
How to Fine-tune a Large Language Model
A comprehensive guide with fundamental concepts on how to fine-tune a large language model in 2024.


This comprehensive guide walks you through the fundamental concepts of fine-tuning a large language model (LLM) and then will also walk you through the process of finetuning an LLM using MonsterAPI with a google colab example.
What is LLM fine-tuning?
Fine-tuning Large Language Models (LLMs) is crucial for tailoring pre-trained models to perform specific tasks with higher precision. LLMs like GPT, initially trained on extensive datasets, excel at understanding and generating human-like text. However, their broad training often lacks the specificity needed for specialized applications.
Fine-tuning addresses this by further training these pre-trained models on domain-specific datasets. This process refines the model’s capabilities, enhancing its performance in tasks such as sentiment analysis, question answering, and document summarization. Fine-tuning not only lowers computational costs but also leverages state-of-the-art models without the need to build them from scratch.
Fine-tuning is particularly effective at teaching an LLM domain expertise–such as classifying legal documents–or adapting an LLM to a specific tone or style of communication.
Different LLM Fine-tuning approaches:
There are several fine-tuning methods and techniques used to adjust the model parameters to a given requirement. Broadly, we can classify these methods in two categories:
- Supervised fine-tuning, and
- Reinforcement learning from human feedback (RLHF).
Supervised fine-tuning:
Supervised fine-tuning involves training a pre-trained model on a task-specific labeled dataset, allowing it to adjust its parameters to predict these labels accurately. This method leverages the model's pre-existing knowledge to enhance its performance on specific tasks. Here are the different approaches:
📌 Transfer Learning
In transfer learning, a model pre-trained on a large, general dataset is fine-tuned on task-specific data. This method is especially useful when dealing with limited task-specific data, as it reduces the amount of data and training time required. By adapting its pre-existing knowledge, the model achieves superior performance compared to training from scratch.
📌 Multi-task Learning
Multi-task learning fine-tunes the model on multiple related tasks simultaneously. By leveraging the commonalities and differences across these tasks, the model develops a more robust understanding of the data. This approach improves performance, especially when tasks are closely related or data is limited for individual tasks.
📌 Few-shot Learning
Few-shot learning enables the model to adapt to new tasks with minimal task-specific data. By providing a few examples during inference, the model leverages its vast pre-trained knowledge to learn effectively from limited data. This method is beneficial when labeled data is scarce or expensive. It can also be integrated with reinforcement learning from human feedback (RLHF).
📌 Task-specific Fine-tuning
This approach fine-tunes the model to the nuances of a particular task, optimizing its performance for that specific domain. Task-specific fine-tuning ensures the model excels in generating precise and accurate task-specific content. While similar to transfer learning, task-specific fine-tuning focuses more on adapting the model to the exact requirements of the new task.
Reinforcement Learning from Human Feedback (RLHF):
This approach enhances language models through human interaction.
Here are the methods of doing RLHF:
📌 Reward Modeling:
The model generates outputs, human evaluators rate them, and the model learns to maximize these ratings. This incorporates human judgment for complex tasks.
📌 Proximal Policy Optimization (PPO):
An iterative algorithm that updates the model's policy to maximize rewards while ensuring updates are not too drastic, enhancing stability and efficiency.
📌 Comparative Ranking:
Human evaluators rank multiple outputs, and the model learns to produce higher-ranked outputs, providing nuanced feedback and improving task understanding.
📌 Preference Learning:
Human evaluators indicate preferences between outputs, and the model adjusts to align with these preferences, allowing learning from nuanced human judgments.
Main challenges of fine-tuning an LLM:
📌 Full fine-tuning involves adjusting all the model's weights, which can be time-consuming due to the need to compute gradients across all weights to minimize the loss between the actual and generated outputs. This process involves billions of floating-point computations and constant data movement within the GPU memory hierarchy.
📌 Fine-tuning is also memory-intensive, requiring storage of both gradients and optimizer states, effectively doubling memory requirements. For example, using the Adam optimizer typically requires three times the model size in GPU RAM during the backward pass. This allocation accounts for storing all model parameters and additional optimizer state information (two floats per parameter). Therefore, if your model fits within an NVIDIA A10G GPU, training might require four such GPUs.
Low-Rank Adaptation (LoRA) to the rescue:
Fine-tuning made fast and efficient
Adapters provide a solution by enabling the LLM to adjust to new scenarios without altering its original parameters. This approach preserves the LLM's general knowledge and prevents catastrophic forgetting during new task learning. Adapters also minimize the number of parameters that need updating, cutting down the time and compute required—training overhead can be reduced by up to 70% compared to full fine-tuning.
First, what is LoRA and how does it work?
