
Everything you need to know before fine-tuning Apple’s Open ELM
In this blog post, we will explore the key features of OpenELM, its potential implications for the field of natural language processing, and how to fine-tune an open-ELM model on your data using MosterAPI.

The landscape of large language models (LLMs) is rapidly evolving, with new advancements emerging at an unprecedented pace. While these models have demonstrated remarkable capabilities, a significant challenge has been the lack of transparency surrounding their development and training processes. To address this issue, Apple recently released OpenELM - the most transparent and accessible model in recent history of open source LLMs.
OpenELM represents a significant step forward in the field by offering unprecedented transparency and accessibility. Unlike many proprietary LLMs, OpenELM provides researchers and developers with complete access to its training data, model architecture, and codebase. This level of openness fosters collaboration, accelerates research, and promotes the development of more robust and reliable language models.
In this blog post, we will explore the key features of OpenELM, its potential implications for the field of natural language processing, and how to fine-tune an open-ELM model on your data using MosterAPI.
What models should you compare open ELM with?
OpenELM falls within the category of open-source LLMs, when considering models for comparison with OpenELM, it’s crucial to focus on models that align closely with its design philosophy, scale, and openness. OpenELM exhibits demonstrably better accuracy and efficiency compared to OLMo. However, it’s crucial to recognize that OpenELM isn’t intended to go head-to-head with proprietary models like Mistral or Llama. These closed-source models typically leverage considerably larger datasets, more powerful computational resources, and potentially, architectural optimizations that remain undisclosed. Meaningful comparisons for OpenELM should involve other open-source models with similar parameter counts and an emphasis on efficiency, such as PyThia, Cerebras-GPT, or TinyLlama, which share a common goal.
OpenELM Architecture
OpenELM is built upon the foundation of a decoder-only transformer architecture, a common choice in modern large language models. However, what sets OpenELM apart is its strategic implementation of several key techniques:
- Bias Removal: The model eliminates learnable bias parameters from fully connected layers.
- Normalization: RMSNorm is used for layer normalization.
- Positional Encoding: Rotatory Positional Embedding (ROPE) is employed to incorporate positional information. ROPE provides flexibility for handling various sequence lengths and effectively captures the decaying importance of words as their distance increases, mimicking natural language patterns.
- Attention Mechanism: Grouped Query Attention (GQA) replaces the traditional multi-head attention (MHA). GQA divides query heads into groups, with each group sharing a single key-value pair. This reduces computational cost compared to MHA while allowing for more complex attention patterns than MQA.
- Feed-Forward Network (FFN): SwiGLU FFN is used instead of the standard FFN.
- Attention Computation: Flash attention is utilized for efficient attention calculation.
- Tokenization: The same tokenizer as LLama is adopted.
Apart form the above changes OpenELM introduces a novel technique called layer-wise scaling to optimize parameter allocation within the transformer architecture. Unlike traditional models that use identical configurations for all layers, OpenELM strategically varies the number of attention heads and feed-forward network (FFN) dimensions across different layers. The goal is to allocate more parameters to layers that are deemed more critical for model performance, while reducing parameters in less influential layers. This efficient distribution of parameters can lead to improved accuracy and computational efficiency.
Standard Transformer Layer
In a standard transformer layer, the key parameters are as follows:

- Number of layers: N
- Dimensionality of input to each layer: dₘ
- Number of attention heads: nₕ
- m FFN multiplier
Layer-wise Scaling
The layer-wise scaling mechanism modifies these parameters for each layer using scaling factors α and β. These parameters are defined for each layer i as follows:

The hyperparameters α_min, α_max, β_min, and β_max control the minimum and maximum scaling of the attention heads and FFN multipliers:
- α_min and α_max: These define the range within which the number of attention heads scales from the first to the last layer.
- β_min and β_max: These define the range within which the FFN multiplier scales across the layers.

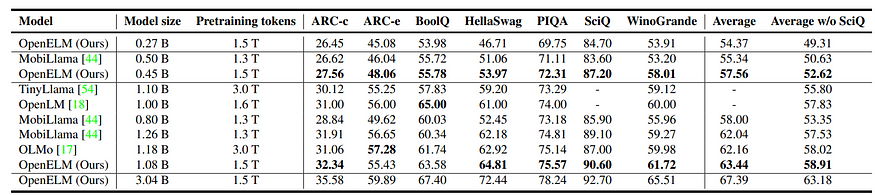
OpenELM demonstrates impressive performance across a range of benchmarks, outshining many of its open-source counterparts. When compared to models like OLMo, OpenELM achieves significantly higher accuracy while requiring significantly less training data. For instance, an OpenELM model with 1.1 billion parameters surpasses OLMo’s 1.2 billion parameter model by a margin of 1.28% to 2.36% across various benchmarks, all while using half the training data.
