
Learn how we delivered 10M tokens per hour on Zephyr 7B LLM using Monster Deploy
Deploy LLMs like Llama, Mistral, Zephyr with 10M tokens per hour throughput using Monster Deploy at 10x low cost.


With the growing demand for Large Language Models (LLMs) in the industry today, it becomes imperative to ensure a high throughput of output tokens produced by LLMs at lower cost of serving and thus to enable AI/ML app developers for supporting their growing user base without burning a hole in their pocket.
Not only cost but also reducing the complexity of setting up and running the large computing clusters that power these LLMs in a production environment plays an important role in making LLMs more accessible, as they are one of the most fundamental breakthroughs in recent years.
To make this process of deploying LLMs easier, scalable, and low-cost, we are introducing Monster Deploy. A one-click LLM deployment solution that enables developers to serve SOTA LLMs on a variety of GPUs ranging from 8 - 80GB with in-built optimizations for cost reduction and maximum throughput.
To access Monster Deploy Beta:
- Step 1: Sign up on MonsterAPI platform.
- Step 2: Apply for Monster Deploy Beta here. Use your organization/business email for free 30K credits.
Below we showcase a benchmark of serving Zephyr-7b, a SOTA Open source 7B parameter LLM, using Monster Deploy on GPUs such as Nvidia RTX A5000 (24GB) and A100 (80GB) in multiple scenarios.
This breakthrough offers a blend of affordability and performance, setting a new standard in the field of LLM deployment.
Enhanced Product Usability:
Monster Deploy stands out with its user-friendly approach to deploying LLMs. The service provides a seamless experience with its intuitive UI, Python client or with a single curl request, allowing users to deploy models effortlessly across various high-performance GPUs. This ease of use is a game-changer, especially for those who need to deploy complex models without getting entangled in technical intricacies.
Performance Metrics:
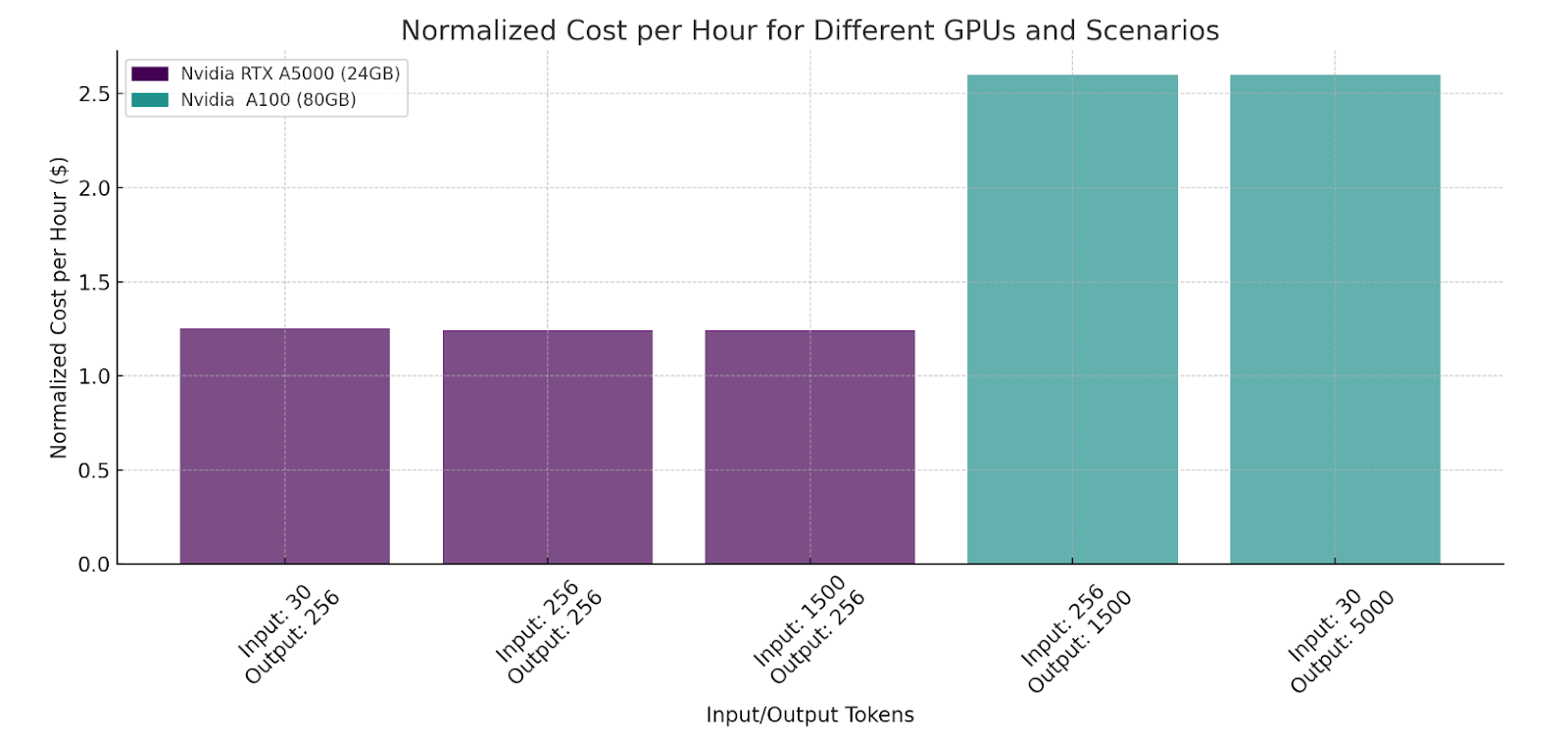
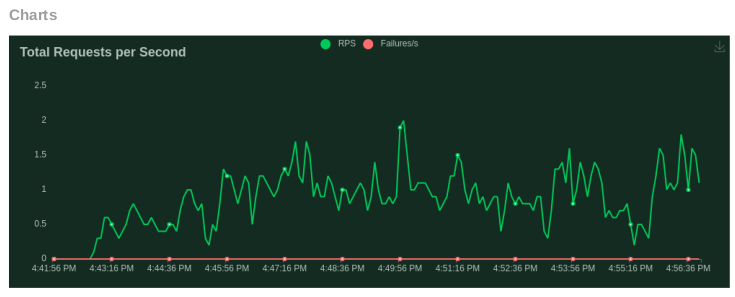
Our benchmarking tests have demonstrated the efficiency of Monster Deploy. For instance, on the Nvidia RTX A5000, we observed a 100% success rate with an average response time (ART) of just 16ms, while handling over 39,000 requests at a cost of $1.25/hr. These metrics are a testament to the capability of Monster Deploy to handle intensive workloads while maintaining cost-effectiveness and speed.
Benchmarking results:
Setup:
We tested the deployed model with multiple scenarios mimicking real-world LLM use cases:
A5000 - 24GB Scenarios:
Scenario 1 - Short Question Answering
This scenario is designed to simulate environments where brief and precise answers are required, typical of applications like chatbots or virtual assistants. It involves processing queries with up to 30 input tokens and generating responses with up to 256 output tokens. This setup is ideal for situations such as customer service bots, interactive educational tools, or any application where quick, straightforward responses are needed. Examples include FAQ bots, interactive storytelling for children, or quick fact-checking tools.
Scenario 2 - Contextual Medium-Length Answering
This scenario is crafted to handle cases that involve a moderate amount of context, such as answering questions with a paragraph-long background or applications that require summarization of larger contexts. With 256 input and 256 output tokens, it's well-suited for applications like Retrieval-Augmented Generation (RAG) where contextual information enhances the quality of the response. This setup can be applied in scenarios like news article summarization, detailed product queries in e-commerce, or providing in-depth explanations in educational platforms.
Scenario 3 - Extensive Context Generation
This scenario focuses on tasks requiring substantial context handling, ideal for heavy document summarization or detailed content generation. With 1500 input tokens and 256 output tokens, it's tailored for processing large volumes of information and condensing it into concise, informative summaries. Applications could include lengthy legal document summarization, detailed medical report generation, or creating executive summaries from comprehensive research papers. It's also beneficial in creative domains for generating story outlines from extensive character and plot descriptions.
A100 80GB Scenarios:
Scenario 1 - Advanced Contextual Queries
This scenario is tailored for applications requiring an in-depth understanding of complex queries, especially suitable for Nvidia A100 (80GB). With 256 input tokens and 1500 output tokens, this setup excels in environments where responses need to incorporate a broad range of information or detailed explanations. Ideal use cases include advanced academic research assistance, comprehensive technical support chatbots, and in-depth data analysis reporting. It can also be applied to interactive learning platforms where detailed, step-by-step guides or explanations are needed.