As explained earlier, when we finetune a language model, we modify the underlying parameters of the model. The core idea behind LoRA is to model this update to the model’s parameters with a low-rank decomposition, implemented in practice as a pair of linear projections.
LoRA modifies the self-attention and feed-forward layers of a transformer model by introducing low-rank matrices. This adaptation significantly reduces the number of trainable parameters during fine-tuning. This means that instead of updating the large dense weight matrices, only the smaller low-rank matrices are trained and updated. This reduces the amount of memory and the compute-resources needed since the low-rank matrices have significantly fewer parameters than the original dense matrices.
The low-rank approach scales well with the size of LLMs. As models become larger, the proportional increase in the parameters needed for LoRA remains much smaller compared to full model fine-tuning. Furthermore, LoRA can be selectively applied to specific layers or parts of layers (like attention scores or output layers), allowing for targeted and efficient adaptation.
💡 The mathematics underlying the LoRA concept
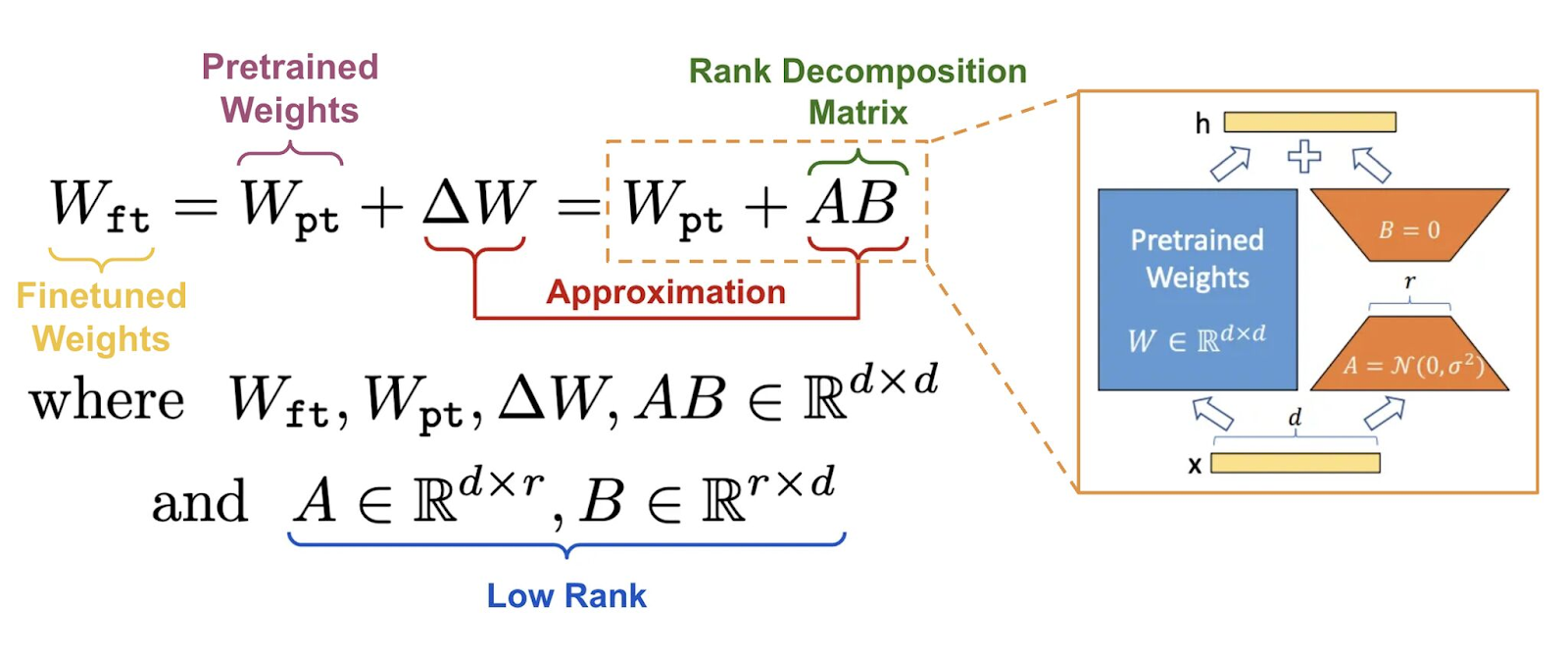
In LoRA the changes in the original weight matrix W is adapted by adding a low-rank product of two smaller matrices AB, where A and B are the low-rank matrices. So, the adapted weight matrix becomes W + AB.
These matrices are the core components of LoRA's adaptation mechanism. They are much smaller compared to the original weights and directly influence how the original weights are adapted during training.
i.e. with LoRA, the fine-tuned weight W′ can be represented as:
👉 W′ = W_0 + ∆W = W_0 + AB
Where W_0 remains static during the fine-tuning process, and the underlined parameters are being trained. The matrix A is initialized with uniform Kaiming distribution, while B is initially set to zero, resulting in ∆W = AB being zero at the start of training.
