average score of 47.04, closely followed by Zephyr at 46.86. Both Falcon and Falcon-7B Base show similar average scores of around 38, while Falcon-7B Instruct records the lowest average score of 37.47.
In specific categories, Mistral excels in ARC (58.96) and Hellaswag (80.57). Meanwhile, Zephyr outperforms all others in TruthfulQA with a score of 44.6.
Notably, Falcon-7B Base and Fine-tuned Falcon tie with identical scores in ARC (47.87). However, Falcon-7B Instruct shows the lowest performance in the Hellaswag category (70.85).
Despite its lower average score, Falcon-7B Instruct demonstrates competitive performance in TruthfulQA with a score of 44.08, coming close to the top performer in this category.
Potential Use Cases-
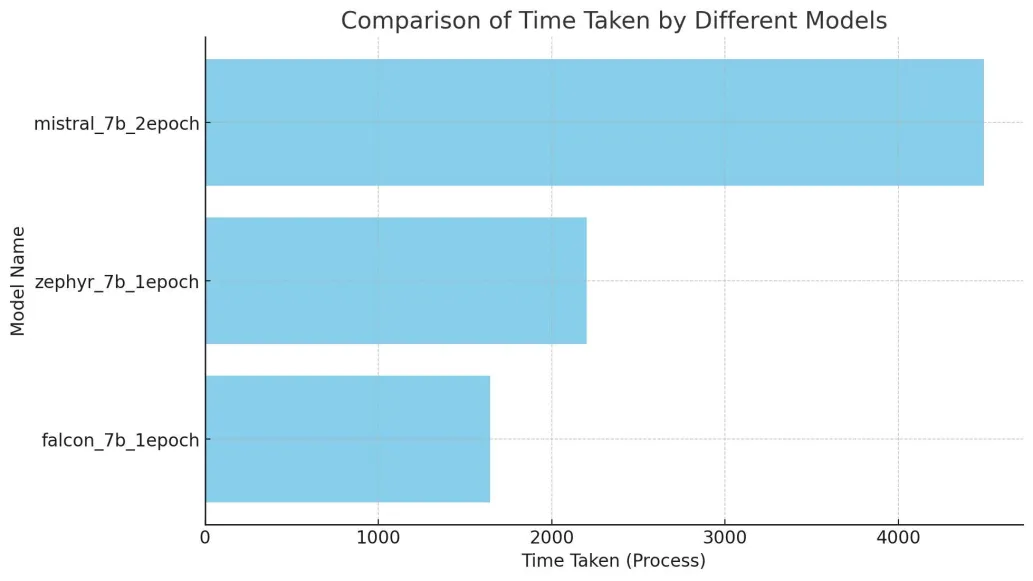
Cost Analysis and Efficiency :
The cost analysis of fine-tuning Zephyr and Mistral on MonsterAPI also emphasizes the cost-effectiveness and efficiency of this approach compared to traditional cloud platforms:
Cost Savings:
Efficiency: MonsterAPI's no-code LLM finetuner reduces both time and manual effort by automatically figuring out the most optimal hyperparameters and deploying them on appropriate GPU infrastructure without you having to set it up. Thus, streamlining the complete fine-tuning pipeline.
Benefits of using MonsterAPI’s no-code LLM finetuner:
The no-code fine-tuning approach is a game-changer, simplifying the complex process of fine-tuning language models. It reduces setup complexity, optimizes resource usage, and minimizes costs.
This makes it easier for developers to harness the power of large language models, ultimately driving advancements in natural language understanding and AI applications.
Sign up on MonsterAPI to get free credits and try out our no-code LLM Finetuning solution today!
Check out our documentation on Finetuning an LLM.