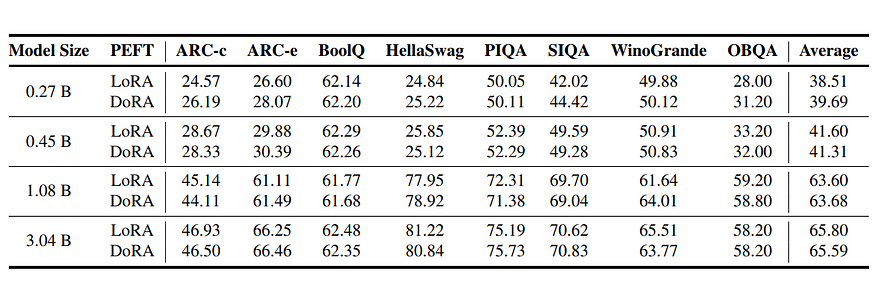
Beyond its strong zero-shot performance, OpenELM also benefits significantly from instruction tuning. The model experiences consistent accuracy improvements across different evaluation frameworks after undergoing this process. Additionally, parameter-efficient fine-tuning techniques like LoRA and DoRA can be effectively applied to OpenELM, further enhancing its capabilities without requiring extensive retraining.
Fine-Tuning OpenELM using MonsterAPI
You can now fine-tune Open-ELM using MonsterAPI on your own datasets below is an example of how to do so.
import requests
url = "https://api.monsterapi.ai/v1/finetune/llm"You can now simply configure your payload to post a request to the API as follows
payload = {
"deployment_name": "OpenELM_fine_tuning",
"pretrainedmodel_config": {
"model_path": "apple/OpenELM-450M",
"use_lora": True,
"lora_r": 8,
"lora_alpha": 16,
"lora_dropout": 0,
"lora_bias": "none",
"use_quantization": False,
"use_unsloth": False,
"use_gradient_checkpointing": False,
"parallelization": "nmp"
},
"data_config": {
"data_path": "tatsu-lab/alpaca",
"data_subset": "default",
"data_source_type": "hub_link",
"prompt_template": "Here is an example on how to use tatsu-lab/alpaca dataset ### Input: {instruction} ### Output: {output}",
"cutoff_len": 512,
"prevalidated": False
},
"training_config": {
"early_stopping_patience": 5,
"num_train_epochs": 1,
"gradient_accumulation_steps": 1,
"warmup_steps": 50,
"learning_rate": 0.001,
"lr_scheduler_type": "reduce_lr_on_plateau",
"group_by_length": False
},
"logging_config": { "use_wandb": False },
"hf_config": { "hf_token": "<HF TOKEN>" },
"accessorytasks_config": {
"run_eval_report": False,
"run_quantize_merge": False
}
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer <"MONSTER API TOKEN">
}To train on datasets of your choice just change the data_config on the payload as desired. Once you payload is configured fine-tuning can be started as follows:
response = requests.post(url, json=payload, headers=headers)print(response.text)
If everything is successful you will se a message like the following:
{"message":"Deployment Launched",
"servingParams":{
"config_url":"s3://finetuning-service/job_configs/03c9e3d9-1810-4834-a258-5118fa9e570a.json",
"deployment_id":"03c9e3d9-1810-4834-a258-5118fa9e570a",
"deployment_name":"\"OpenELM_fine_tuning\"",
"hostname":"inventive_sagan_715b4d7a-f"},
"deployment_id":"03c9e3d9-1810-4834-a258-5118fa9e570a"}
Once the fine-tuning is over you can view your results on your dashboard and your fine-runed model will be uploaded to your hugging-face hub directly.