When finetuning with LoRA, the original weights W are frozen, and only the elements of the low-rank matrices B and A are trained, leading to a drastic reduction in the trainable parameter count.
The Benefits of LoRA are plentiful
- A single pretrained model can be shared by several (much smaller) LoRA modules that adapt it to solve different tasks.
- LoRA modules can be “baked in” to the weights of a pretrained model to avoid extra inference latency, and we can quickly switch between different LoRA modules to solve different tasks (i.e., "hot swapping").
- We only have to maintain the optimizer state for a very small number of parameters, which significantly reduces memory overhead.
- Finetuning with LoRA is faster than end-to-end finetuning (i.e., roughly 25% faster in the case of GPT-3).
- In a study published in 2021, LoRA was evaluated against complete fine-tuning of RoBERTa and DeBERTa across various benchmarks. The results indicated comparable performance levels overall, with slight superiority of full fine-tuning observed in tasks such as SST-2 (sentiment analysis). Conversely, in tasks like MNLI and on average, LoRA demonstrated superior performance compared to full fine-tuning specifically on DeBERTa.
Setting hyperparameters during finetuning
An LLM’s hyperparameters are important because they offer a controllable way to tweak a model’s behavior to produce the outcome desired for a particular use case.
Batch sizes: Small batch sizes require less memory during training but lead to more noisy model updates. Just like in regular deep learning, the batch size is a trade-off and hyperparameter to experiment with when training LLMs.
Learning Rate (LR): The learning rate is a crucial hyperparameter for any model, including LLMs. A conservative approach is to start with a learning rate of 2e-5 (2 x 10^-5) and use a cosine schedule with a 0.1 warmup ratio.
Number of Epochs: For finetuning LLMs, it's suggested to start with 3 epochs. This number can be adjusted based on the specific needs of the model and the data it's being trained on.
LR Sensitivity: Finetuning is more robust to learning rate changes than parameter-efficient methods like LoRA. Therefore, it's important to tune the learning rate carefully to achieve the best performance.
Parameter-Efficient Finetuning: For parameter-efficient finetuning, techniques like LoRA (Low-Rank Adaptation) are recommended. This allows for a more efficient use of resources while still achieving good performance. Also note, full finetuning is a lot more robust to LR than LoRA is.
Gradient Clipping: Apply gradient clipping to limit the magnitude of gradients during backpropagation. This prevents exploding gradients and stabilizes the training process.
Max Output Tokens: Typically, the higher you set the max output tokens, the more coherent and contextually relevant the model’s response will be. Subsequently, in contrast, setting a lower max token limit requires less processing power and memory, but in potentially not providing the model with sufficient room to craft the optimal response, you leave the door open for incoherence and errors.
Top-k and Top-p sampling: These two hyperparams provide helpful ways to control the balance between diversity, coherence, and "adventurousness" in the model's outputs:
Top-k (an integer that ranges from 1 to 100 with a default value of 50) sampling limits the model to considering only the k most likely next tokens at each step. A higher k allows for more diverse and unexpected outputs, while a lower k constrains the model to safer, more probable choices.
Top-p sampling (also called nucleus sampling) is a decimal number in the range of 0.0 to 1.0 and it selects from the smallest set of next tokens whose cumulative probability exceeds a threshold p. This allows for dynamic adjustment of the candidate pool based on the shape of the probability distribution.
Temperature: Temperature performs a similar function to the above-described top-k and top-p sampling values, providing a way to vary the range of possible output tokens and influence the model’s “creativity”.
I've often had success with k in the 10-40 range and p around 0.90-0.95 as starting points. For temperature, 0.7 is a common default but I'll often tune it down to 0.2-0.5 for a more conservative generation.
Some rule-of-thumb when using Supervised fine-tuning (SFT)
- Apply Packing to combine samples up to a sequence length (2048),
- Try Global Batch Size of 256/512, Use Flash Attention v2 with bf16 & tf32
- Enable gradient checkpointing to save memory
- Opt for “adamw_torch_fused” (10% speed up) or “adamw_torch” optimizer
- Deepspeed & FSDP both work well for distributed training
- Consider LoRA for quicker iterations with less compute
Setting hyperparameters specific to LoRA powered LLM finetuning?
Choose the Rank (r) and Alpha (α):
Rank (r) determines the dimensionality of the low-rank matrices. Smaller values lead to less memory and computation usage but might reduce model expressiveness. As this value is increased, the number of parameters needed to be updated during the low-rank adaptation increases.
Alpha (α) scales the low-rank matrices. Typical values are set based on the ratio of the original hidden dimension to the low-rank dimension. Common practice is setting α=2/r
`target_modules`: are the names of modules LoRA is applied to, like e.g. query, key and value which are the names of inner layers of self attention layer from Transformer Architecture.
