
Accelerating Learning with Grokkfast: Now Available in MonsterAPI
Grokkfast is designed to speed up the generalization process in neural networks, particularly in scenarios where traditional optimizers might struggle or take longer to converge.

We're excited to announce that we've implemented Grokkfast, a cutting-edge optimization algorithm, in our MonsterAPI finetuning platform. This new addition aims to accelerate the learning process and improve model performance.
What is Grokkfast?
Grokkfast is an innovative optimization technique introduced in the paper "Grokfast: Accelerated Grokking by Amplifying Slow Gradients" by Lee et al. It's designed to speed up the generalization process in neural networks, particularly in scenarios where traditional optimizers might struggle or take longer to converge.
Understanding Grokkfast
The key insight behind Grokkfast is treating the training process as a collection of discrete random signals over time. By analyzing these signals in the frequency domain, the authors identified two components of parameter updates:
- Fast-varying components that contribute to rapid overfitting
- Slow-varying components that contribute to generalization
Grokkfast works by amplifying these slow-varying components, effectively accelerating the generalization process.
How Grokkfast Works
The Grokkfast algorithm modifies existing optimizers by applying a low-pass filter to the gradients. This is achieved through two main approaches:
- GROKFAST-MA: Uses a moving average filter
- GROKFAST-EMA: Uses an exponential moving average filter (this is the primary implementation we've adopted).
The filtered gradients are then added back to the original gradients before being fed into the optimizer. This simple modification can lead to significant improvements in training speed and performance.
Our Implementation
We've integrated Grokkfast into MonsterAPI, making it available as an optimizer option for all users. This implementation allows you to leverage the potential benefits of Grokkfast in your machine-learning projects with minimal code changes.
Experimental Results
The initial experiments with Grokkfast pretraining have shown promising results across various tasks:
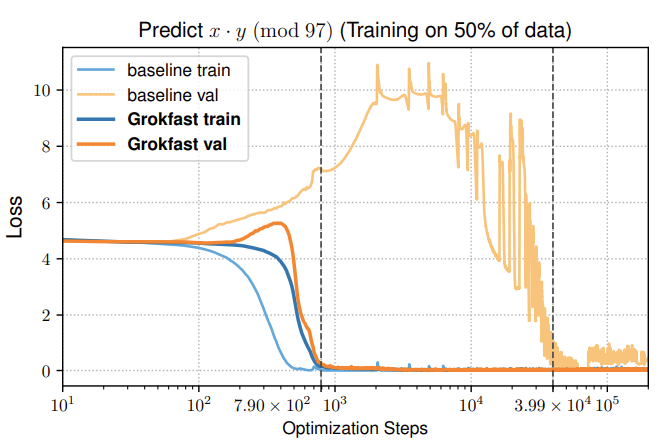
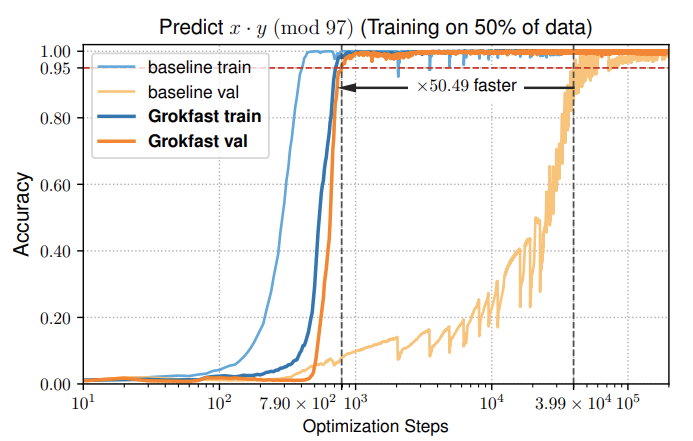
- Algorithmic Tasks: For a modular multiplication task, Grokkfast achieved generalization up to 50 times faster than the baseline.
- Image Classification (MNIST): Grokkfast reduced the number of iterations to reach 95% validation accuracy by 22 times.
- Molecule Property Prediction (QM9): Grokkfast achieved faster convergence and lower validation loss compared to the baseline.