Here are a few interesting observations we have got from fin-tuning Open-ELM to generate code on coding instructions 27-K:
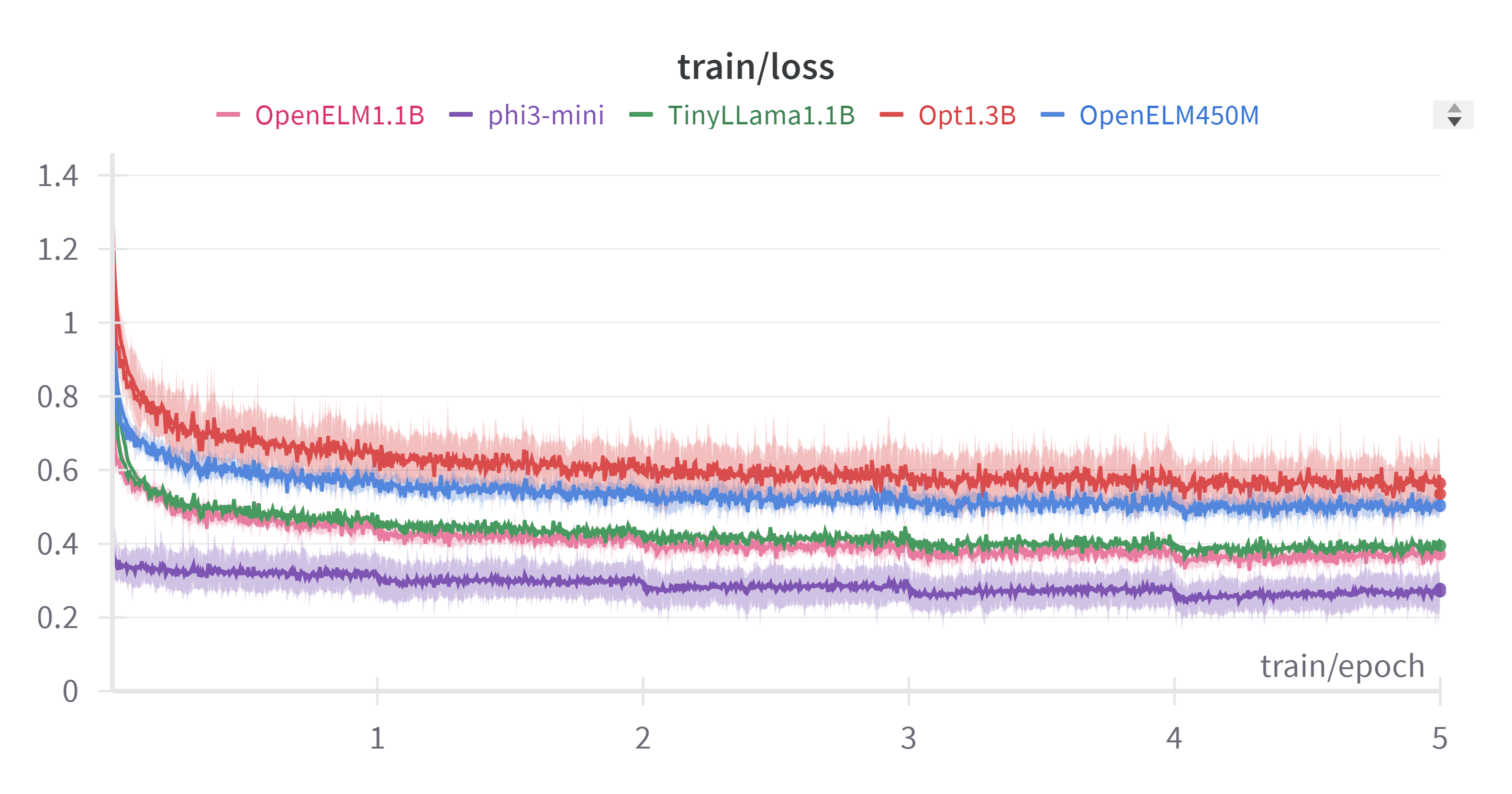
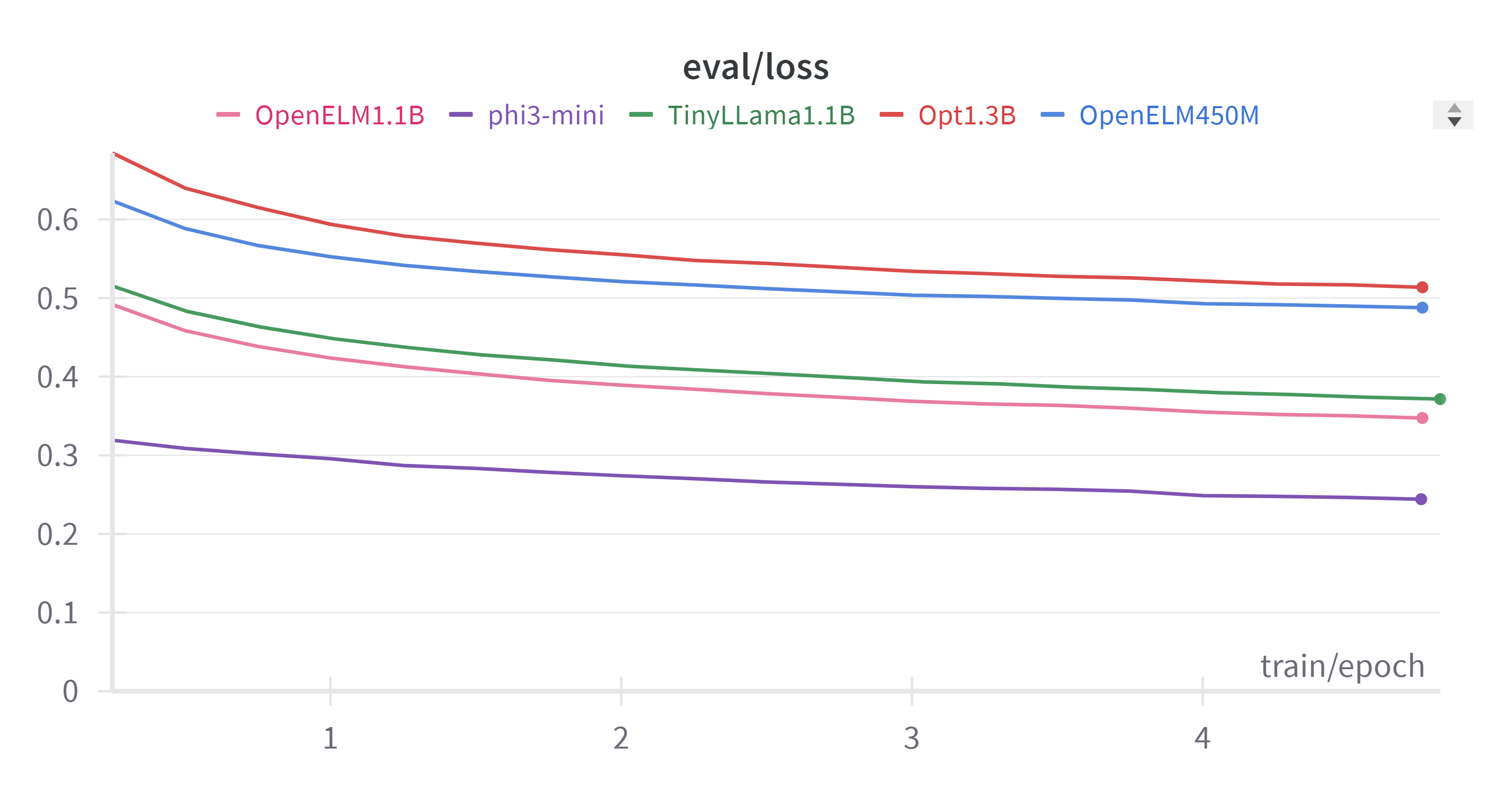
We can see that Open ELM was able to consistently outperform similar sized models and was able to perform almost similar or close to Phi-3 which is a trained