
Deploying Llama 3 with MonsterGPT


Llama-3 currently holds the top position among open-source large language models (LLMs). On the Chatbot Arena Leaderboard, it leads the open-source category by a significant margin, with no comparable rivals. The performance gap between Llama-3 and GPT-4 is surprisingly narrow, and with its next release, Llama-3 400B it is expected to equal GPT-4 .
Many companies are now opting out of using proprietary models like ChatGPT due to privacy concerns and the inability to share sensitive data. Instead, they are building fine-tuned versions of Llama 3 for their business-specific tasks and are deploying these finetuned models directly.
But there’s a common challenge faced when deploying large language models (LLMs): deploying high-throughput LLMs is complex and costly. Configuring the right VM instances with suitable CPUs, GPUs, and RAM, as well as setting up the entire pipeline with auto scaling and authentication involves significant MLOps effort.
Say goodbye to the complexities of finetuning large language models and deploying them for your business needs. The new era brings effortless, fast, and cost-effective solutions, all managed by simple dialogue, right from within ChatGPT.
Thanks to MonsterGPT, a novel way to fine-tune and deploy LLMs that I found incredibly helpful in reducing my effort.
What is MonsterGPT?
MonsterGPT is the "world's first finetuning and deployment agent". It enables developers to finetune and deploy LLMs by simply asking in natural language! No coding, No infra setup needed. The assistant handles it all for you!
With MonsterGPT, you can ask the agent to do the following for you:
- Finetune an LLM on your dataset
