
Enhancing Language Model Fine-tuning with LLM Data Augmentation


Fine-tuning large language models (LLMs) for specific applications can sometimes be constrained by the limited availability of targeted data. This is where data augmentation steps in , allowing developers to expand their existing limited datasets and improve model performance without the need for manual data collection and wrangling efforts.
Here we would like to introduce MonsterAPI’s new Data Augmentation API for streamlining the process of augmenting and scaling out Datasets.
What is Data Augmentation?
Data augmentation involves artificially expanding a dataset by creating modified versions of existing data points. In the context of LLMs, this might include paraphrasing sentences, changing the voice from active to passive, or introducing synonyms and slight rephrasing.
The goal is to generate new data points that maintain the original semantics but differ in syntax or style, providing the model with a broader range of examples to learn from.
The Role of Data Augmentation in Fine-tuning LLMs
When fine-tuning LLMs, the primary challenge often lies in the scarcity of domain-specific data. Data augmentation addresses this by:
- Increasing dataset size: This helps prevent overfitting, allowing the model to generalize better on unseen data.
- Making models more robust: By training on varied versions of the same data, models can better handle diverse input scenarios.
- Improving data quality: Augmentation can help balance datasets, particularly in cases where some classes are underrepresented.
MonsterAPI's Data Augmentation API
MonsterAPI's Data Augmentation API service has been designed to enhance your text data by generating additional rows or new preference datasets, ideal for model fine-tuning. It simplifies the process, allowing you to specify data details and choose between generating evolved instructions or preference datasets, all while avoiding complexity.
MonsterAPI Supports two kinds of Data-Augmentation
- Evol-Instruct ( multiplying your dataset size)
This approach leverages LLMs to automatically generate diverse and complex instruction data. Evol-Instruct enhances LLMs by iteratively evolving instructions through in-depth and in-breadth modifications, and then fine-tuning models with these enriched datasets. It uses a initial instruction and passes it onto an LLM to make it more and more complex.
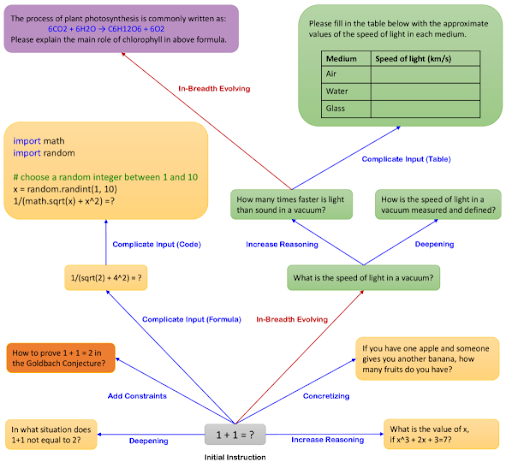
- Ultrafeedback (Preference Dataset Generation)
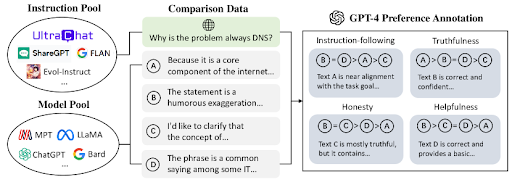
This method generates a large-scale, high-quality preference dataset designed to enhance the alignment of language models with human preferences through Reinforcement Learning from Human Feedback (RLHF). To construct this dataset, known as ULTRAFEEDBACK, a diverse array of instructions and model outputs were compiled from multiple sources.
This method ensures a rich variety of scenarios by producing comparative data across different responses. Detailed annotation instructions were developed, and models, including GPT-4, were used to provide both numerical and textual feedback on these responses.
This framework not only supports the continuous development of RLHF but also serves as a robust foundation for future research, ensuring that language models can generate responses that better satisfy human preferences.
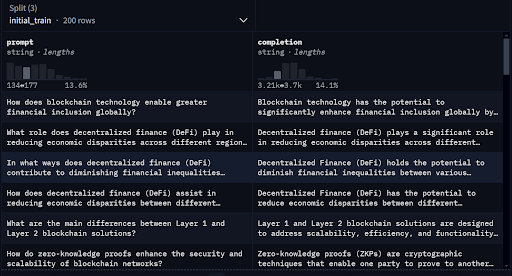
Case Study: Creating A Model Expert on Blockchain Technology
To illustrate the benefits of data augmentation, we manually created a dataset of 200 rows for train and 100 of test splits with questions and answers related to blockchain. We fine-tuned a base model on this initial dataset and then used the Evol-Instruct methodology to augment the data. The price for this dataset augmentation of expanding the 200 rows into 800 was only $1.2. We trained another model on the augmented dataset.