on proprietary data. one more intresting plot to look at is the inference speed of these models:
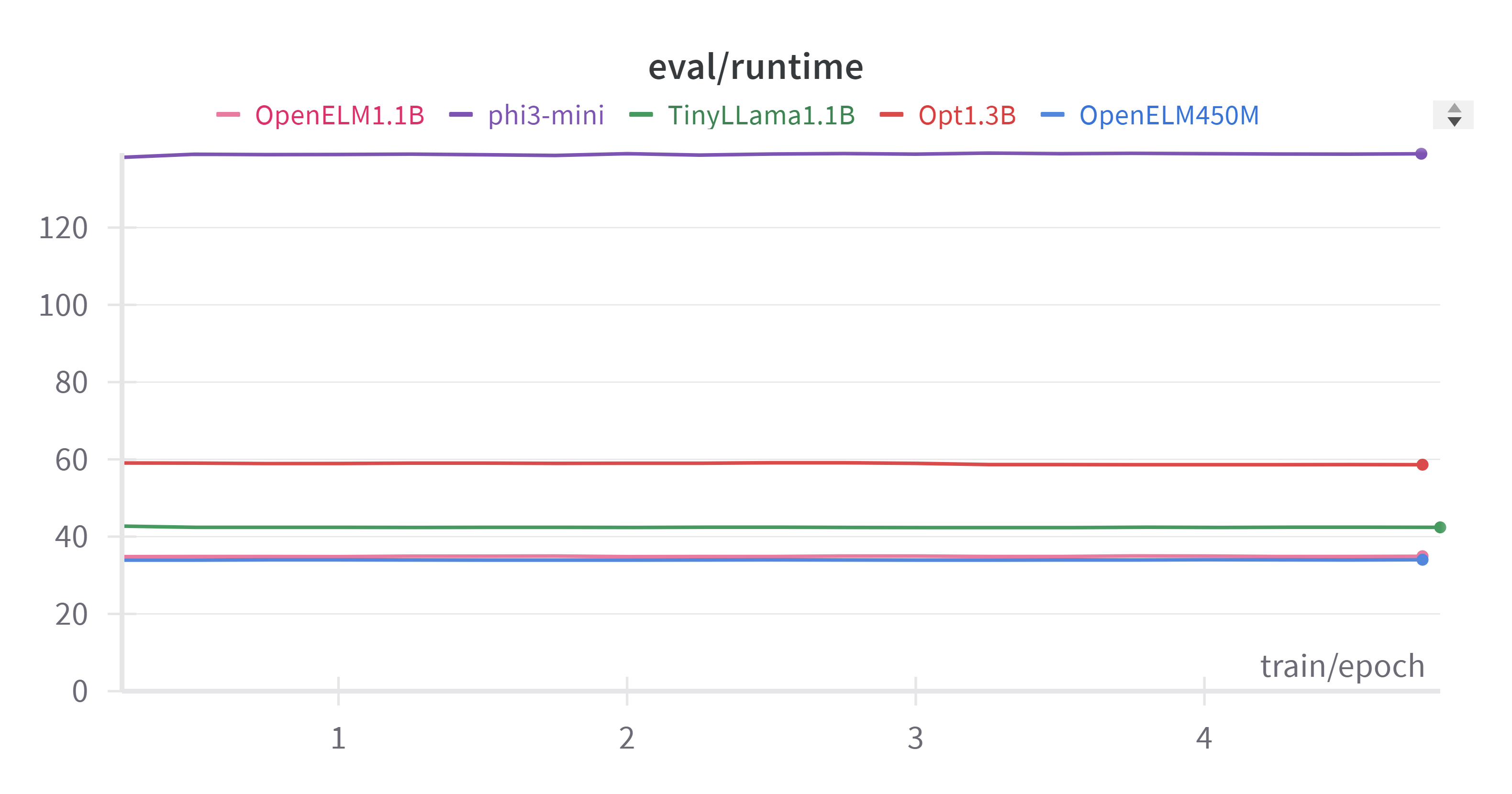

We can see that OpenELM outperformed all other models in-terms of inference speed. Essentially by fine-tuning OpenELM you are getting a faster model that can perform similar to commercial LLMs at a much lower inference cost.
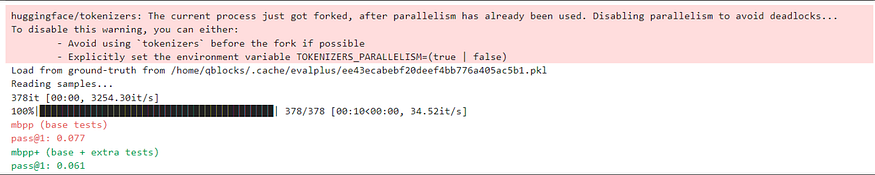
To further support our claims we have benchmarked it on MBPP+ benchmark dataset and ere are the results: OpenELM 1.1B finetuned on coding exercise 27K achieved 7.7% on base tests and 6.1% on base+extra tests.

OpemELM almost performed as good a Zyte-1B and could even beat un-finetuned Zyte-1B which is a commercial LLM.