So the `target_layers` are the layers that contribute the most to the model’s size and computational cost, such as the query and value projection matrices in the multi-head self-attention mechanism. 🏋️ This is due to the matrix multiplication operations required for their computation and the subsequent operations in the attention mechanism 🏋️
For each target layer, a low-rank approximation is computed with methods, such as singular value decomposition (SVD) or other matrix factorization techniques. The objective is to find two smaller matrices whose product closely approximates the original weight matrix in the target layer.
`bias`: Bias can be ‘none’, ‘all’ or ‘lora_only’. If ‘all’ or ‘lora_only’, the corresponding biases will be updated during training. The default is None.
Preparing the right dataset format for finetuning
The dataset needs to be prepared in the right format to ensure that the model learns the right values and parameters. Below we discuss the 3 most common dataset formats that we come across while finetuning.
1. Preparing a regular instruction finetuning dataset
The Instruction models are typically trained on datasets where the model is provided with explicit instructions alongside the input data. This data might include a command or a series of steps that the model needs to follow.
Here's an example implementation.
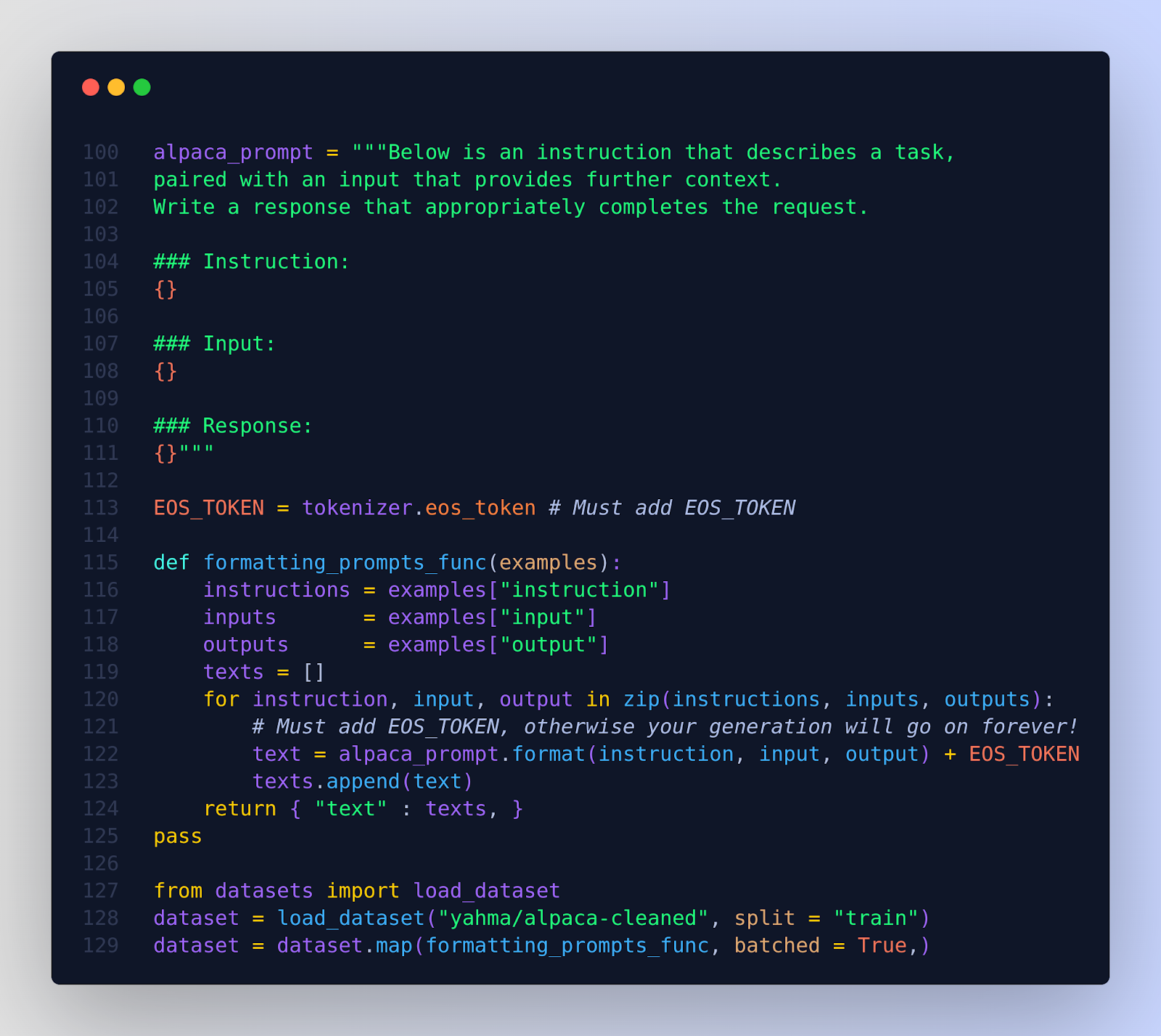
The method `formatting_prompts_func` processes data entries from a dataset, each containing three fields: `instruction`, `input`, and `output`. It formats these fields into a template string stored in the variable `alpaca_prompt`, and appends an `EOS_TOKEN` to each formatted string. This token is critical for indicating the end of a sequence in models that require a clear delimitation of the input end (such as language generation models).