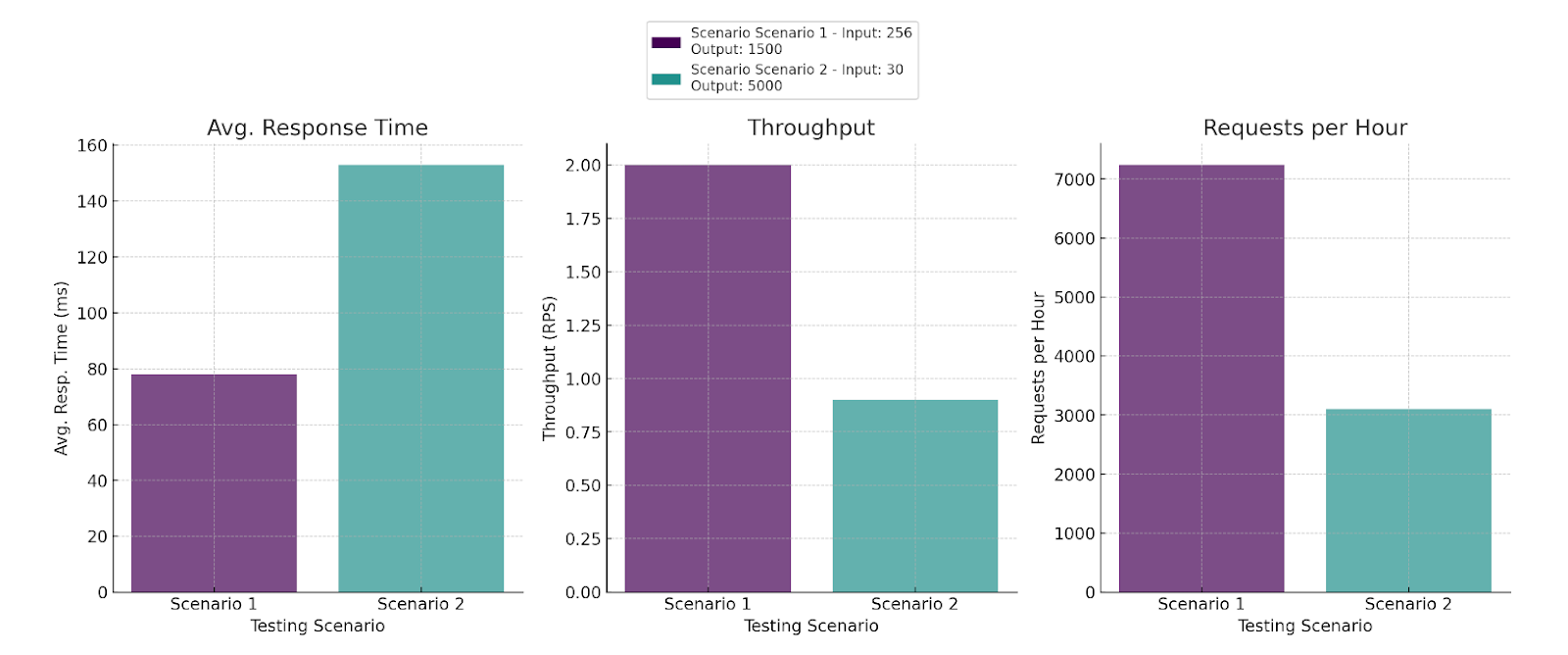
Scenario 2 - High Volume Content Generation
In this scenario, the focus is on generating extensive and detailed content, leveraging the Nvidia A100's (80GB) capabilities. With 30 input tokens and 5000 output tokens, it's designed for scenarios that demand long-form content generation from concise prompts. This setup is perfect for creating long narratives, extensive reports, or detailed product descriptions in e-commerce. It can also be applied in creative fields like scriptwriting or novel drafting, where a brief outline can be transformed into a detailed manuscript. Additionally, it's useful in academic settings for expanding on short thesis statements or research questions into comprehensive essays or reports.
Metrics:
A5000 Benchmarking Results

A100 Benchmarking Results
Cost For Different Scenarios
Detailed benchmarking results can be found in the Appendix
Conclusion:
For a mere cost of $1.25, we were able to serve 39K requests successfully with each request producing 256 tokens. A total of 10 million tokens generated in an hour.
A game-changer for researchers and developers, MonsterAPI's Monster Deploy supports a wide range of models and seamlessly integrates with powerful GPUs, such as the Nvidia A100 with 80GB. It significantly reduces development cycles, enabling faster and more affordable model experimentation; the wide GPU support optimizes resource utilization, allowing users to select the most suitable hardware; and the detailed logs and simple termination features make debugging and optimizing deployed models for effective language processing easier.
