
Fine-tuning LLama 3.1 8B and Outperforming the Competition
Using MonsterAPI's no-code LLM fine-tuner, MonsterTuner, we fine-tuned the Llama 3.1 base model and outperformed larger models.

In this case study, we explore how we took the Llama base model and fine-tuned it using advanced techniques, leading to exceptional performance in the MuSR (Multistep Soft Reasoning) and GPQA (General Problem-solving and Question Answering) benchmarks.
The result? Our fine-tuned model, which outpaces many larger models while being efficient and cost-effective.
📙 Check out the fine-tuned model on HuggingFace now.
A Case Study on Multi-step Reasoning and Problem-Solving for LLMs.
We started with Meta's Llama 3.1, a powerful multilingual large language model (LLM) optimized for dialogue and multilingual use cases. This base model, part of the Meta Llama 3.1 series, includes variants with 8B, 70B, and 405B parameters, and is known for outperforming many open-source and proprietary models on key industry benchmarks.
The Dataset: Intel/orca_dpo_pairs
To fine-tune our model, we utilized the Intel/orca_dpo_pairs dataset, a filtered version of the OpenOrca dataset organized to align with the ORCA paper's distributions, t.
This dataset includes approximately 16000 rows. it serves as a robust resource for training and evaluation in natural language processing. A key feature of the Intel Orca dataset is its incorporation of preference optimization, which indicates which answers are good and which are bad—crucial for improving model guidance during generation.
Understanding ORPO
The fine-tuning of our model was significantly enhanced by the use of Odds Ratio Preference Optimization (ORPO), a novel preference alignment algorithm.
