
Introducing no-code LLM FineTuning with Monster API
Introducing our no-code LLM fine-tuner. In just 3 simple steps, you'll be able to fine-tune open source LLMs, Whisper & SDXL models.


Fine tuning pre-trained models is essential to improve the model's performance for specific use-cases. At Monster API, we understand the challenges developers face when fine-tuning models, especially when it comes to complex setups, memory limitations, high GPU costs, and the absence of standardized practices.
That's why we're thrilled to introduce our no-code LLM Fine-Tuning product, designed to simplify and expedite the fine-tuning process while providing you with all the capabilities and possibilities you need.
What is LLM Fine-Tuning and why is it so important?
While pre-trained models like GPT-J, LLaMA, Falcon, StableLM, OPT have broad language knowledge, fine-tuning allows developers to enhance their performance for specific tasks. Fine-tuning makes models more accurate, context-aware, and aligned with the target application.
Instead of training a language model from scratch, which requires substantial data and computational resources, fine-tuning leverages the existing knowledge of pre-trained models and tailors it to the specialized task.
Challenges associated with Finetuning LLMs:
Fine-tuning LLaMA and other large language models presents several challenges.
Complex setups, memory requirements, GPU costs, and the lack of standardized practices can hinder the fine-tuning process and make it complicated for developers to get a model tailored to their needs.
However, with Monster API's LLM FineTuner, these challenges have been addressed effectively:
- Complex Setups
Monster API simplifies the often complex process of setting up a GPU environment for FineTuning machine learning models, encapsulating it within a user-friendly, intuitive interface.
This innovative approach eliminates the need for manual hardware specification management, software dependencies installations, CUDA toolkit setups, and other low-level configurations.
By abstracting these complexities, the Monster API LLM Finetuner allows users to easily select their desired models, datasets and hyper-parameters and focus on the actual task of refining machine learning models.
- Memory Constraints
FineTuning large language models such as LLaMA, can require significant GPU memory, which can be a limitation for many developers.
Monster API addresses this challenge by optimizing memory utilization during the FineTuning process. It ensures that the process is efficiently conducted within the available GPU memory. Thus, making large language model Fine-Tuning more accessible and manageable, even with resource limitations.
- GPU Costs
GPU costs can quickly escalate when FineTuning machine learning models, making it a luxury that not all developers can afford.
However, Monster API brings to use its fully compliant GPU platform which enables on-demand access to ultra-low-cost GPU instances. Thus, significantly reducing the cost and complexity associated with accessing powerful computational resources for LLMs.
- Standardized Practice
The absence of standardized practices in the industry can make the FineTuning process frustrating and time-consuming.
Monster API simplifies this by providing an intuitive interface and predefined tasks, along with the flexibility to create custom tasks. Our platform guides you through the best practices, eliminating the need to navigate through a maze of documentation and forums.
You can rely on Monster API to simplify and streamline the intricate fine-tuning process, making it quick and easy for you to tackle. By using Monster API, you can effortlessly fine-tune a large language model like LLaMA 7B with DataBricks Dolly 15k for 3 epochs using LoRA.
And guess what? It won't break your bank, costing you less than $20.
For context about the LLM and Dataset used for demo:
LLaMA (Large Language Model Meta AI) is an impressive language model developed by Facebook AI Research (FAIR) for machine translation tasks. Based on the Transformer architecture, LLaMA is trained on a vast corpus of multilingual data, enabling it to translate between many language pairs. LLaMA 7B, with 7 billion parameters, is the smallest variant of this model.
To demonstrate interactive and engaging conversational abilities like ChatGPT, we utilized the Databricks Dolly V2 dataset. This dataset, specifically the "data bricks-dolly-15k" corpus, consists of over 15,000 records created by Databricks employees, providing a diverse and rich source of conversational data.
In just five simple steps, you can set up your fine-tuning task and experience remarkable results.
So, let's get started and explore the process together!
1. Select a Language Model for Finetuning:
The first step is to choose an LLM that suits your needs. You have a variety of popular open-source language models to choose from, such as LLaMa series, Gemma series, GPT-J 6B, or StableLM 7B.