- Sentiment Analysis (IMDb): Grokkfast improved both convergence speed and final model performance.
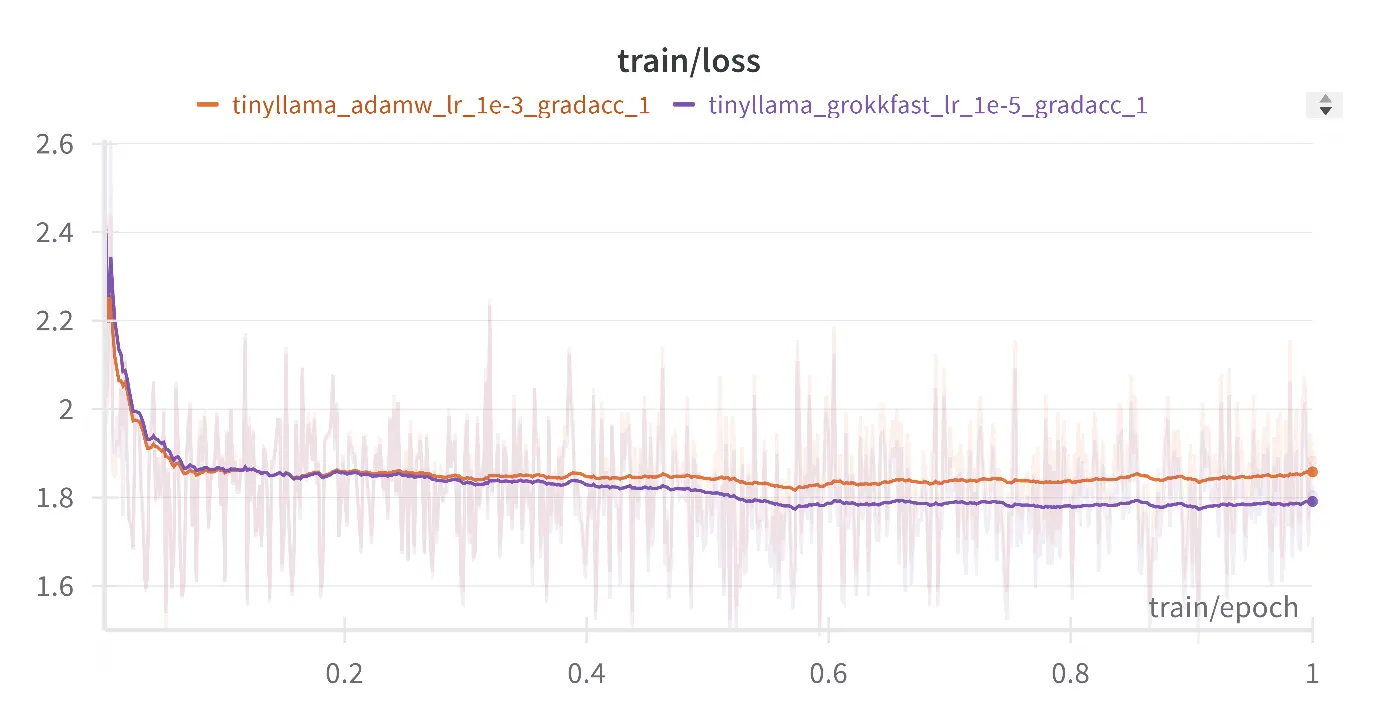
While the improvements vary depending on the task, model architecture, and whether you're finetuning or training from scratch, we've consistently observed benefits. The most significant gains appear when training models from scratch or tackling more challenging problems. However, even in finetuning scenarios, the 5-10% improvement can be valuable, especially for production models where small performance gains can have meaningful impacts.
