
Instruction Pre-Training of Language models using Monster-API
Pre-training is a crucial step in the development of large-scale language models, forming the bedrock upon which their language understanding and generation capabilities are built.


Pre-training is a crucial step in the development of large-scale language models, forming the bedrock upon which their language understanding and generation capabilities are built.
This phase involves training the model on extensive datasets containing diverse text sources, ranging from books and articles to web pages. Technically, pre-training is often accomplished through self-supervised learning techniques, where the model learns to predict masked or missing tokens within text sequences. For instance, using tasks like masked language modeling (MLM) or autoregressive language modeling, the model adjusts its internal weights based on the difference between its predicted and actual token values.
This adjustment is carried out via backpropagation and optimization algorithms like stochastic gradient descent (SGD), minimizing the loss function over numerous iterations. The goal of pre-training is not to solve specific tasks but to imbue the model with a broad understanding of language structure and knowledge, enabling it to generalize effectively when fine-tuned for specific applications.
The pre-training process for language models, particularly using techniques like autoregressive language modeling or masked language modeling, can be explained with mathematical formulations.
Objective Function
The goal of pre-training is to minimize the loss function L that measures the difference between the predicted tokens and the actual tokens in the dataset.
be a sequence of tokens, where T is the total number of tokens in the sequence.
Autoregressive Language Modeling (e.g., GPT)
In autoregressive models, the objective is to predict the next token xₜ given the previous tokens x<t=(x₁,x₂,…,x[t-1]). The model learns the conditional probability distribution:
where θ represents the model parameters.
The model is trained to minimize the negative log-likelihood of the actual tokens:
This loss function is minimized via backpropagation, allowing the model to learn the correct probability distribution over the vocabulary for each token.
Common Challenges while pre-training LLMs
Pre-training large-scale language models presents several technical challenges that must be addressed to ensure effective and efficient model development:
- Computational Resource Demands: Pre-training state-of-the-art models necessitates extensive computational resources. The process typically involves distributed computing environments with numerous GPUs or TPUs. Efficient scaling and parallelization are crucial to manage the computational load and reduce training time.
- Data Acquisition and Processing: Securing and curating vast amounts of high-quality data is a significant challenge. The dataset must be comprehensive and diverse to cover a wide range of linguistic patterns and contexts. Data preprocessing and cleaning are essential to ensure the data is free from noise and irrelevant information.
- Training Duration: The time required for pre-training can be substantial, spanning from several days to weeks, depending on model size and hardware capabilities. Efficient training strategies and optimization techniques are necessary to balance performance with resource constraints.
Essentially, if we compromise on the size of the pre-training corpus model becomes very bad at generating text but if we decide to use a huge corpus it becomes really expensive to train the model.
One proven middle-ground is to use instruction-pre-training of LLMs instead of training them as usual. Instruction pre-training is a novel method that augments the unsupervised training corpus with instructions to enhance the model performance it is proven to be extremely effective notable when we perform domain-adaptive fine-tuning essentially your model can beat models 10x it’s size .
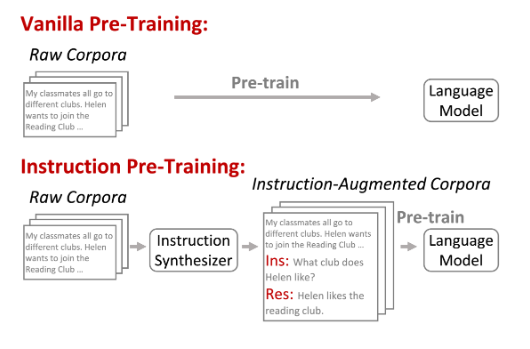
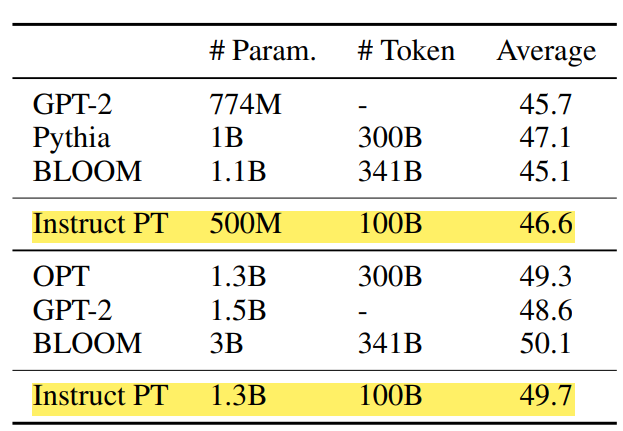
We can see that Instruction Pre-trained models on less tokens are able to outperform models underwent vanilla pre-training on a dataset that 3x more tokens. Another point to note here is that the instruction-pre-trained model was able to outperform models that has more parameters and trained on larger corpuses. By thinking about it Instruction pre-training is a win win for developers who struggle with hardware limitations and budget.
