
A guide on how to Finetune Large Language Models (LLMs) in 2024

Large Language Models (LLMs) have quickly become a sensation in the field of Natural Language Processing (NLP). The emergence of ChatGPT has further amplified the interest in LLMs as they possess the remarkable ability to generate text that closely resembles human language, offer prompt answers to queries, and actively engage in conversations.
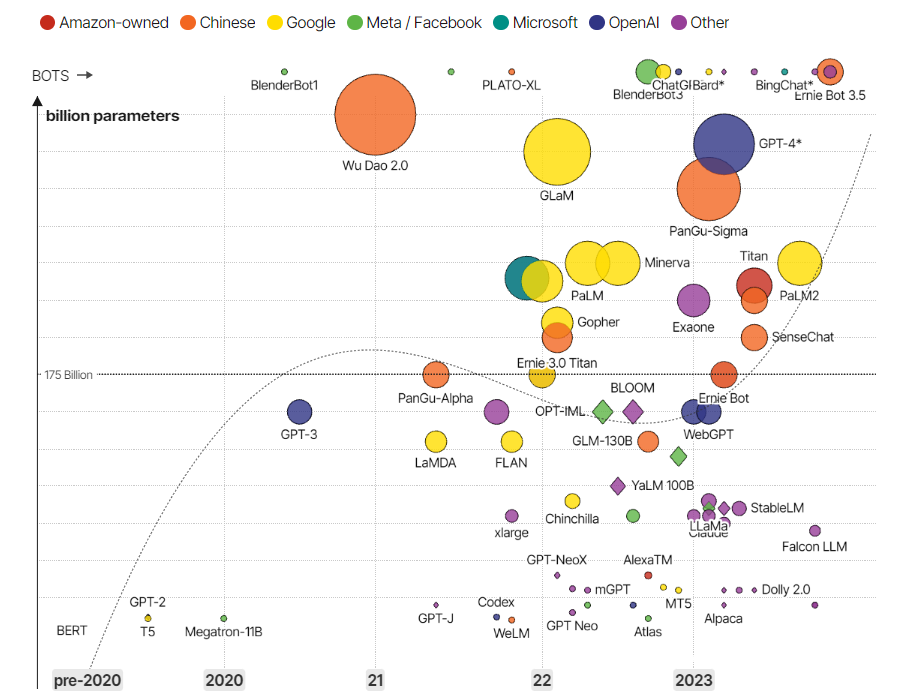
The following figure aptly shows the rise in the development of LLMs since the launch of ChatGPT back in November 2022
But what exactly is an LLM?
In simple terms, an LLM is a type of AI model that uses deep learning techniques and vast amounts of data to understand, summarize, generate, and predict new content. Think of it as a "next-word prediction engine" for natural language. When given a piece of text, it predicts the most likely next word based on what it has learned from extensive datasets.
The key to the power of LLMs lies in their large size and the transformer-based attention mechanism. They consist of multiple layers of interconnected nodes that learn from massive amounts of text data, like books, articles, or websites. This extensive training enables the model to generate responses that make sense in context and appear coherent.
What is LLM Finetuning?
While LLMs are indeed powerful and capable of remarkable feats, they often require a process called "fine-tuning" to reach their full potential.
When an LLM is initially created, it undergoes pre-training, where it learns from vast and diverse datasets to grasp the nuances of language and build a strong foundation for general understanding. However, this pre-training phase doesn't make the model an expert in any specific task; it merely equips it with a broad understanding of language patterns.
The need for fine-tuning arises because every application or task has its unique characteristics and requirements. The broad knowledge acquired during pre-training may not be sufficient to handle the intricacies and nuances of specific tasks.
Here's an example - Consider the use of a medical chatbot designed to assist healthcare professionals in diagnosing rare diseases.

The goal of this chatbot is to analyze symptoms described by doctors and provide potential diagnoses or recommendations for further tests or specialist consultations.
However, for building an effective medical chatbot, an LLM requires fine-tuning to ensure its accuracy and safety in a highly critical domain like healthcare.