2. Preparing a DPO (Direct Preference Optimization) Dataset
For a DPO dataset, we need an instruction and two possible responses to that instruction. One response is 'chosen', i.e. it is a valid and ideal response to the instruction. The other response is 'rejected', i.e. it is not an ideal response to the instruction.
The structure of the dataset is straightforward: for each row, there is one chosen (preferred) answer, and one rejected answer. The goal of RLHF is to guide the model to output the preferred answer. The model will be trained to directly optimize the preference of which sentence is the most relevant, given two sentences.
We can create DPO datasets synthetically, based on existing datasets. A common strategy is to take a dataset that already has instruction response pairs, and then generate an extra response. If you combine this strategy with another model as a judge, you can evaluate your two responses and take the best as your 'chosen' and the worst as your 'rejected'.
This strategy depends on a judge model of sufficient quality to evaluate the responses. Up until recently, the only option was GPT-4, but with the recently released Prometheus-2 model we can now use an open-source model to do the evaluation, giving us a completely open source distillation pipeline.
So to synthetically create DPO datasets for a set of prompts, you can create the answers with GPT-4-Turbo which will be your preferred answers, and with Llama-3-8B or a similar class of models, create the rejected responses.
Here is a simple util method to make your dataset ready for DPO training.

3. Dataset for ORPO (Odds Ratio Preference Optimization) training
For ORPO dataset, the trainer expects a format identical to the DPO trainer, which should include three entries. These entries should be named as follows:
- Prompt: The text that initiates the desired response from the model.
- Preferred Response: The response you want the model to generate for the prompt.
- Rejected Response: An example of an undesirable response the model should avoid generating.
About MonsterTuner - Easiest LLM Fine-tuner
MonsterTuner is a new service from MonsterAPI designed to streamline the finetuning of popular AI models on its advanced GPU computing infrastructure. With just one request, you can easily customize AI models for your business needs, making the process up to 10X more efficient and cost-effective.
Supported AI Models for Finetuning:
- LLM (Large Language Model) - 40+ different latest LLMs for use-cases like chat completion, summary generation, sentiment analysis etc.
- Whisper - For speech to text transcription improvement.
- SDXL Dreambooth - Fine-tune Stable Diffusion model for customized image generation.
MonsterAPI designed their no-code LLM fine-tuner that simplifies the process of finetuning by:
👉 Automatically configuring GPU computing environments, optimised for higher throughput (with the power of vllm in the backend).
👉 Optimizes memory usage by finding the optimal batch size.
👉 Auto configures Flash attention 2 or SDPA for faster processing with reduced memory consumption.
👉 Comes integrated with Unsloth for up to 2x faster processing on supported models..
👉 Integrates experiment tracking with WandB, and automatically pushing to Huggingface hub, and
👉 Auto configures the pipeline to complete without any errors on their cost-optimised GPU cloud
And all the above steps are without writing a single line of code.
Implementing the LLM finetuning pipeline on MonsterAPI
- Dataset validation and upload:
To fine-tune an LLM, first and foremost, we need to validate whether the dataset format is valid or not.
MonsterAPI provides support for JSON, jsonl, parquet, CSV formats for dataset uploads and also supports HuggingFace dataset paths. So you can either directly pass the HF dataset path or upload your dataset on MonsterAPI platform.
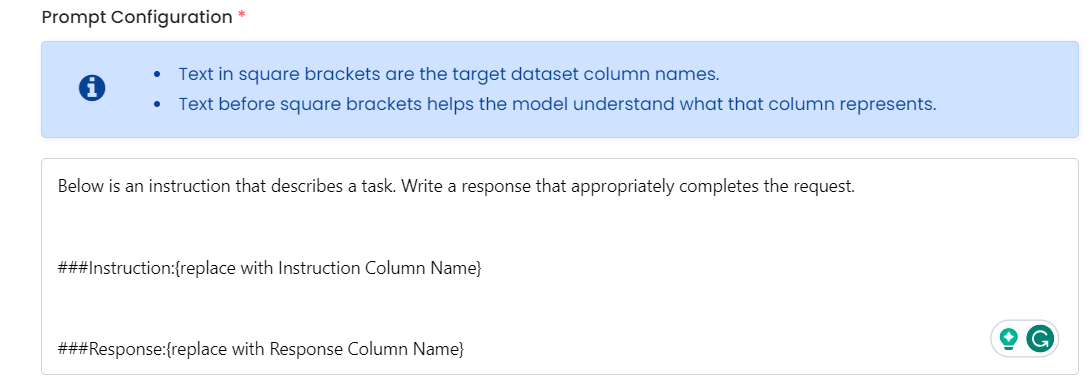
While using MonsterTuner in MonsterAPI, we provide a text-area while creating a fine-tuning job in which target columns can be specified. Depending on the type of task chosen, you may have to alter the column names. Refer to the dataset preparation doc for examples.