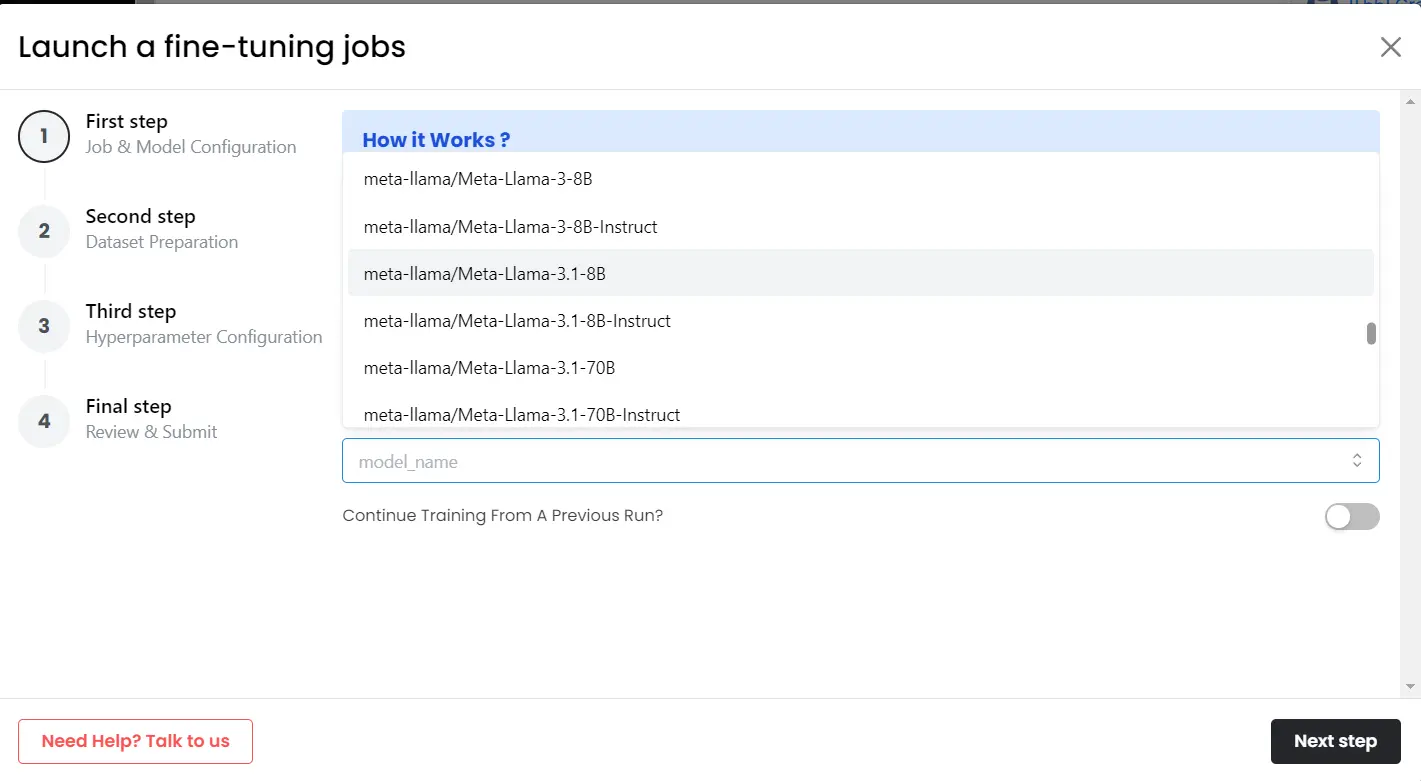
2. Select or Create a Task:
Next, you define the task for FineTuning the LLM. With Monster API, you have the flexibility to select from pre-defined tasks like "Instruction Fine-Tuning" or "Text Classification." If your task is unique, you can even choose the "Other" option to create a custom task. We value your specific requirements and provide options accordingly.

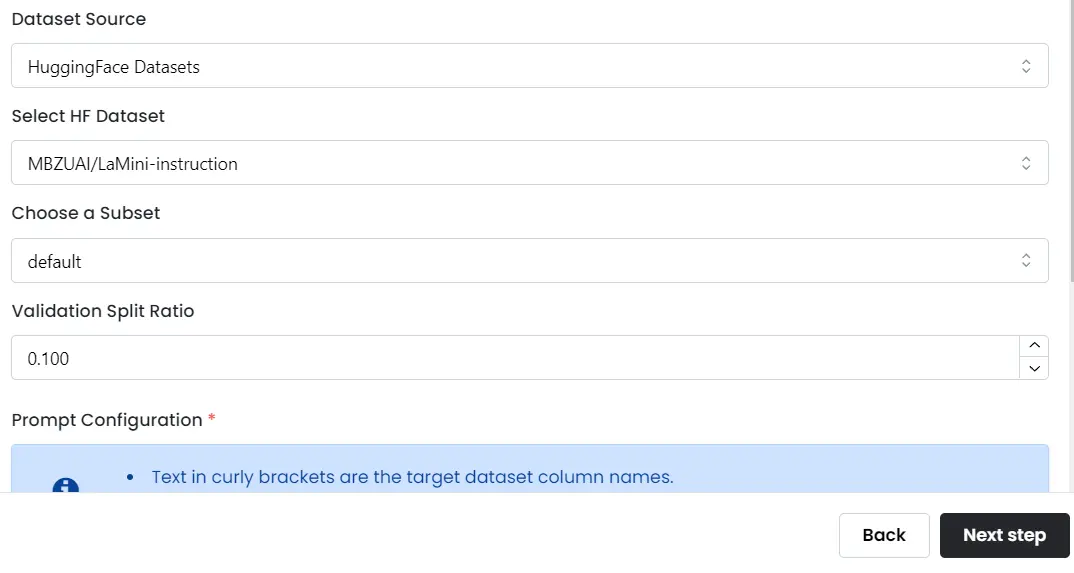
3. Select a Dataset:
To train your LLM effectively, you need a high-quality dataset. Monster API seamlessly integrates with HuggingFace datasets, offering a wide selection. We even suggest relevant datasets based on your chosen task.
