
How to Fine-tune Open Source AI Models like LlaMa, Mistral, SDXL

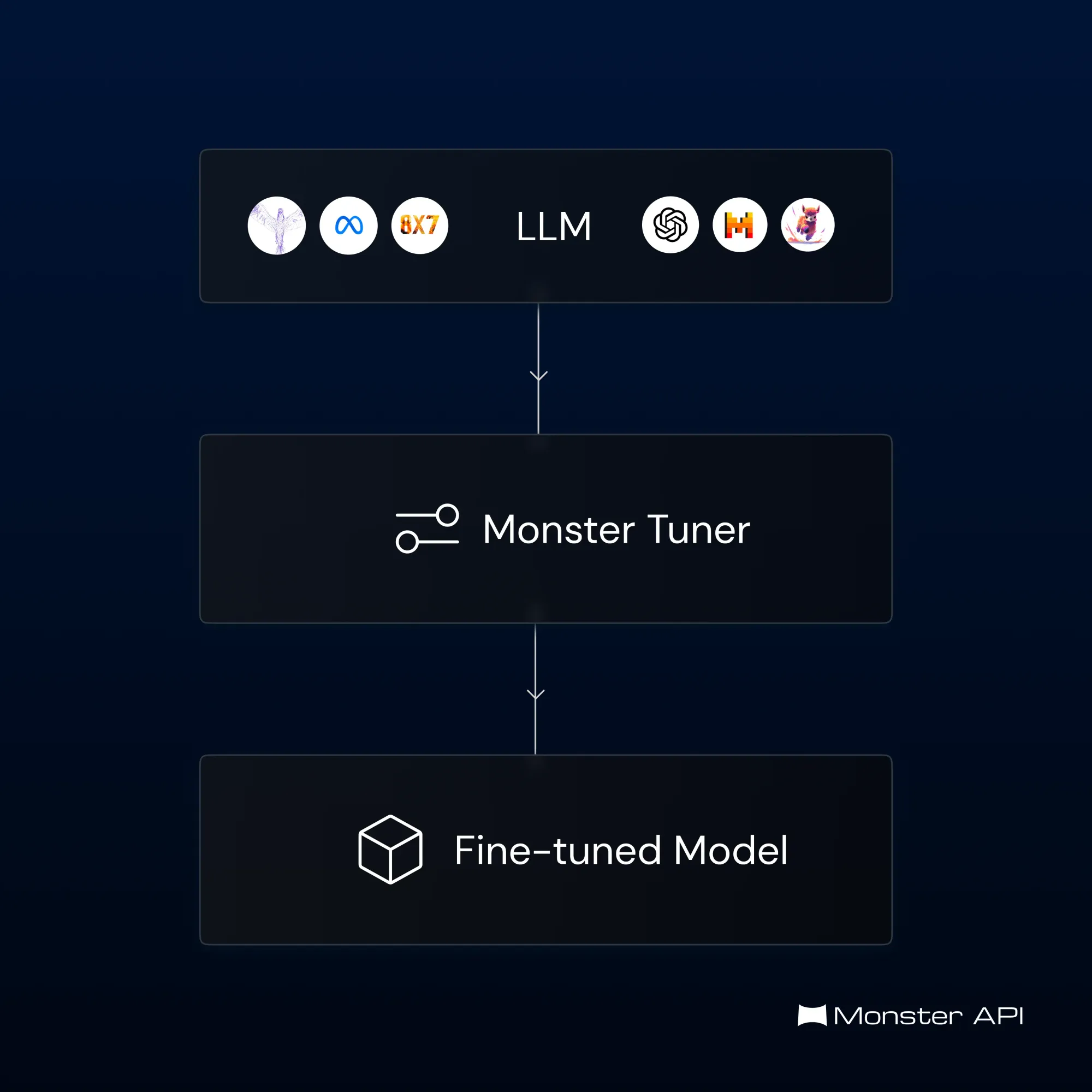
Fine-tuning is a technique in machine learning used to adapt a pre-trained model to a new and more specific task. It's like taking a highly trained athlete and giving them specialized coaching to excel in a particular sport.