- Deploy an open source LLM as an API endpoint
- Deploy your fine-tuned LLMs as an API endpoint
This is the moment of chat-powered LLMops ✨

How to deploy LLMs using MonsterGPT
To Deploy LLMs, all you have to do is ask! In the familiar Chat UI, just ask MonsterGPT to deploy a specific Llama-3 model and it will do it. The system automatically recommends a GPU with suitable VRAM for the size of your selected model.
To get started, Sign up on MonsterAPI and load MonsterGPT using the following link: https://chat.openai.com/g/g-yWHAqw26c-monstergpt.
Once you are inside this custom GPT, just prompt for which model you want to deploy.
So My Prompt in this case is:
"I want to deploy monsterapi/llama3_8B_norobots"

And MonsterGPT gave a recommendation for GPU configuration that would work best for my requirement and asked me to confirm.
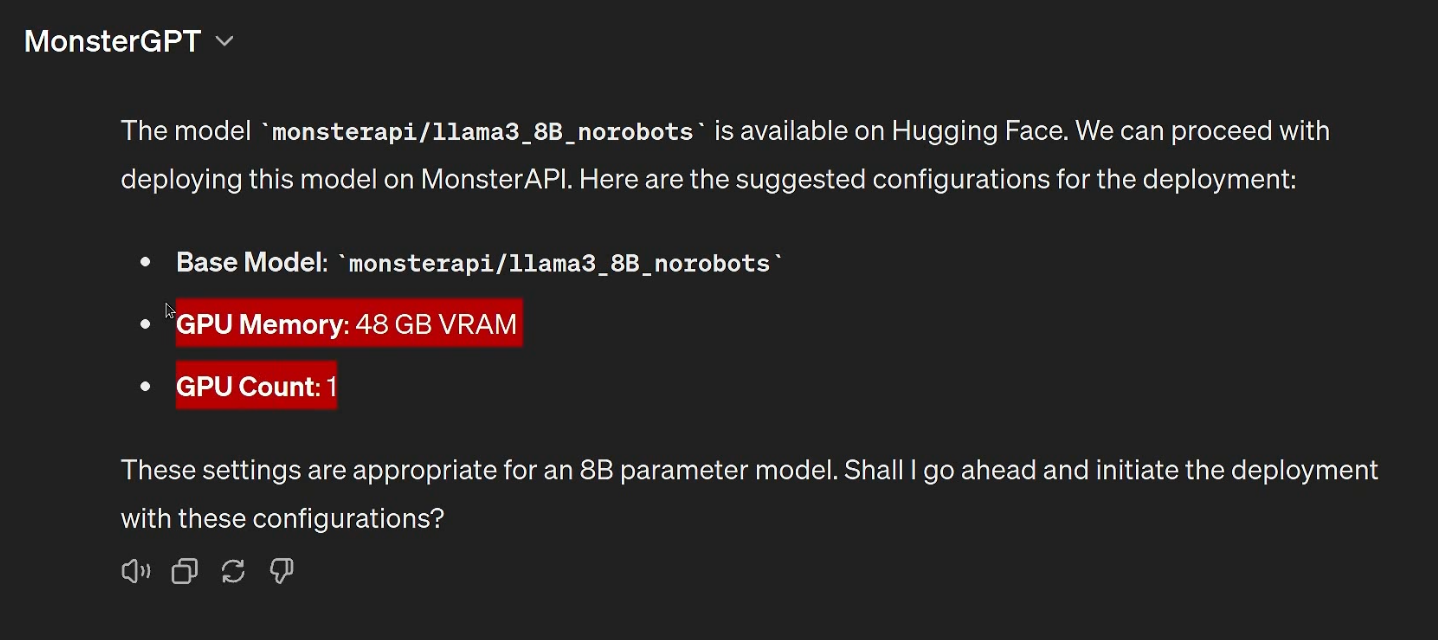
After you confirm the above recommendation, MonsterGPT will launch the deployment, and start provisioning the machines. It will take a few minutes to go from "Pending" to "Live". And any changes in the status of your deployment (e.g. 'pending', 'building' etc ) will be immediately notified to you by e-mail as well.

And you can definitely check in your MonsterAPI Dashboard for the status of the deployment.

And you can also ask MonsterGPT about the status details, and if the deployment is already live, you will get the Deployment URL as well.
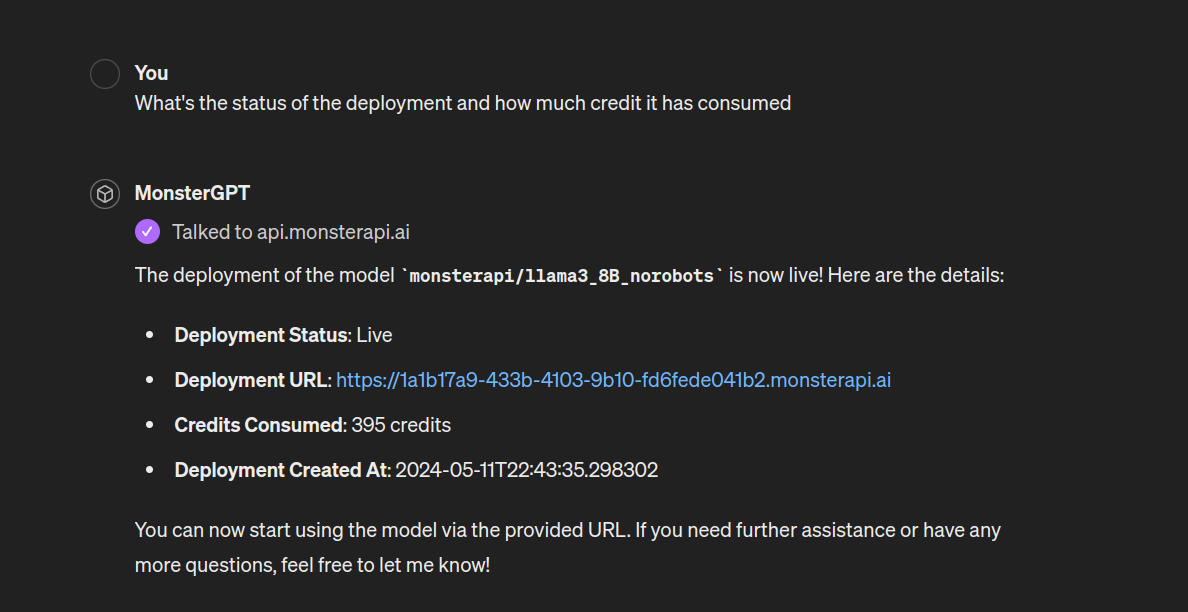
Accessing your deployed LLM API endpoint:
Once your deployment is "live", you can access your Deployment URL (LLM API endpoint) by either asking MonsterGPT directly or from your MonsterAPI Dashboard.