Here's why fine-tuning is necessary is so important:
- Domain-specific Knowledge: The medical field has its own unique terminology and language conventions. To fully grasp the intricate medical jargon required for precise diagnosis, fine-tuning is a must.
- Contextual understanding: Fine-tuning the LLM with patient records and relevant medical literature helps it contextualize the symptoms and make more informed predictions.
- Safety and ethics: Fine-tuning enables the chatbot to be more cautious about providing diagnoses and recommendations
- Bias reduction: Fine-tuning the LLM on a diverse and representative medical dataset helps mitigate biases and promotes fair and equitable healthcare recommendations.
Fine-tuning involves taking the pre-trained LLM and training it further on a smaller, task-specific dataset. This process helps the model adapt its knowledge to the particular context of the task, refining its predictions and making it more specialized in delivering accurate results for those specific use cases, like healthcare.
Challenges associated with fine-tuning LLMs -
Developers may face numerous obstacles when it comes to fine-tuning foundational models such as GPT-J or LLaMA. These challenges may include intricate configurations, considerable memory demands, costly GPU expenses, and the lack of standardized methodologies. As a result, it can be challenging for developers to tailor a model to meet their specific needs.
- Complex Setups: Configuring GPUs and software dependencies for Fine-tuning foundational models can be intricate and time-consuming, requiring manual management and setup.
- Memory Constraints: Fine-tuning large language models demands significant GPU memory, which can be a limitation for developers with resource constraints.
- GPU Costs: GPU expenses for Fine-tuning can be costly, making it a luxury not all developers can afford.
- Lack of Standardized Methodologies: The absence of standardized practices can make the Fine-tuning process frustrating and time-consuming, requiring developers to navigate through various documentation and forums.
MonsterAPI's LLM FineTuner addresses these challenges effectively:
- Simplified Setups: Monster API provides a user-friendly, intuitive interface that simplifies the process of setting up a GPU environment for Fine-tuning, eliminating the need for manual hardware specifications and low-level configurations.