With a 100% success rate, Monster Deploy supports a wide range of use cases and demonstrates flexibility in situations such as Quick QA, quick commands, data summarization, and sophisticated queries. It works especially well with the Nvidia RTX A5000 (24GB) GPU. Based on cost and Average Response Times (ART) that meet their throughput needs, users can choose deployments.
The Nvidia A100 (80GB) continues to have flawless performance in situations involving extensive storytelling, thorough justifications, and massive production. Users are empowered to initiate customized deployments that precisely meet their needs and maximize throughput because each scenario presents distinct ART and economic considerations. Monster-Deploy provides flexible and easy-to-use language processing capabilities.
Appendix:
Benchmarking Zephyr Deployment on Nvidia RTXA5000 with 24GB GPU RAM
A recent benchmark test of Monster Deploy focusing on the deployment of the Zephyr model onto a 24GB Nvidia RTX A5000, demonstrated its exceptional performance.
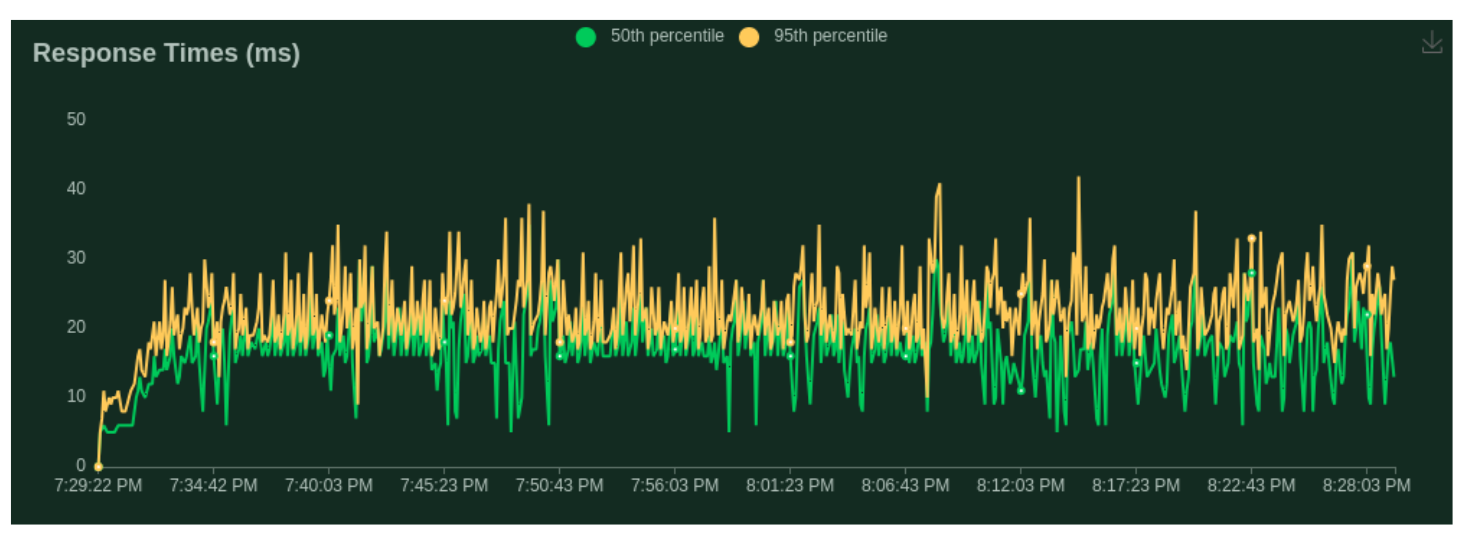
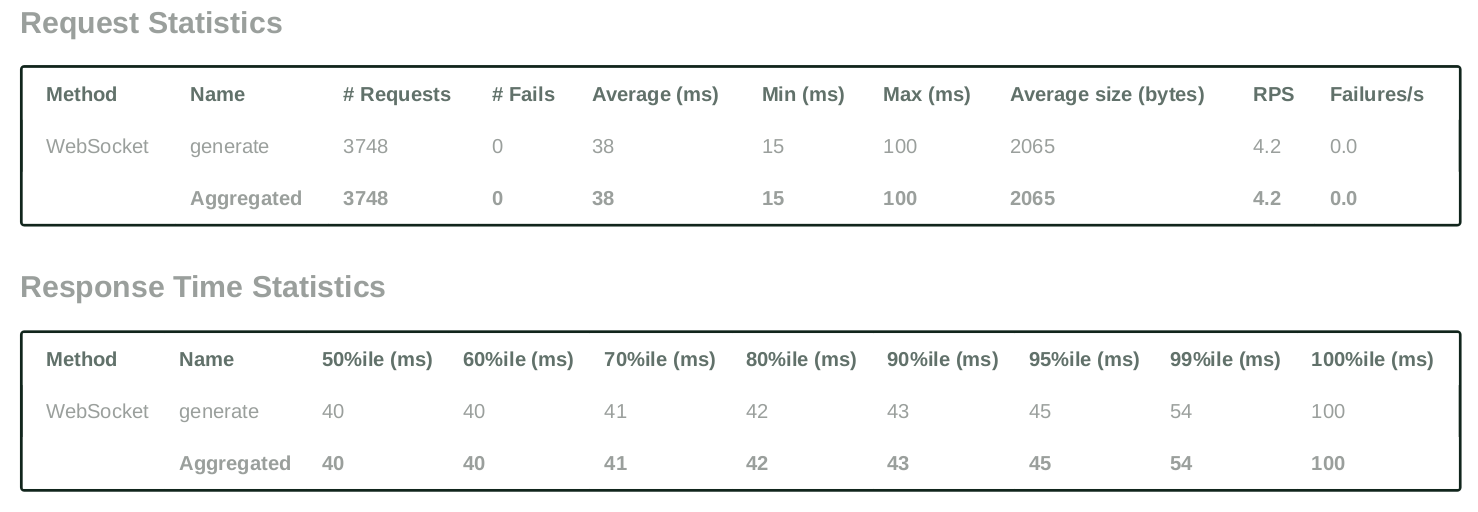
Testing Case - 1 (Simple Question Answering):
- Number of users (peak concurrency): 200
- Spawn Rate (users started/second): 1
- Run Time: 1h
- Input Token Length: 30 Tokens (max)
- Output Token Length: 256 Tokens (max)