You may also refer to the guide on using your own custom datasets for LLM finetuning.
- Specify AI Model and Hyperparameters:

MonsterAPI supports 40+ Open source language models. So after you select a model, then specify the dataset path and hyperparameters such as LoRA R and Alpha values, number of epochs, early stopping patience etc. You may also choose to leave them as default and it would still perform very well.
Once finetuned, you’ll be able to download the finetuned LoRA adapter weights and deploy them either in your cloud or on MonsterAPI with the one-click LLM deployment engine - Monster Deploy.
That’s how easy it is to finetune LLMs using LoRA on MonsterAPI and deploy custom fine-tuned LoRA adapters as API endpoints.
You may also achieve the same result with MonsterAPI’s LLM finetuning API.
You may read in depth about our LLM finetuning API docs or directly explore our LLM finetuning solution - MonsterTuner.
MonsterAPI's technology stack incorporates several cutting-edge techniques and tools designed to optimize performance and efficiency:
📌 Flash Attention 2: This advanced attention mechanism enhances model performance by significantly reducing memory usage and computation time, allowing for faster and more efficient processing.
📌 LoRA/QLoRA: These techniques (Low-Rank Adaptation and Quantized Low-Rank Adaptation) are employed to fine-tune models with reduced resource consumption, making it easier to adapt large models to specific tasks without extensive computational overhead.
📌 Auto Batch Size: This feature automatically adjusts batch sizes to optimize memory utilization, ensuring that the available hardware resources are used efficiently and effectively during model training and inference.
📌 Low Cost GPU Cloud: MonsterAPI provides access to a cost-effective GPU cloud infrastructure, enabling users to leverage powerful computing resources without incurring prohibitive expenses, thus democratizing access to high-performance hardware.
📌 Dataset Validation API: This API ensures that datasets are correctly formatted and validated before use, reducing errors and improving the quality and reliability of the training data, which is crucial for successful model training.
📌 vLLM (with PagedAttention) for High Throughput LLM Serving: vLLM has been widely adopted across the industry, with 18K+ GitHub stars and 300+ contributors worldwide. vLLM enables high-throughput serving of large language models, facilitating quick and efficient deployment of these models for various applications.
Implementing deployment of fine-tuned models
First, the key Benefits of Monster Deploy
- Open-Source LLMs: Easily deploy open-source Large Language Models (LLMs) as REST API endpoints, broadening the range of models at your disposal.
- Finetuned LLM Deployment: Utilize LoRA adapters to deploy finetuned LLMs, ensuring increased throughput with Inception from the vLLM project, enhancing performance during requests.
- Custom Resource Allocation: Optimize resource usage by defining custom GPU and RAM configurations tailored to your specific needs, facilitating efficient model deployment.
- Multi-GPU Support: Benefit from Monster Deploy's support for resource allocation across up to 4 GPUs, effectively handling large AI models such as Mixtral 8x7B and Llama 3 70B with multi-GPU distributed computing and boosting processing capabilities.