Additionally, these LLM deployments on MonsterAPI are automatically configured with vLLM engine for enabling higher throughput and reduced cost of serving. Thus, drastically reducing the effort of building a production ready LLM serving pipeline!
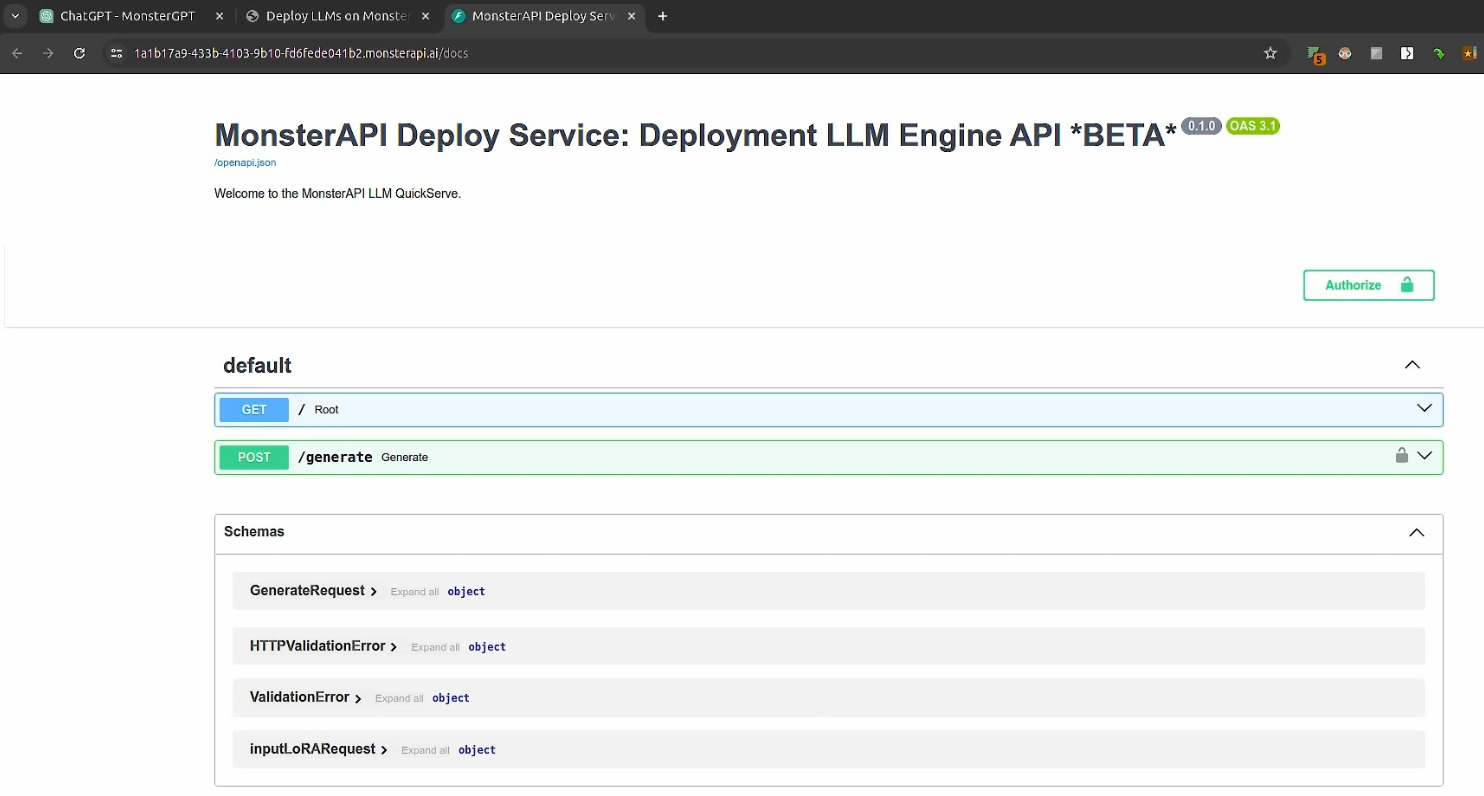
In this Deployment URL, you can query the LLM with your text generation prompts after authorizing with your Bearer Auth Token (which you will get from MonsterAPI Dashboard or by asking MonsterGPT).