- Optimized Memory Utilization: The FineTuner optimizes memory usage during the process, making large language model Fine-tuning manageable even with limited GPU memory.
- Low-cost GPU Access: Monster API offers access to its decentralized GPU network, providing on-demand access to affordable GPU instances, reducing the overall cost and complexity associated with Fine-tuning LLMs.
- Standardized Practices: The platform provides predefined tasks and best practices, guiding developers through the Fine-tuning process without the need to search through extensive documentation and forums. It also allows for flexibility to create custom tasks.
You can rely on MonsterAPI LLM finetuner to simplify and streamline the intricate fine-tuning process, making it easy, scalable and cost effective for you to tackle.
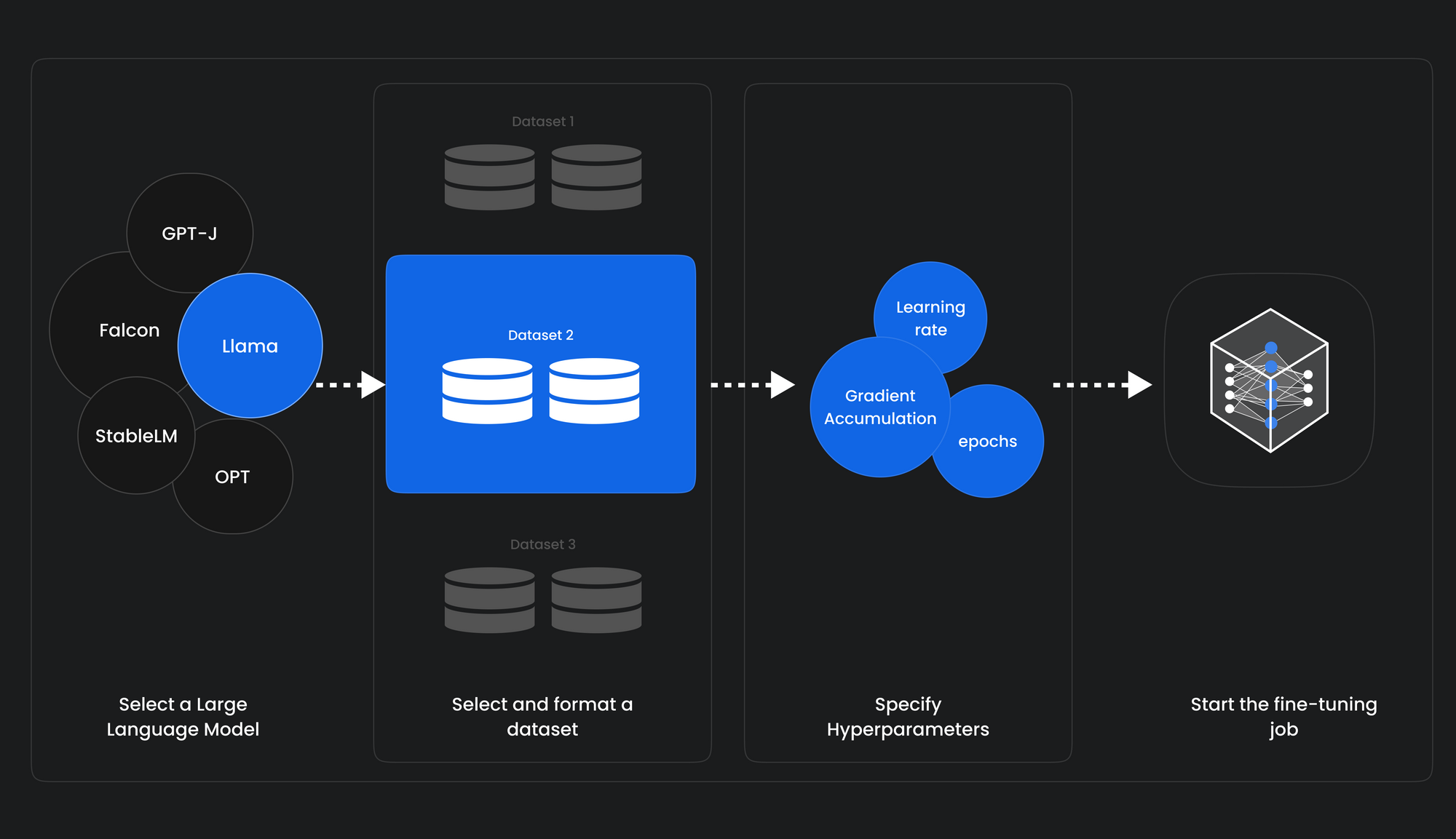
With our no-code LLM finetuner, you can effortlessly fine-tune a large language model like LLaMA 7B with DataBricks Dolly 15k for 3 epochs using LoRA.
And guess what? It won't break your bank, costing you less than $20.
For context about the LLM and Dataset used for this blog:
LLaMA (Large Language Model Meta AI) is an impressive language model developed by Facebook AI Research (FAIR) for machine translation tasks. Based on the Transformer architecture, LLaMA is trained on a vast corpus of multilingual data, enabling it to translate between many language pairs. LLaMA 7B, with 7 billion parameters, is the smallest variant of this model.
To demonstrate interactive and engaging conversational abilities like ChatGPT, we utilized the Databricks Dolly V2 dataset. This dataset, specifically the "data bricks-dolly-15k" corpus, consists of over 15,000 records created by Databricks employees, providing a diverse and rich source of conversational data.
In just five simple steps, you can set up your fine-tuning task and experience remarkable results.
So, let's get started and explore the process together!
1. Select a Language Model for Finetuning: Choose from popular open-source models like Llama 7B, GPT-J 6B, or StableLM 7B.

2. Select or Create a Task: Next, choose from pre-defined tasks or create a custom one to suit your needs. If your task is unique, you can even choose the "Other" option to create a custom task.