- Cost: $1.25
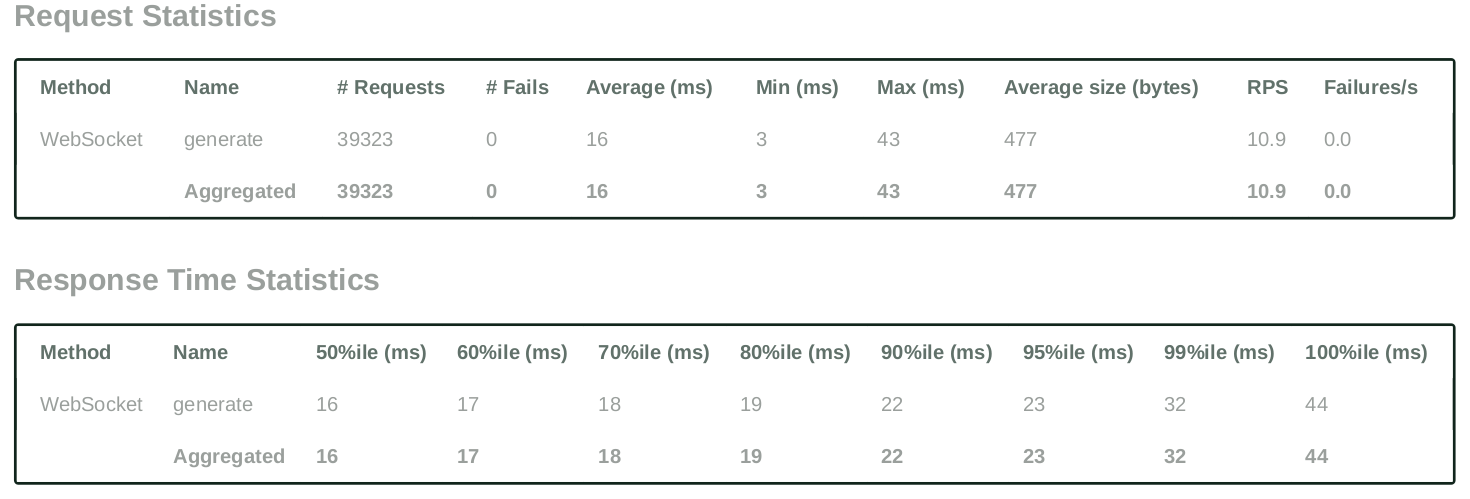
Testing Case - 2 (Question Answering with minor context):
- Number of users (peak concurrency): 200
- Spawn Rate (users started/second): 1
- Run Time: 15m
- Input Token Length: 256 Tokens (max)
- Output Token Length: 256 Tokens (max)
- Cost: $0.31

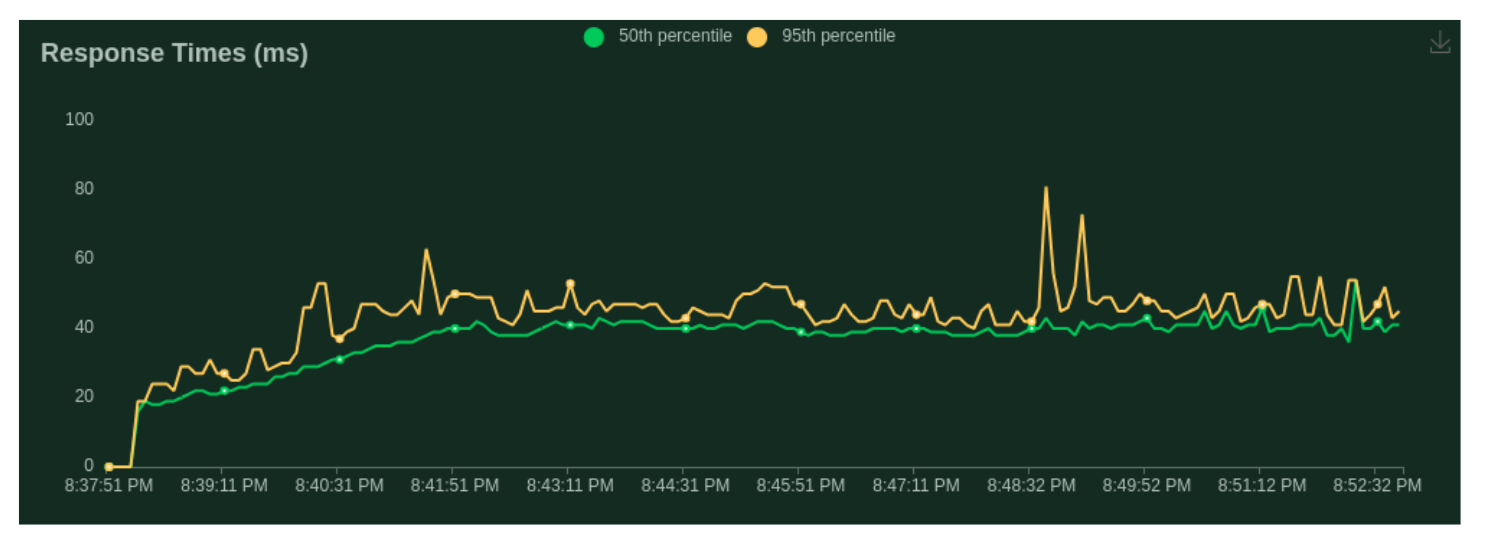
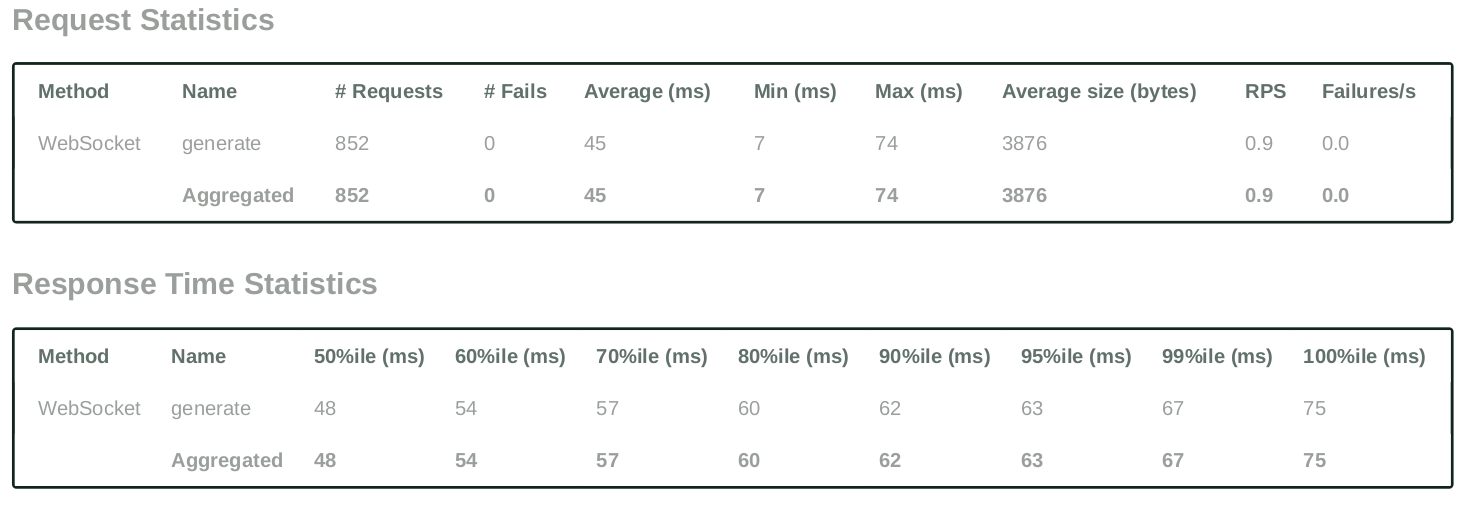
Testing Case - 3 (Question Answering with heavy context):
- Number of users (peak concurrency): 200
- Spawn Rate (users started/second): 1
- Run Time: 15m
- Input Token Length: 1500 Tokens (max)
- Output Token Length: 256 Tokens (max)
- Cost: $0.31
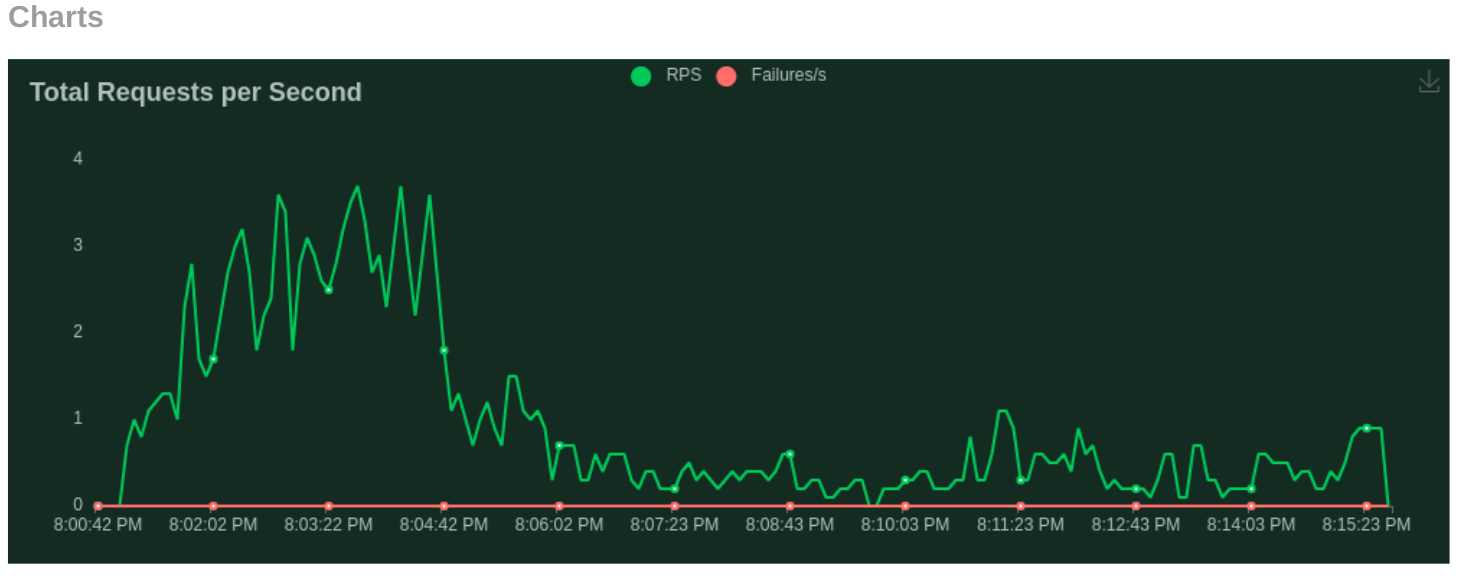