If you have a custom dataset you want to use to train your model, you can upload your personal dataset.
With just a few clicks, your selected dataset is automatically formatted and ready for use. We want to make it easy for you to access the data you need.
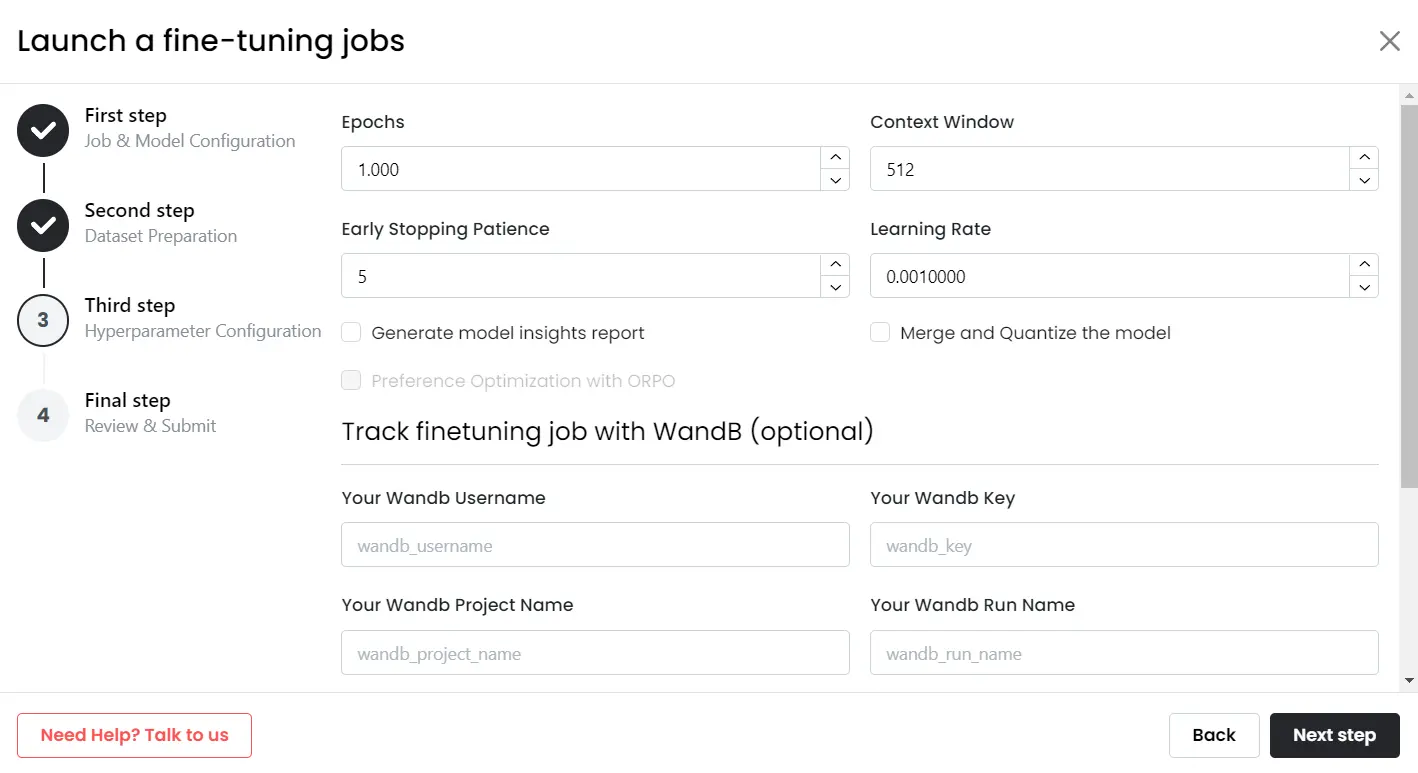
4. Specify Hyper-parameters:
Monster API simplifies the process by pre-filling most of the hyper-parameters based on your selected LLM. However, we understand that you may have specific preferences. You have the freedom to customize parameters such as epochs, learning rate, cutoff length, warmup steps, and more, ensuring your LLM is fine-tuned to your exact requirements.