Monster API allows users to seamlessly convert their unlabeled corpus into Instruction augmented pre-training corpora suitable for pre-training. Let us see a tutorial on how to perform Instruction-pre-training of a model with an example.
The first step is to create an instruction-augmented dataset using the monster API’s Instruction synthesizer API:
import requests
url = "https://api.monsterapi.ai/v1/deploy/instruction-synthesizer"Take any pre-training corpora from the huggingface and specify an output dataset name like the example shown below.
payload = {
"model_name": "instruction-pretrain/instruction-synthesizer",
"temperature": 0,
"max_tokens": 400,
"batch_size": 2,
"seed": 42,
"input_dataset_name": "<INPUT DATASET PATH>(For example: RaagulQB/quantum-field-theory)",
"output_dataset_name": "<OUTPUT DATASET PATH>(For example: RaagulQB/quantum-field-theory-instruct)",
"hf_token": "<HF TOKEN>"
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer <MONSTER API TOKEN>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)Once everything is successful you can see the dataset on your huggingface page. Only thing left to do now is to convert the dataset into a txt file which is extremely straightforward. Once the text file is ready we are ready to pre-train.
Importing necessary Libraries:
import os
from types import SimpleNamespace
import torch
from torch import nn, optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
get_cosine_schedule_with_warmup
)
os.environ['TOKENIZER_PARALLELISM'] = 'false'
Setting up the hyperparameters.
cfg = {
'model_id': '<Name of the LLM for Pre-Training>',
'context_length': 1024,
'batch_size':4 ,
'num_epochs': 100,
'learning_rate': 0.00004,
'weight_decay': 0.01,
'seed': 252,
'logging_steps': 1,
'device': 'cuda' if torch.cuda.is_available else 'cpu'
}
cfg = SimpleNamespace(**cfg)
Load your corpus and prepare it for Training
data_file_path = <Path-To-Your-Txt-File>
with open(data_file_path, "r", encoding="utf-8") as file:
text_data = file.read()
Let us make use of the base model tokenizer for training
tokenizer = AutoTokenizer.from_pretrained(cfg.model_id)
Now let us create a Dataset and a dataloader for training.
class Dataset(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt)
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader(txt, tokenizer, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True, num_workers=0):
# Create dataset
dataset = Dataset(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=0
)
return dataloadertorch.manual_seed(seed=cfg.seed)
train_dataloader = create_dataloader(
txt=text_data,
tokenizer=tokenizer,
batch_size=cfg.batch_size,
max_length=cfg.context_length,
stride=cfg.context_length,
shuffle=True,
drop_last=True,
num_workers=1
)We can check the number of tokens in our pre-training corpus simply by
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("Characters:", total_characters)
print("Tokens:", total_tokens)config = AutoConfig.from_pretrained(cfg.model_id,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
device_map=cfg.device)
# print(f'config: {config} {type(config)}')
# Print the original number of parameters
model = AutoModelForCausalLM.from_config(config)
Define the optimizer and the learning rate scheduler.
torch.manual_seed(cfg.seed)
##################################################################
optimizer = torch.optim.AdamW(
model.parameters(),
lr=cfg.learning_rate,
weight_decay=cfg.weight_decay
)
scheduler = get_cosine_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=cfg.num_epochs*len(train_dataloader)
)
Write a custom training loop
for epoch in range(cfg.num_epochs):
for batch_idx, (input_batch, target_batch) in enumerate(train_dataloader):
model.train()
input_batch = input_batch.to(cfg.device)
target_batch = target_batch.to(cfg.device)
logits = model(input_batch).logits
loss = F.cross_entropy(
logits.flatten(0, 1),
target_batch.flatten()
)
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
if not (batch_idx % cfg.logging_steps):
print(
f'Epoch: {epoch+1}/{cfg.num_epochs}'
f' | Batch {batch_idx+1}/{len(train_dataloader)}'
f' | Loss: {loss.item():.4f}'
)
Once the pre-training is done one can save the model and use it for inference.
Summing Up
In this blog we have seen how to instruction-pre-train a model and pre-train it for your custom use case. We were able to achieve very good pre-training results and would love to here from you on your pre-training experiences.