In this blog, we will explore the various methods to build our own fine-tuned model and how we can deploy it.
Traditional methods to finetune LLMs
Traditionally, fine-tuning LLMs required multiple steps. Here’s a breakdown of all the steps:
- Prepare Dataset
When preparing training data for fine-tuning Large Language Models (LLMs), here’s a streamlined approach that you can follow:
- Define Task: Start by clearly defining the target task to guide dataset selection.
- Gather Data: Collect a diverse, representative corpus relevant to the task.
- Clean Data: Remove noise, inconsistencies, and irrelevant information for a structured dataset.
- Label Data: Ensure accurate and consistent labelling if supervised learning is required.
- Format Data: Convert data into a compatible format with the LLM, including tokenization and input structure adherence.
- Quality Focus: Choose a high-quality dataset closely matching the target task for optimal model performance.
Each step, though time-consuming, is essential for enhancing the LLM’s fine-tuning and task-specific effectiveness.
These days, we have dataset augmentation libraries such as DistilLabel that can be used to augment/extend an existing dataset or generate a complete synthetic dataset using pre-trained LLMs.
- Choosing the Finetuning Method:
When selecting the appropriate fine-tuning method for Large Language Models (LLMs), consider the following options:
Full Fine-Tuning: Retrain the entire LLM for maximum adaptability.
- Pros: Offers extensive customization and performance improvement.
- Cons: Needs large dataset corpus, Computationally expensive and time-consuming.
LoRA Adapter Fine-Tuning: Focus on low-rank adaptation by adjusting specific layers or components.
- Pros: More efficient and less resource-intensive compared to full fine-tuning.
- Cons: May offer less flexibility in adapting the model to highly specific tasks.
Few-Shot Learning: Use minimal labelled examples to adapt the model quickly.
- Pros: Requires significantly less data and computational resources.
- Cons: Might not achieve the same level of accuracy and depth as more intensive methods.
Each method has its own balance of computational cost and effectiveness. The choice depends on your specific task requirements, available resources, and desired model performance.
- Setup Training Environment:
Setting up the training environment for fine-tuning Large Language Models (LLMs) involves these key steps:
- Prepare GPU Server: Ensure the server has adequate GPU capacity and the compatible libraries and drivers installed (e.g., Cuda, PyTorch, TensorFlow).
- Configure Hyperparameters: Adjust learning rate, batch size, and other critical parameters based on the chosen fine-tuning method and GPU memory constraints.
- Develop Python Script: Write or modify the script to integrate your dataset, model, and chosen fine-tuning technique.
- Monitor and Optimize: Prepare a monitoring setup by integrating tools like WandB or AIM to track finetuning performance and tweak hyperparameters as needed to improve outcomes.
Properly setting up these components is crucial for efficient and effective model fine-tuning.
- Fine-tune Your Model:
Finally, actual training begins, which can take hours, days or even weeks depending on the model size, hardware resources, and complexity of the dataset.