The deployed LLM endpoint provides you complete granular control with parameters such as max tokens, streaming, top_p and top_k, that will help you control the quality of your model’s generated output.
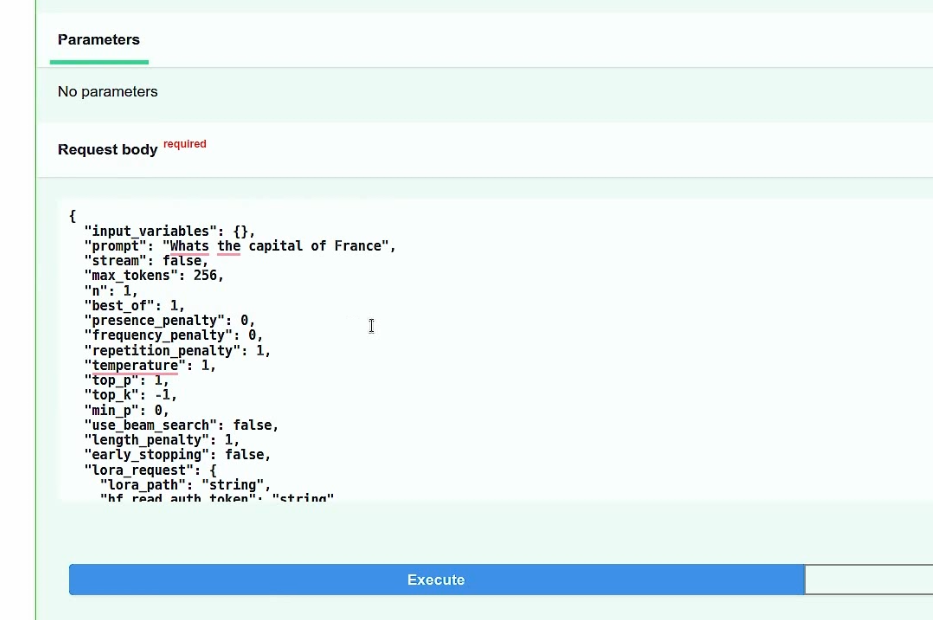
Do note, this API endpoint is a complete public REST API endpoint ready to serve millions of token generation requests, which means you can directly integrate it into your Web or Mobile apps.
Conclusion:
I think MonsterGPT is a very novel and innovative approach and indeed a true powerhouse capable of launching and managing full deployments of the latest AI models within minutes right from within the ChatGPT interface, by just regular chatting.
And currently I think Deployment of AI models with MonsterGPT is the easiest, fastest and most affordable among all the options that I've explored so far.
To get started, register at MonsterAPI and you will get 2500 Free credit which is enough for all your experiments.
That's a wrap and here are all the important links.
👉 Website: http://monsterapi.ai
👉 MonsterGPT official guideline: https://monsterapi.ai/gpt
👉 Try MonsterGPT: https://chat.openai.com/g/g-yWHAqw26c-monstergpt
👉 Discord (Monsterapis) : https://discord.com/invite/mVXfag4kZN
👉 Checkout MonsterAPI's new NextGen LLM Inference API: - https://developer.monsterapi.ai/docs/introducing-monsterapis-new-nextgen-llm-inference-api
👉 Access all Finetuned Models by Monster here: https://huggingface.co/monsterapi