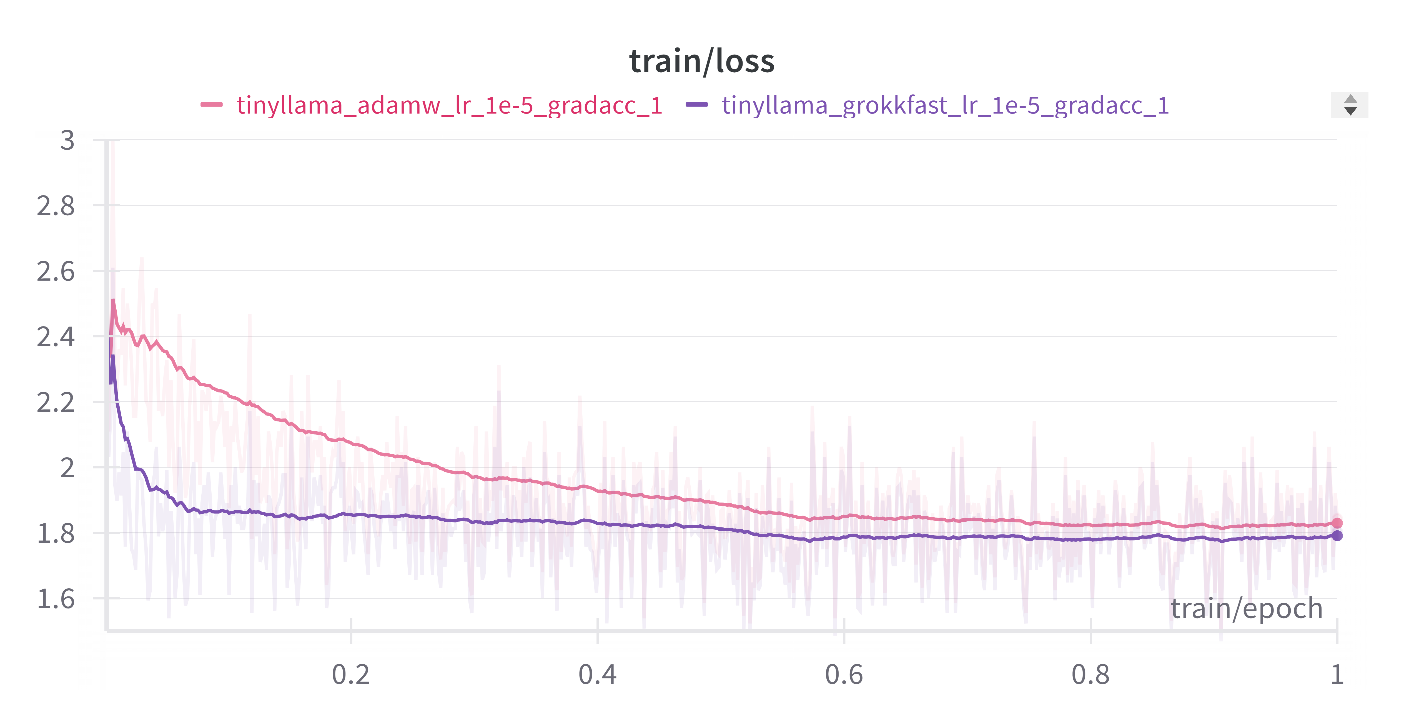
Our results with the same learning rate of 1e-5 for both AdamW and GrokAdamW
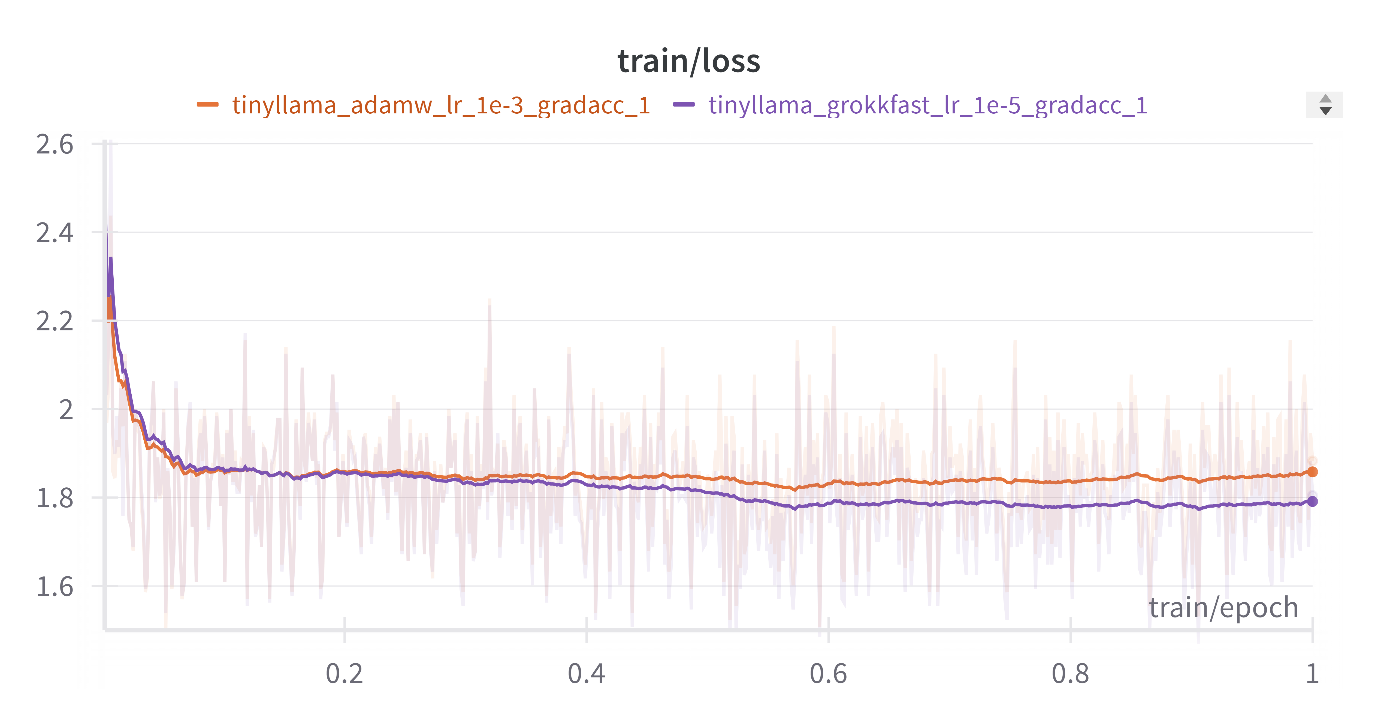
Best case scenario with optimized Learning rates for AdamW and Grokkfast
These results suggest that Grokkfast can be a versatile tool in your machine learning toolkit, offering benefits across a range of scenarios from fine tuning to training from scratch.
How to Use Grokkfast in MonsterAPI
To use Grokkfast in your projects:
To start using Grokkfast in your finetuning jobs, follow these steps:
- Use the finetuning endpoint: https://api.monsterapi.ai/v1/finetune/llm
- Set the payload as shown in the example below, which includes your model configurations, data settings, and training parameters. Make sure you have your Hugging Face (HF) key and Weights & Biases (W&B) key handy for logging purposes. Here's an example payload:
{
"deployment_name": "\"Null\"",
"pretrainedmodel_config": {
"model_path": "google/gemma-2-2b-it",
"use_lora": true,
"lora_r": 128,
"lora_alpha": 256,
"lora_dropout": 0.0,
"lora_bias": "none",
"parallelization": "nmp"
},
"data_config": {
"data_path": "gvij/english-to-hinglish",
"data_source_type": "hub_link",
"cutoff_len": 512,
"data_split_config": {
"train": 1,
"validation": 0.0
}
},
"training_config": {
"num_train_epochs": 1.0,
"learning_rate": 0.001,
"hf_login_key": "YOUR_API_KEY",
"optimizer": "grokadamw"
},
"logging_config": {
"use_wandb": true,
"wandb_login_key": "YOUR_API_KEY",
"wandb_project": "hindi-to-hinglish"
}
}
- Send the payload to the endpoint, and your finetuning job will start automatically.
Conclusion
The integration of Grokkfast into MonsterAPI represents our commitment to providing cutting-edge tools for our users. Its ability to accelerate generalization, especially in challenging scenarios, makes it a valuable addition to our platform.
We encourage you to try Grokkfast in your projects, particularly if you're working on complex tasks, training from scratch, or dealing with scenarios where traditional optimizers struggle to generalize quickly.
As always, we're eager to hear about your experiences and results. Happy training!