ORPO differs from traditional methods by eliminating the need for a reference model and instead using an odds ratio-based penalty in the fine-tuning process. This approach allows the model to efficiently differentiate between favored and disfavored responses, optimizing its performance without the requirement of additional reference models.
The effectiveness of ORPO has been demonstrated across various model sizes, and in our case, it played an important role in achieving impressive scores in MUSR and GPQA.
Fine-Tuning Process
Using MonsterAPI's no-code LLM fine-tuner, MonsterTuner, we fine-tuned the Llama 3.1 base model. This process, which involved just one epoch of training, was enhanced by ORPO, resulting in the impressive performance of our fine-tuned model.
- Epochs: 1
- Finetuning Cost: $2.69
- Time Taken: 1 hour 39 minutes
Benchmarking Success in MuSR and GPQA
Our fine-tuned model demonstrated outstanding results in the MuSR and GPQA benchmarks:
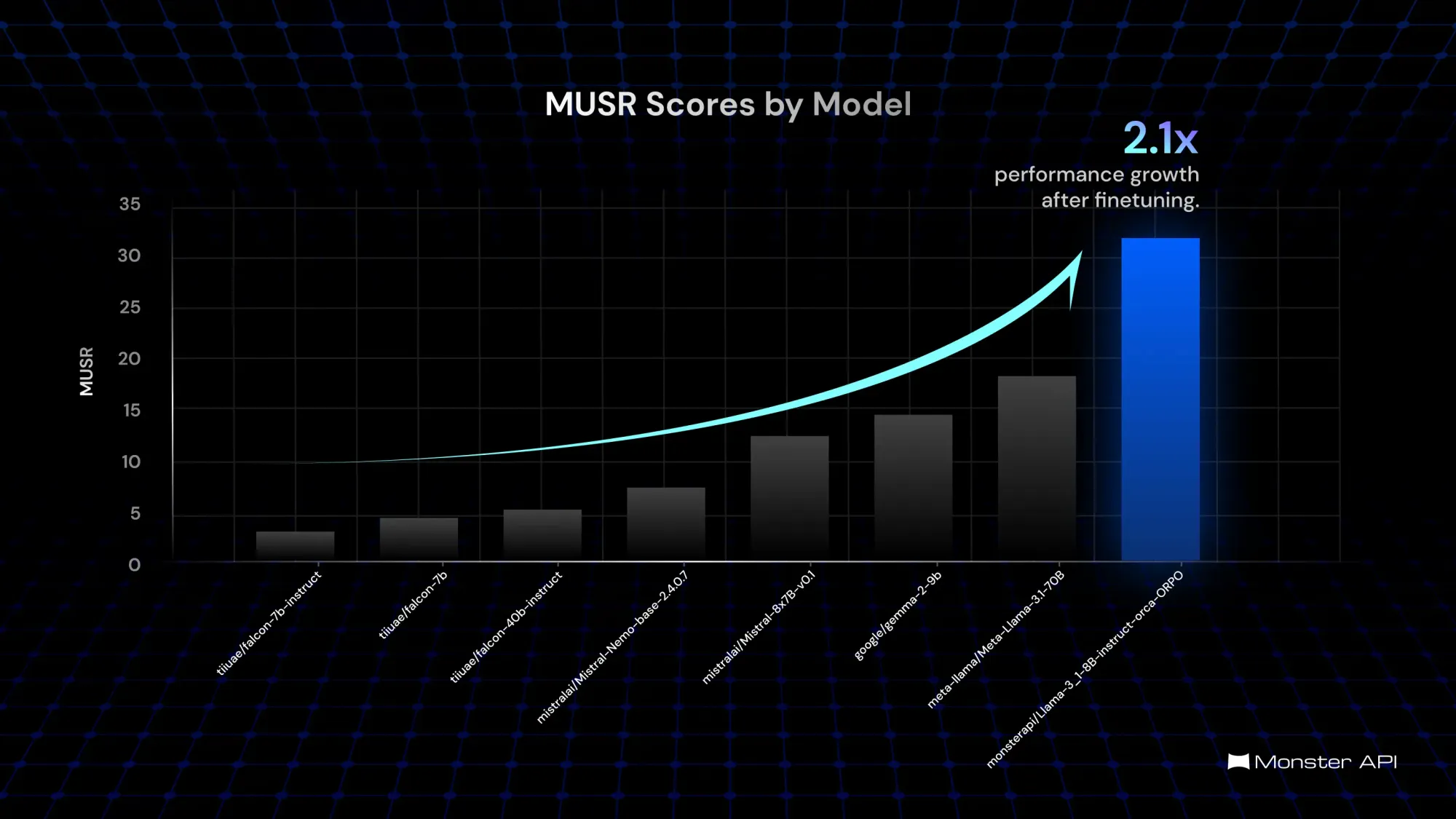
- MuSR Score: The model achieved a remarkable score, highlighting its capability to handle multistep reasoning and complex narrative-based tasks effectively.
- GPQA Score: The model also excelled in general problem-solving and question-answering ability, surpassing many larger models in this area.
These results are particularly noteworthy because they suggest that with targeted fine-tuning, even smaller models can achieve, and sometimes exceed, the performance of much larger models.
Additionally, our fine-tuned model performed well across other benchmarks, demonstrating its versatility and robustness.
The model delivered solid results in IFEval, BBH, and MMLU-PRO, confirming its ability to handle a wide range of tasks beyond its key strengths in MuSR and GPQA.
Visualizing the Results
Below are the charts that illustrate our model's performance across various benchmarks. The charts highlight the impressive scores in MuSR and GPQA, with the model's name updated for consistency.