3-Step LLM Finetuning with MonsterAPI
MonsterAPI provides a streamlined finetuning workflow for LoRA/QLoRA-based LLM finetuning, making the process a lot easier, cost-effective, and adaptable for developers with or without MLOps skills. Here’s a 3-step process overview:
- Data Upload & Configuration
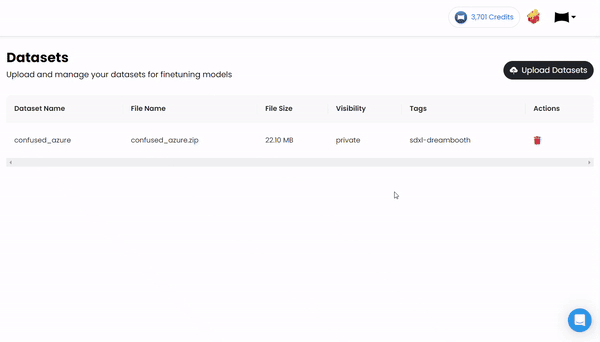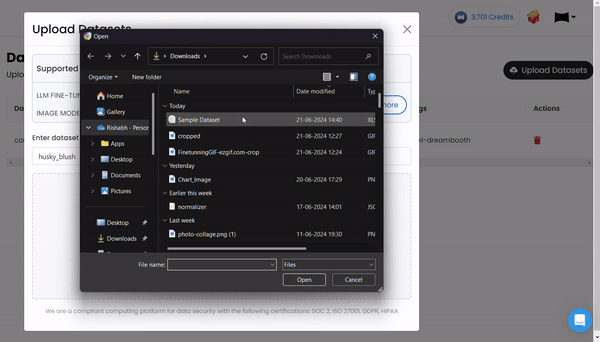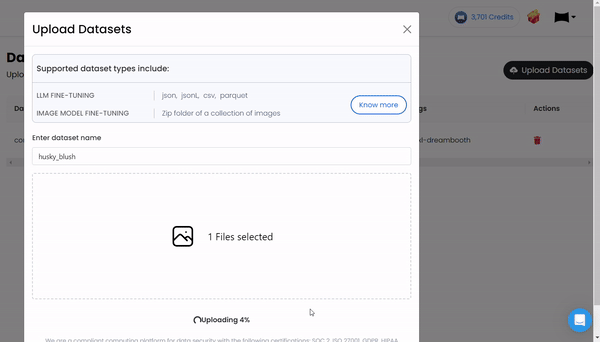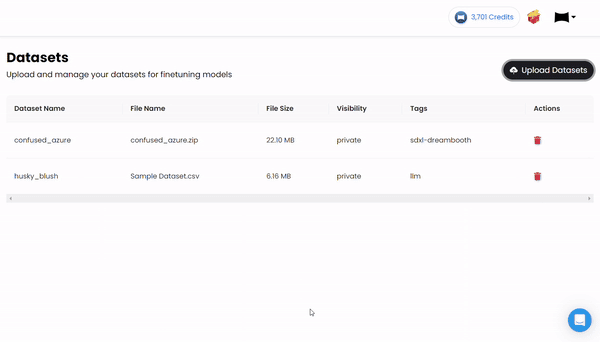
Simply upload your training data and specify your desired task such as chat completion, summarization, classification etc. MonsterAPI's platform takes care of the data pre-processing, including validation, and splitting it into training and validation sets.
- Model Selection & Fine-tuning

Select your preferred LLM from our library, which includes popular models like Llama 3, Phi 3, Qwen, Mixtral, Mistral for text generation, Whisper for speech processing, and SDXL for image generation.
MonsterAPI has designed a smart finetuning workflow that prioritizes cost-efficient fine-tuning by optimizing the complete pipeline with integrations such as Flash Attention 2, SDPA, auto batch sizing based on available GPU memory, auto-configuring with LoRA or QLoRA based on model size and finally performing the finetuning job on a low-cost GPU from MonsterAPI’s decentralized GPU cloud.
- Deployment and Integration:
Once fine-tuned, your LLM is ready to deploy. MonsterAPI provides easy integration with your existing applications through intuitive APIs. This allows you to use the power of your fine-tuned model in your workflow without having to manage complex infrastructure.
Different Methods for Finetuning
- Supervised Fine-Tuning
In this method, the model is trained on a task-specific labeled dataset, where each input data point is associated with a correct answer or label. The model learns to adjust its parameters to predict these labels as accurately as possible.
This process guides the model to apply its pre-existing knowledge, gained from pre-training on a large dataset, to the specific task at hand. Supervised fine-tuning can significantly improve the model's performance on the task, making it an effective and efficient method for customizing LLMs.
