
Finetuning LLaMA 70B with No-Code: Results, Methods, and Implications


In this blog post, we will demonstrate how you can effortlessly fine-tune the LLaMA 2 - 70B model at a fraction of the cost of $57.75 with just a few clicks, utilising the No-Code LLM-Finetuner from Monster API.
Download the Fine-Tuned Model weights from Hugging Face
Background
LLaMA 2 is an impressive family of Large Language Models (LLMs) released by Meta AI, encompassing a staggering range from 7B to 70B parameters (7B, 13B, 70B). These newer iterations follow the already remarkable LLaMA 1, presenting a refined and enhanced version that has captivated the entire Natural Language Processing (NLP) community.
With a vast corpus that outpaces its predecessor by 40% in token count, LLaMA 2 models exhibit a profound understanding of context, with a good enough context length of 4K tokens.
What is Databricks Dolly V2 dataset?
The Databricks Dolly V2 dataset, specifically the "data bricks-dolly-15k" corpus, is a collection of over 15,000 records created by Databricks employees. The purpose of this dataset is to enable LLMs, to demonstrate interactive and engaging conversational abilities like ChatGPT.

Key Outcomes
The results of our fine-tuning job turned out to be impressive, as the model learned and adapted to the chosen task of "Instruction-finetuning" on the specified dataset.
We were able to fine-tune LLaMA 2 - 70B Model on Dolly v2 Dataset for 1 epoch for as low as $19.25 using MonsterTuner.
The outcome of fine-tuning using Monster API for the LLaMA 2 - 70B Model on the Dolly v2 Dataset for 3 epochs lasting over 17.5 hours resulted in good loss results.
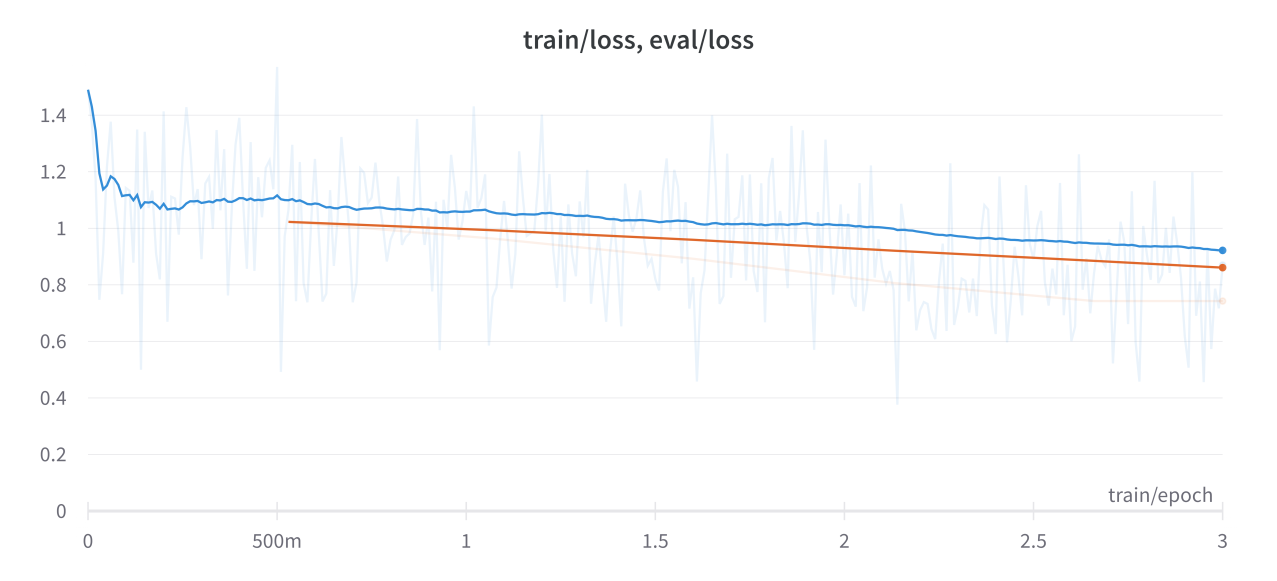
For a comprehensive visual representation of our fine-tuning progress, we've included WandB Metrics, showcasing the training loss and evaluation loss.
Train and Evaluation Loss Curve -
These loss results illustrate the successful fine-tuning of the model, with the training and evaluation loss indicating substantial progress and improvement in the model's performance.