How to Augment data using MonsterAPI?
To augment your datasets using MonsterAPI, you can easily call the "data-augmentation-service" service. Here's how to get started with a code example:
You can send a https request to the “https://api.monsterapi.ai/v1/generate/data-augmentation-service”
{
"data_config": {
"data_path": "Zangs3011/crypto_dataset",
"data_subset": null,
"prompt_column_name": "prompt",
"data_source_type": "hub_link",
"split": "intitial_train"
},
"task": "evol_instruct",
"generate_model1_name": "gpt-4-turbo","
num_evolutions": 2,
"openai_api_key": "YOUR_API_KEY
}
Example Payload
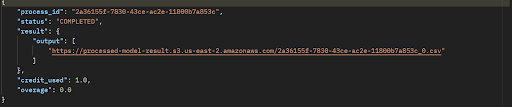
After that you will receive a process_id in response.

And then we can query the deployment status to get the current job state. This can be done by sending a get request to https://api.monsterapi.ai/v1/status/{process_id} replacing {process_id} with the process_id you recieved previously. for example
curl --request GET \
--url https://api.monsterapi.ai/v1/status/7b304054-f1bf-4cba-b6c7-6803e770bc91 \
--header 'accept: application/json' \
--header 'authorization: Bearer YOUR_BEARER_TOKEN'
If the job is complete, we will receive a downloadable CSV file link as shown below:
Sample Notebook Walkthrough
You can also use this notebook as a detailed reference , it also includes the steps for launching the job for fine-tuning: https://colab.research.google.com/drive/1565w3BbVkmJ4rW5c5nuhz6tHhei0lujV?usp=drive_fs
- Setup and Configuration: Instructions on setting up MonsterAPI and preparing your environment.
- Data Augmentation Pipeline: Detailed code snippets show how to send text data to MonsterAPI and receive augmented data.
Training an LLM: The notebook demonstrates how to use the augmented data to fine-tune an LLM, including loading data, setting training parameters, and running the training loop.
Training Loss curves:
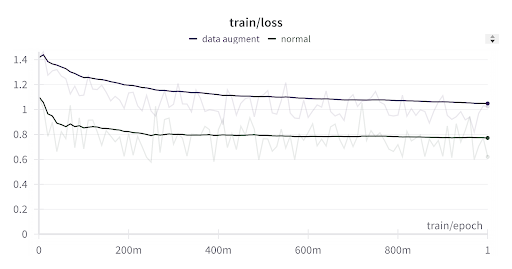
Note: the data-augmented training runs on a harder dataset, seeing a higher loss is expected.
Evaluation:
We then evaluated the three models on the test set using gpt-4-turbo as the judge.We passed the completions from all the three models to GPT 4-turbo i.e. for the base model, the regular fine-tuned model and the model fine-tuned on augmented dataset.
Along with the true completions, we asked gpt-4-turbo to rate the completions on the scale of 1 to 5. Here are the results:
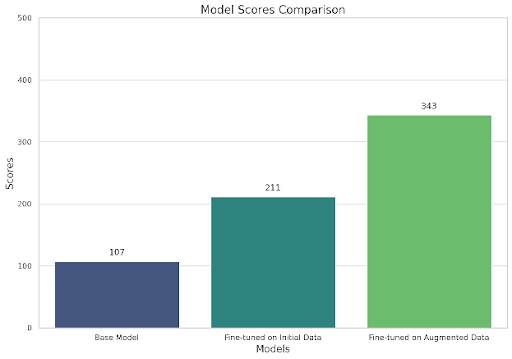
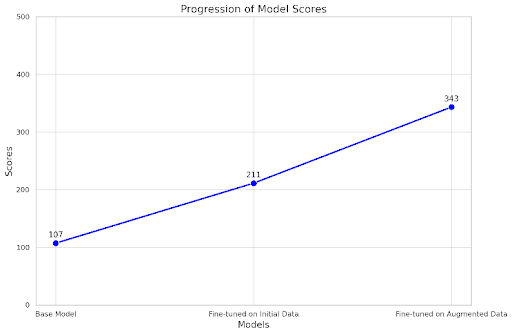
Base model ( LLaMA3 8B ): 107/500
Model fine-tuned only on the initial data: 211/500
Model fine-tuned on the augmented data: 343/500
Conclusion
The integration of MonsterAPI's Data Augmentation Service into the fine-tuning process of large language models (LLMs) demonstrates a significant enhancement in model performance, particularly in domain-specific applications where data may be scarce.
By utilizing methods such as Evol-Instruct and Ultrafeedback, developers can effectively increase the diversity and quality of their training datasets without extensive manual effort and resource costs.