3. Select a HuggingFace Dataset: Monster API seamlessly integrates with HuggingFace datasets, offering a wide selection. With just a few clicks, your selected dataset is automatically formatted and ready for use.
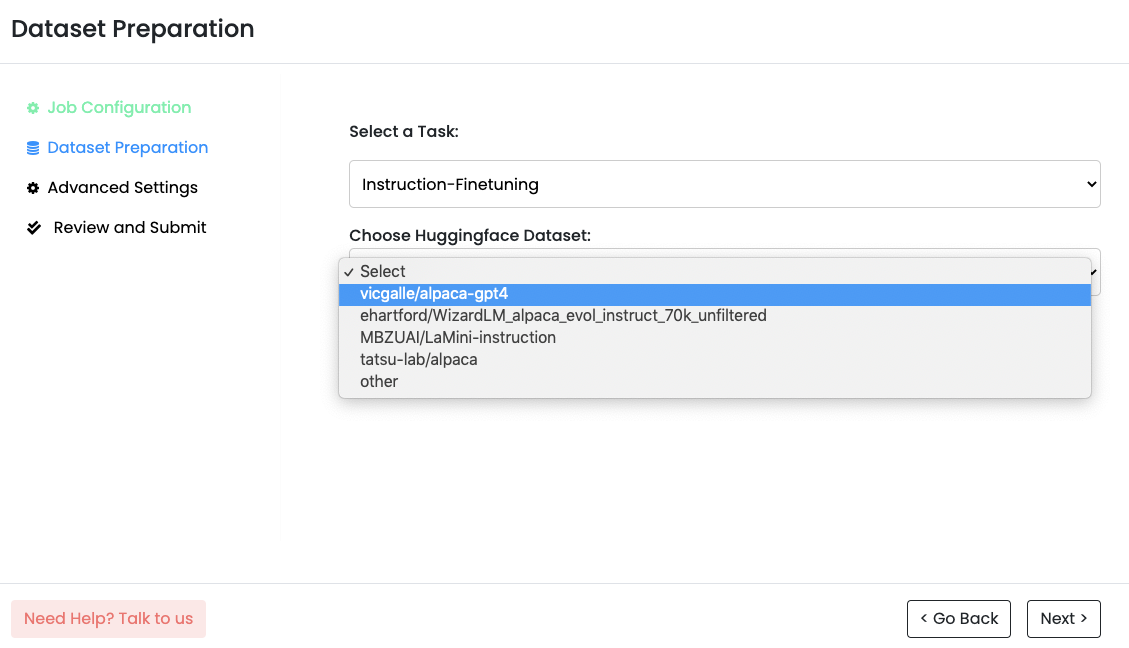
4. Specify Hyper-parameters: Monster API simplifies the process by pre-filling most of the hyper-parameters based on your selected LLM. You have the freedom to customize parameters such as epochs, learning rate, cutoff length, warmup steps, and more.
5. Review and Submit Finetuning Job: After setting up all the parameters, you can review everything on the summary page. We know the importance of accuracy, so we provide this step to ensure you have full control. Once you're confident with the details, simply submit the job. From there, we take care of the rest.
That’s it! In just five easy steps, your job is submitted for FineTuning an LLM of your choice. We're committed to simplifying the process so you can focus on your task without being overwhelmed by complex configurations.
After successfully setting up your fine-tuning job using Monster API, you can monitor the performance through detailed logs on WandB. We believe in providing you with the insights you need to make informed decisions and achieve the best results.
The Benefits of Monster API
The value of Monster API's FineTuning LLM product lies in its ability to simplify and democratize the use of large language models (LLMs). By eliminating common barriers such as technical complexity, memory constraints, high GPU costs, and lack of uniform practices, the platform makes AI model fine-tuning accessible and efficient. In doing so, it empowers developers to fully leverage LLMs, fostering the development of more sophisticated AI applications.
Ready to finetune an LLM for your business needs?
Sign up on MonsterAPI to get free credits and try out our no-code LLM Finetuning solution today!
Check out our documentation on Finetuning an LLM.