Performance Metrics and Cost Benefits
Let us assess the improvements achieved in responses to the Llama 70B model by finetuning it.
Benchmark charts and evaluation -
- ARC Challenge (AI2 Reasoning Challenge): This test assesses a model’s ability to answer complex questions using reasoning skills. The model scored 0.5485, indicating decent accuracy on challenging questions.
- Hellaswag (Common-Sense Reasoning): This task measures a model's capacity to predict the next sensible sentence in a given context. The model achieved a good score of 0.7350, showcasing fine common-sense reasoning abilities.
- TruthfulQA (Factual Accuracy): This evaluation assesses the model's accuracy in providing truthful and factually correct answers to questions. The model received a score of 0.4920, demonstrating its capability to provide reliable and accurate answers.
These results offer a concise summary of the model's performance due to finetuning in each task, highlighting its proficiency in complex reasoning, common-sense understanding, and factual accuracy.
Fine-Tuned Model v/s Base Model performance on same prompts -
Q1: Question: Explain Artificial Neural Networks to me as though I am 5 years old
Q2: Question: Do you have intelligence are you a living being?
From these examples, it's evident that fine-tuning has added structure to the responses.
Cost and time efficiencies achieved
The cost analysis of fine-tuning Llama 2 on MonsterAPI also emphasizes the cost-effectiveness and efficiency of this approach compared to traditional cloud platforms:
Cost Savings: Fine-tuning Llama 2 on MonsterAPI costs just $57.75 for 3 epochs, compared to nearly $98 on traditional cloud platforms. This results in 1.7X cost-effective finetuning.
Efficiency: MonsterAPI's no-code LLM finetuner reduces both time and manual effort by automatically figuring out the most optimal hyperparameters and deploying them on appropriate GPU infrastructure without you having to set it up. Thus, streamlining the complete fine-tuning pipeline.
The No-Code Approach
Limitations of Standard Fine-Tuning:
Standard fine-tuning an LLM can be challenging due to complex setups, substantial GPU memory requirements, high GPU costs, and a lack of standardized methodologies.
Overview of Our No-Code Fine-Tuning Method:
MonsterAPI's no-code fine-tuning method represents a breakthrough in simplifying the fine-tuning process for language models. It encompasses several key elements:
- Simplified Setup: Monster API eliminates the need for developers to go through the intricate process of manually configuring GPUs and managing software dependencies.
- Optimized Memory Utilization: The Monster API FineTuner is designed to efficiently utilize GPU memory, thus resulting in a lower cost of execution.
- Low-Cost GPU Access: Monster API provides access to its decentralized GPU network, offering users on-demand access to affordable GPU instances.
- Standardized Workflow: Monster API streamlines the fine-tuning process by offering predefined tasks and recipes with optimal hyperparameters and an optimized orchestration pipeline for handling finetuning jobs at scale.
In summary, Monster API's no-code fine-tuning method is designed to make the complex process of fine-tuning language models more accessible and efficient. It removes technical barriers, optimizes resource utilization, reduces costs, and provides a standardized framework, making it easier for developers to leverage the full potential of large language models in their applications.
Future Directions
Our upcoming tool, QuickServe Beta, will play a pivotal role in completing the finetuning pipeline and thus enabling easy, affordable, and scalable deployments of fine-tuned models. We aim to support universal compatibility, flexible scaling, and easy deployment of various vLLM-compatible models. Our broader goal is to help the AI community by providing cost-effective and efficient solutions for deploying language models and Docker images, encouraging innovation in AI applications.
Summarizing the Significance of Our No-Code Fine-Tuning
Our no-code fine-tuning approach is a game-changer, simplifying the complex process of fine-tuning language models. It reduces setup complexity, optimizes resource usage, and minimizes costs.
This makes it easier for developers to harness the power of large language models, ultimately driving advancements in natural language understanding and AI applications.
Encouraging Further Research and Collaboration
We invite the AI community to explore our tools, provide feedback, and collaborate on further research. Monster API is committed to working with researchers and developers to advance AI technologies. We believe that by coming together, we can unlock new possibilities and drive innovation in AI.
Ready to finetune an LLM for your business needs?
Sign up on MonsterAPI to get free credits and try out our no-code LLM Finetuning solution today!
Check out our documentation on Finetuning an LLM.