The most common supervised fine-tuning techniques are:
- Basic hyperparameter tuning
Basic hyperparameter tuning is a simple approach that involves manually adjusting the model hyperparameters, such as the learning rate, batch size, and the number of epochs, until you achieve the desired performance.
The goal is to find the set of hyperparameters that allows the model to learn most effectively from the data, balancing the trade-off between learning speed and the risk of overfitting. Optimal hyperparameters can significantly enhance the model's performance on a specific task.
- Transfer learning
Transfer learning is a powerful technique that’s particularly beneficial when dealing with limited task-specific data. In this approach, a model pre-trained on a large, general dataset is used as a starting point.
The model is then fine-tuned on the task-specific data, allowing it to adapt its pre-existing knowledge to the new task. This process significantly reduces the amount of data and training time required and often leads to superior performance compared to training a model from scratch.
- Multi-task learning
In multi-task learning, the model is fine-tuned on multiple related tasks simultaneously. The idea is to leverage the commonalities and differences across these tasks to improve the model's performance. The model can develop a more robust and generalized understanding of the data by learning to perform multiple tasks simultaneously.
This approach leads to improved performance, especially when the tasks it will perform are closely related or when there is limited data for individual tasks. Multi-task learning requires a labeled dataset for each task, making it an inherent component of supervised fine-tuning.
- Few-shot learning
Few-shot learning enables a model to adapt to a new task with little task-specific data. The idea is to leverage the vast knowledge model has already gained from pre-training to learn effectively from just a few examples of the new task. This approach is beneficial when the task-specific labeled data is scarce or expensive.
In this technique, the model is given a few examples or "shots” during inference time to learn a new task. The idea behind few-shot learning is to guide the model's predictions by providing context and examples directly in the prompt.
Few-shot learning can also be integrated into the reinforcement learning from human feedback (RLHF) approach if the small amount of task-specific data includes human feedback that guides the model's learning process.
- Task-specific fine-tuning
This method allows the model to adapt its parameters to the nuances and requirements of the targeted task, thereby enhancing its performance and relevance to that particular domain. Task-specific fine-tuning is particularly valuable when you want to optimize the model's performance for a single, well-defined task, ensuring that the model excels in generating task-specific content with precision and accuracy.
Task-specific fine-tuning is closely related to transfer learning, but transfer learning is more about leveraging the general features learned by the model, whereas task-specific fine-tuning is about adapting the model to the specific requirements of the new task.
- Reinforcement Learning from Human Feedback (RLHF)
Reinforcement learning from human feedback (RLHF) is an innovative approach that involves training language models through interactions with human feedback. By incorporating human feedback into the learning process, RLHF facilitates the continuous enhancement of language models so they produce more accurate and contextually appropriate responses.
This approach not only leverages the expertise of human evaluators but also enables the model to adapt and evolve based on real-world feedback, ultimately leading to more effective and refined capabilities.
The most common RLHF techniques are:
- Reward modeling
In this technique, the model generates several possible outputs or actions, and human evaluators rank or rate these outputs based on their quality. The model then learns to predict these human-provided rewards and adjusts its behavior to maximize the predicted rewards.
Reward modeling provides a practical way to incorporate human judgment into the learning process, allowing the model to learn complex tasks that are difficult to define with a simple function. This method enables the model to learn and adapt based on human-provided incentives, ultimately enhancing its capabilities.
- Proximal policy optimization
Proximal policy optimization (PPO) is an iterative algorithm that updates the language model's policy to maximize the expected reward. The core idea of PPO is to take actions that improve the policy while ensuring the changes are not too drastic from the previous policy. This balance is achieved by introducing a constraint on the policy update that prevents harmful large updates while still allowing beneficial small updates.
This constraint is enforced by introducing a surrogate objective function with a clipped probability ratio that serves as a constraint. This approach makes the algorithm more stable and efficient compared to other reinforcement learning methods.