For a comprehensive walkthrough that'll assist you with launching, tracking, and understanding the billing process, check out this guide on fine-tuning large language models (LLMs) on MonsterAPI:
https://developer.monsterapi.ai/docs/fine-tune-a-large-language-model-llm
And here is a Google colab for LLM Finetuning with MonsterTuner API:
Let's get a quick overview of the code and its workflow from the above colab example
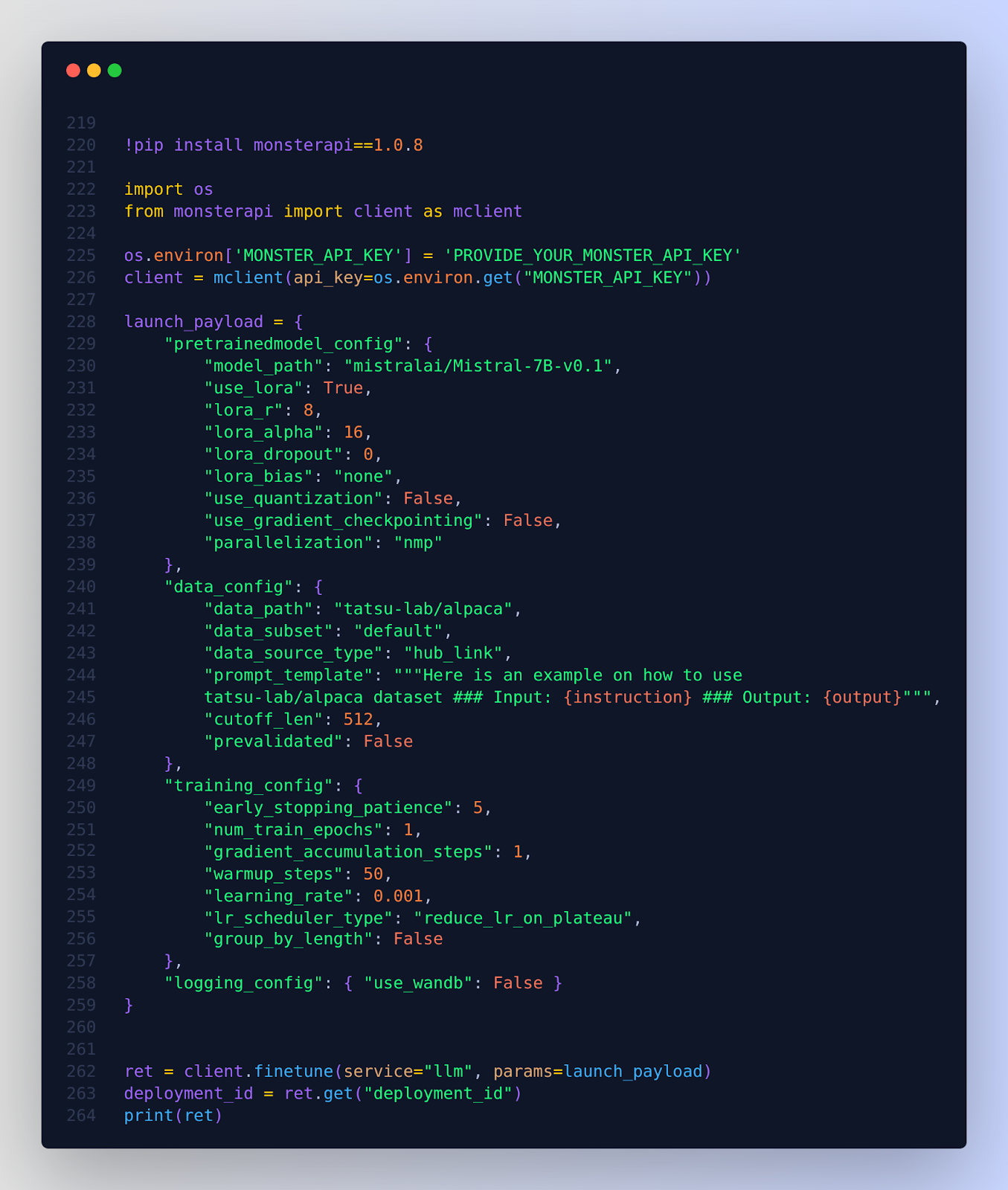
After you install the relevant libraries and Initiate Client Object, you get your code ready for a Finetuning Job
Below code block sets up a launch_payload for fine-tuning LLMs using specific configurations. The payload includes model path, LoRA parameters, data source details, and training settings such as learning rate and epochs. The model is fine-tuned using these settings
In the below example, the "use_quantization" param has been set to False. However if you want to use the benefit of quantization then set it to ‘true’.
With quantization, switched on you will be reducing the precision of the numbers used to represent model weights. For instance, instead of storing weights as 32-bit floating points, you might store them using just 4 bits. This significant reduction in data size means that the model requires less memory, and computations can be executed more quickly and with less energy.
Wait until the status is Live. It should take 5-10 minutes.
