
Fine-tuning Gemma-2–2B-it for Translation
In this guide, we're showing you how to fine-tune a Gemma 2 2B model for English to Hindi translation.

Translation using large language models (LLMs) has revolutionized how we approach cross-lingual communication. LLMs leverage vast datasets and advanced architectures, such as transformers, to accurately capture the nuances of different languages.
These models can process context, idioms, and even cultural references, making translations more natural and coherent. Unlike traditional rule-based systems, LLMs rely on deep learning to understand language patterns, resulting in higher-quality translations that improve with scale and fine-tuning.
With ongoing advancements in fine-tuning techniques and multilingual training, LLMs are becoming increasingly adept at handling complex language pairs, offering both speed and precision in real-time applications.
How Models Understand Multiple Languages
Having multilingual tokens in a model’s tokenizer significantly enhances its ability to perform accurate translations. By including tokens from multiple languages, the tokenizer can better recognize and handle different scripts, vocabulary, and grammar structures.
This broad token coverage allows the model to learn shared linguistic patterns across languages, making it easier to transfer knowledge between them. For instance, commonalities like word order or syntax can be leveraged, improving the model’s ability to translate between similar or even vastly different languages.
Multilingual tokenization also reduces token fragmentation, where words are broken into suboptimal subwords, which helps maintain meaning and context during translation, leading to more fluent and coherent results.
This process is further simplified with the help of MonsterAPI’s LLM Fine-tuning engine. You can pick a model and simply perform instruction fine-tuning on the model make it better at translation. here is how you can fine-tune a model using monsterAPI for translation.
Here is an example dataset you can use to fine-tune a model for translation
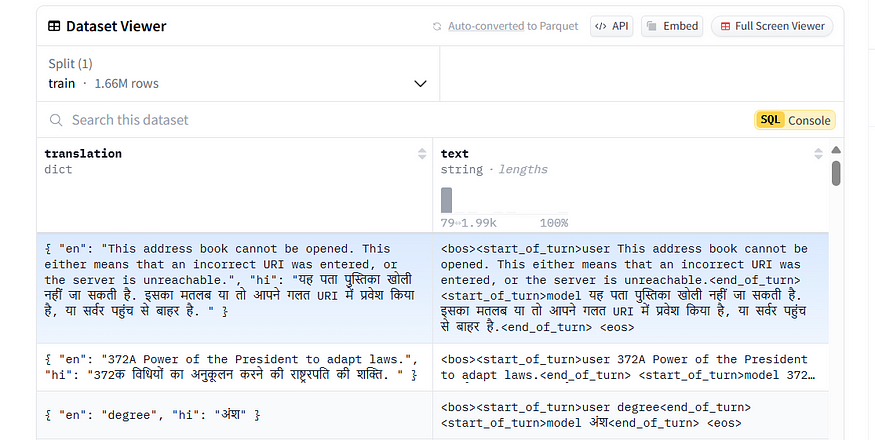
Here the text column represents the instruction to be passed to the LLM formatted using the model’s chat template. You can form this column yourself by using the following code
def format_chat_template(row):
row_json = [{"role": "user", "content": row["prompt"]},
{"role": "assistant", "content": row["response"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False) + tokenizer.eos_token # Make sure to add EOS Token
return row
dataset = dataset.map(
format_chat_template,
num_proc=4,
)Once the dataset is ready fine-tuning is pretty simple.
client = mclient(api_key=monster_api_key)
launch_payload = {
"pretrainedmodel_config": {
"model_path": "google/gemma-2-2b-it",
"use_lora": True,
"lora_r": 16,
"lora_alpha": 32,
"lora_dropout": 0,
"lora_bias": "none",
"use_quantization": False,
"use_gradient_checkpointing": False,
"parallelization": "nmp"
},
"data_config": {
"data_path": output_dataset_hf_path,
"data_subset": "default",
"data_source_type": "hub_link",
"prompt_template": "{text}",
"cutoff_len": 1024,
"prevalidated": False
},
"training_config": {
"early_stopping_patience": 5,
"num_train_epochs": 5,
"gradient_accumulation_steps": 1,
"warmup_steps": 25,
"learning_rate": 0.001,
"lr_scheduler_type": "cosine",
"group_by_length": False
},
"logging_config": {
"use_wandb": False
}
}
ret = client.finetune(service="llm", params=launch_payload)
deployment_id = ret.get("deployment_id")
print(ret)
Once Fine-tuning is done your model will be available on your huggingface page.
Try out the translation model with this easy to use Colab notebook: https://colab.research.google.com/drive/1A5Kfg5BxXg6DA9-bvgZvTTdZvicwnU_D#scrollTo=NSU0D_QA-299
Conclusion
Building your translation model is super easy when you fine-tune with MonsterAPI. Choose any model that has great multi-lingual capabilities out of the box, like the Gemma 2 models. Here’s a breakdown of how you can fine-tune large language models using MonsterAPI:
- Choose a model
MonsterAPI supports up to 60+ open source LLMs. Let’s say you want to fine-tune the latest LLaMa 3.1 model, all you have to do is choose the model from the list.
- Upload a dataset
In the next step, choose the dataset you want to use for your custom AI models. You can choose a dataset from Huggingface, or upload your custom dataset.
- Setup hyperparameters & launch job
In the next step, you’ll see a list of hyper-parameters that you can adjust to gain better control over your fine-tuning job. If you are not familiar with the parameters, you can just move to the next step of launching the job. MonsterAPI’s automated workflow will take care of the parameters for you.
Once your job is ready, you can deploy the model as an API endpoint in a single click. Ready? Build your own translation AI model with MonsterAPI.
Or, you can fine-tune Gemma 2B using this colab notebook: https://colab.research.google.com/drive/1FeFeM1viF6jNJDYgUXflRNFL0ue252zD?usp=sharing#scrollTo=uaN93Po8y675