- Comparative ranking
Comparative ranking is similar to reward modeling, but in comparative ranking, the model learns from relative rankings of multiple outputs provided by human evaluators, focusing more on the comparison between different outputs.
In this approach, the model generates multiple outputs or actions, and human evaluators rank these outputs based on their quality or appropriateness. The model then learns to adjust its behavior to produce outputs that are ranked higher by the evaluators.
By comparing and ranking multiple outputs rather than evaluating each output in isolation, comparative ranking provides more nuanced and relative feedback to the model. This method helps the model understand the task subtleties better, leading to improved results.
- Preference learning (reinforcement learning with preference feedback)
Preference learning, also known as reinforcement learning with preference feedback, focuses on training models to learn from human feedback in the form of preferences between states, actions, or trajectories. In this approach, the model generates multiple outputs, and human evaluators indicate their preference between pairs of outputs.
The model then learns to adjust its behavior to produce outputs that align with the human evaluators' preferences. This method is useful when it is difficult to quantify the output quality with a numerical reward but easier to express a preference between two outputs. Preference learning allows the model to learn complex tasks based on nuanced human judgment, making it an effective technique for fine-tuning the model on real-life applications.
- Parameter efficient fine-tuning
Parameter-efficient fine-tuning (PEFT) is a technique used to improve the performance of pre-trained LLMs on specific downstream tasks while minimizing the number of trainable parameters. It offers a more efficient approach by updating only a minor fraction of the model parameters during fine-tuning.
PEFT selectively modifies only a small subset of the LLM's parameters, typically by adding new layers or modifying existing ones in a task-specific manner. This approach significantly reduces the computational and storage requirements while maintaining comparable performance to full fine-tuning.
Common challenges with LLM finetuning (how MonsterAPI can help)
Fine-tuning LLMs can be a complex and difficult process. Here's where MonsterAPI excels:
- Data Challenges: MonsterAPI's data pre-processing capabilities ensure that your data is properly formatted for optimal training, saving you time and resources.
- Hyperparameter Tuning: Choosing the appropriate hyperparameters can make or break your fine-tuning. MonsterAPI provides pre-defined options based on best practices, or you can use the automated hyperparameter tuning capabilities to optimize for your specific dataset.
- Computational Bottlenecks: Training LLMs can be computationally expensive. MonsterAPI uses its high-performance infrastructure to shorten training times, allowing you to deploy your fine-tuned model faster.
- Deployment and Integration: MonsterAPI's user-friendly APIs make it simple to integrate your fine-tuned model into your applications.
- Time Constraints: Training LLMs from scratch or with substantial fine-tuning can be extremely time-consuming, sometimes requiring days or weeks. This can cause major delays in project timelines. MonsterAPI allows you to fine-tune your model more quickly and precisely.
FAQs
- What type of data is required for fine-tuning?
The data format depends on your specific task. Text-based models require labeled text data relevant to the desired outcome. Image datasets and text descriptions are required for image generation models.
- How long does it take to fine-tune?
Training times vary depending on model size, dataset complexity, and hyperparameter selection. MonsterAPI's infrastructure significantly reduces training times.
- Can I fine-tune multiple models?
Absolutely! MonsterAPI allows you to try out different LLM architectures and compare their performance on your task.
- Can MonsterAPI support curriculum learning techniques for staged training on increasingly complex data?
Yes, MonsterAPI can be configured to leverage curriculum learning approaches.
- When fine-tuning, which method is better for preventing exploding gradients, and does MonsterAPI offer options for both?
MonsterAPI allows you to choose between gradient clipping and weight decay during fine-tuning to manage gradients effectively.
Conclusion
LLMs can be optimized to realize their best capability. MonsterAPI's streamlined approach allows you to tap into its potential. Not just developers, but anyone may use the intuitive UI to fine-tune and deploy the model. MonsterAPI simplifies the entire process, from data pre-processing to deployment, enabling you to focus on what's most important: creating breakthrough applications with the power of fine-tuned LLMs.