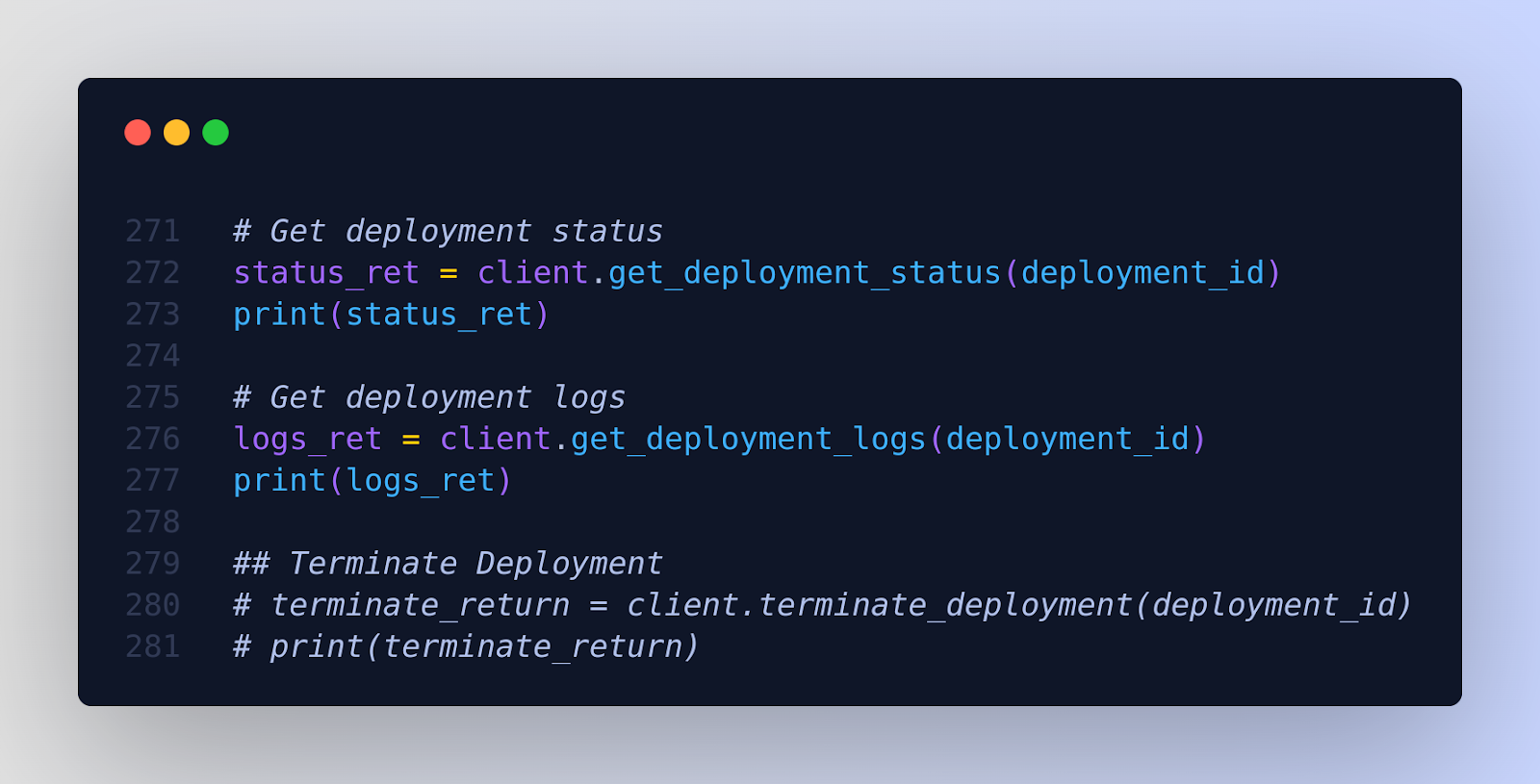
And once your fine-tuning job is launched, it's essential to monitor its progress.
A job can have four states:
Launching, In Progress, Completed, Failed.
After launching, it typically takes 4-5 minutes for the job to enter the In Progress state.
During this phase, you can view job logs by selecting View Logs from the Select an Action menu on your Job card.
If you've provided WandB credentials, you can also track the job run using the "View Metrics" option.
The most recent adapter checkpoints can be downloaded while the program is running.
Checkpoints are saved four times per epoch. If the job's duration is less than one epoch, then checkpoints are saved four times throughout the entire run.
Here's a detailed documentation for finetuning job status tracking. On this page, you'll also learn how to view job logs, monitor your job metrics using Weights & Biases (if credentials are provided), and download your fine-tuned model once the job is completed.
Deploy Your Finetuned Model
Deploying your finetuned model is a straightforward process with MonsterDeploy. Once you've completed the finetuning stage and have your model files ready, you can easily deploy your model and start using it through MonsterDeploy's service.
For more on that visit the MonsterDeploy documentation at https://developer.monsterapi.ai/docs/monster-deploy-beta
Below are all the important links.
👉 MonsterAPI Official site: https://monsterapi.ai/signup?ref=rohan
👉 MonsterGPT official guideline: https://monsterapi.ai/gpt
👉 Discord (MonsterAPIs) : https://discord.com/invite/mVXfag4kZN
👉 Checkout MonsterAPI's new NextGen LLM Inference API: - https://developer.monsterapi.ai/docs/introducing-monsterapis-new-nextgen-llm-inference-api
👉 Access all Finetuned Models by MonsterAPI here: https://huggingface.co/monsterapi