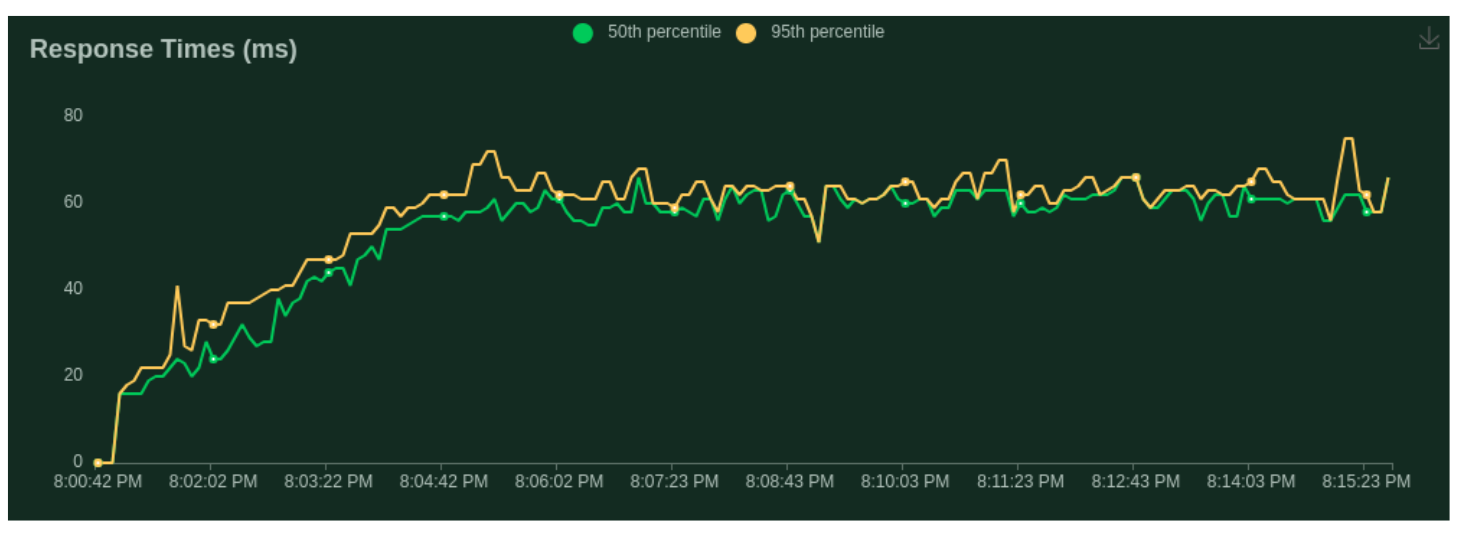
Benchmarking Zephyr Deployment on Nvidia RTX A100
A recent benchmark test of Monster Deploy focusing on the deployment of the Zephyr model onto an 80GB Nvidia RTX A100, demonstrated its exceptional performance.
Testing Case - 1 ( Heavy Generation Medium Context):
- Number of users (peak concurrency): 200
- Spawn Rate (users started/second): 1
- Run Time: 15m
- Input Token Length: 256 Tokens (max)
- Output Token Length: 1500 Tokens (max)
- Cost: $0.65
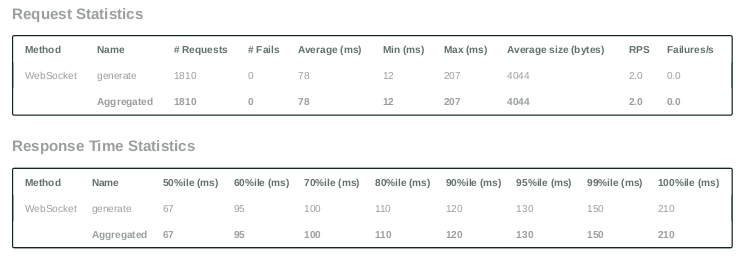

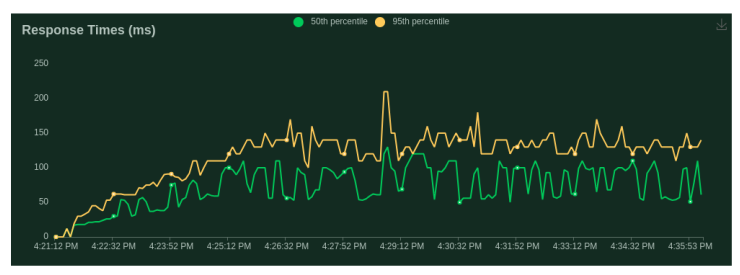
Testing Case - 2 (Humongous generation):
- Number of users (peak concurrency): 200
- Spawn Rate (users started/second): 1
- Run Time: 15m
- Input Token Length: 30 Tokens (max)
- Output Token Length: 5000 Tokens (max)
- Cost: $0.65


To get started with Monster Deploy Beta:
- Step 1: Sign up on MonsterAPI platform.
- Step 2: Apply for Monster Deploy Beta here. Use your organization/business email for free 30K credits.
We will release beta access on a rolling basis and you should soon hear from us with guides and documentation on how to deploy SOTA LLMs in production with Monster Deploy.
For any questions or queries, you may reach us out at support@monsterpi.ai or join our Discord community to engage with our team and growing developer base!