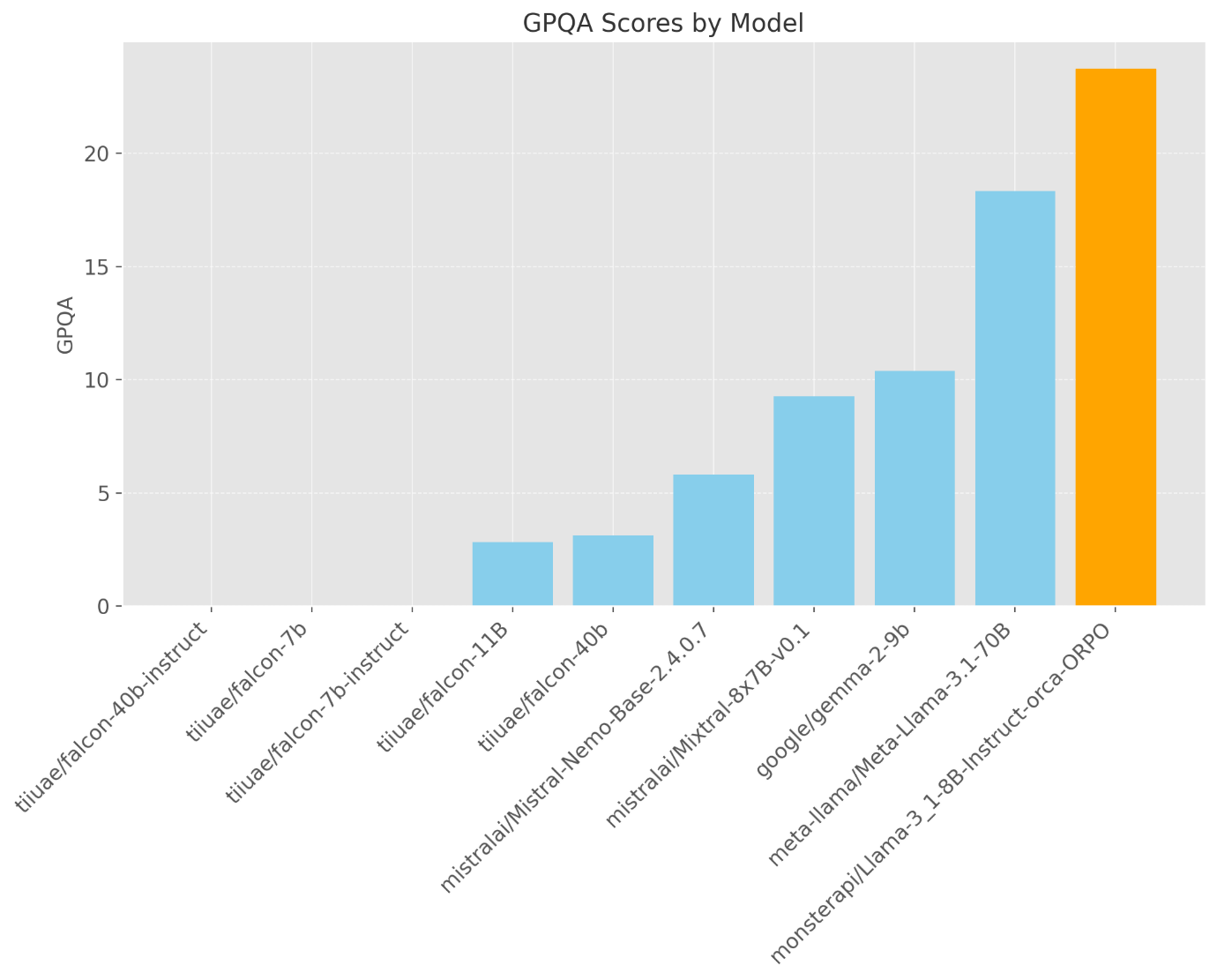
Note: The model named monsterapi/Llama-3_1-8B-Instruct-orca-ORPO in these charts is our fine-tuned model.
Why These Benchmarks Matter
MuSR Benchmark evaluates a model's ability to comprehend and reason across multiple languages and structured datasets. This benchmark is essential for applications in global markets where multilingual capabilities are critical.
GPQA Benchmark assesses general problem-solving and question-answering abilities, a key metric for evaluating a model's versatility and adaptability across various tasks.
Key Takeaways
- Cost-Efficient Fine-Tuning: The fine-tuning process was both time-efficient and cost-effective, making it an attractive option for teams with limited resources.
- Targeted Optimization Leads to Success: The impressive scores in MUSR and GPQA underscore the importance of targeted optimization in model fine-tuning. By focusing on specific tasks, even smaller models can outperform larger ones.
- Applications in Real-Time Scenarios: Our fine-tuned model's efficiency and high performance make it ideal for real-time applications, especially in multilingual environments.
Conclusion
The success of our fine-tuned model demonstrates the potential of smaller models when fine-tuned effectively. This case study highlights how, with the right dataset and optimization strategy, a smaller model can achieve results that rival or even surpass those of larger, more resource-intensive models. This is a testament to the power of focused fine-tuning in enhancing the performance and applicability of language models.
Launch your first LLM fine-tuning job using MonsterTuner. Sign up for a new account and get free 2,500 credits to fine-tune, deploy, models & play around in our playground.