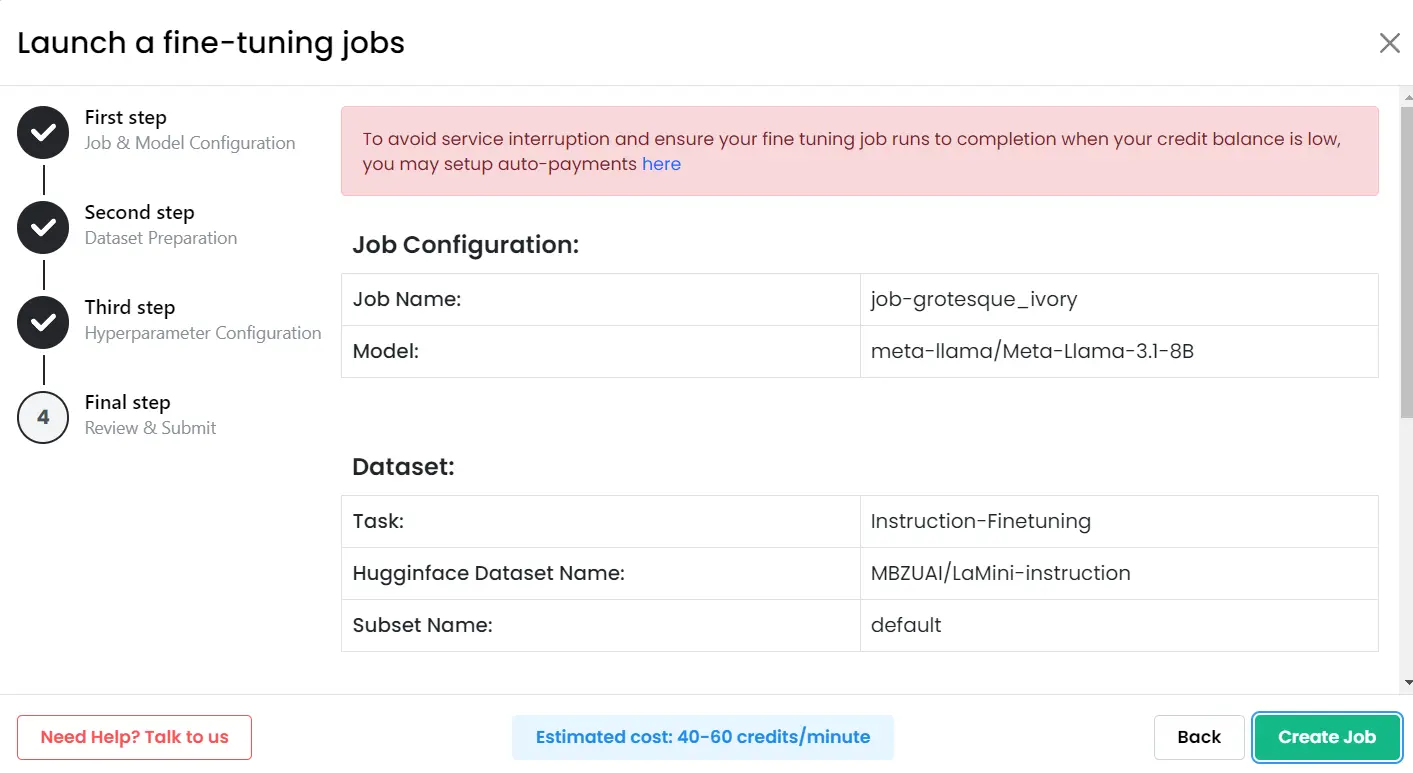
5. Review and Submit Finetuning Job:
After setting up all the parameters, you can review everything on the summary page. We know the importance of accuracy, so we provide this step to ensure you have full control. Once you're confident with the details, simply submit the job. From there, we take care of the rest.
That’s it! In just five easy steps, your job is submitted for FineTuning an LLM of your choice. We're committed to simplifying the process so you can focus on your task without being overwhelmed by complex configurations.
After successfully setting up your fine-tuning job using Monster API, you can monitor the performance through detailed logs on WandB. We believe in providing you with the insights you need to make informed decisions and achieve the best results.
The Benefits of Monster API
The value of Monster API's Fine-Tuning LLM product lies in its ability to simplify and democratize the use of large language models (LLMs). By eliminating common barriers such as technical complexity, memory constraints, high GPU costs, and lack of uniform practices, the platform makes AI model fine-tuning accessible and efficient. In doing so, it empowers developers to fully leverage LLMs, fostering the development of more sophisticated AI applications.
Ready to finetune an LLM for your business needs?
Sign up on MonsterAPI to get free credits and try out our no-code LLM Fine-tuner solution today!
Check out our documentation on Finetuning an LLM.