
Choosing the Right LLMs & Fine-Tuning for Text Summarization & Code Generation?
In this blog, we’ll be walking you through the process of choosing the right LLM for text summarization and code generation and how to fine-tune them on MonsterAPI.

The latest LLMs are good at a lot of things, but they can’t do everything perfectly all the time. This is why fine-tuning large language models (LLMs) is key to optimizing performance for specific use cases.
But with the sheer number of LLMs available, choosing the right one for your specific use case can be overwhelming.
In this blog, we’ll be walking you through the process of choosing the right LLM for text summarization and code generation.
Choosing the Right LLM for Summarization
Let's say a startup named ‘Startup X’ wants to build a text summarization bot, that’s aimed at creating concise summaries of lengthy research papers.
The bot should be efficient enough to extract key insights while preserving the original meaning. To achieve this, Startup X would need an LLM that excels in understanding complex sentences, grasping the core message, and generating coherent and concise summaries.
Here’s how to do so:
- Narrow Down the Model Choices
The first step is identifying which LLMs can do the task at hand. There are hundreds of open-source LLMs to choose from so making the right choice is crucial. Some of the best models for text summarization include:
- LLaMa: LLAMA is a family of open-source language models developed by Meta designed for a wide range of tasks, emphasizing efficiency and versatility with smaller model sizes compared to other leading LLMs. By fine-tuning LLaMa, you can achieve a range of tasks.
- Gemma: Gemma from Google is a family of lightweight models that excel in a range of tasks while being significantly smaller than competing models. Gemma models are made from the same research that’s used to make Gemini.
- Falcon: Known for its efficiency and competitive performance, Falcon LLM offers various model sizes, including Falcon-40B and Falcon-7B, and is optimized for both research and commercial applications.
To summarize text Startup X can choose from LLaMa, Gemma, and Falcon are all strong contenders because they’re designed to understand text intricately.
- Evaluate Pre-Trained Models
Once you have a list of potential models, evaluate the performance of pre-trained versions of these models on your task. Start by running a few research papers through each model to generate summaries. Here’s what to look for:
- Accuracy: How well does the summary capture the main points?
- Coherence: Is the summary logically structured and easy to read?
- Conciseness: Does the summary avoid unnecessary details?
- Fine-Tuning the Selected Model
Let’s say Startup X decides to go forward with LLaMa Models for a text-summarization agent. Fine-tuning it for their exact needs can be a challenge. Using MonsterAPI, startup Y can fine-tune LLaMa models in 3 easy steps.
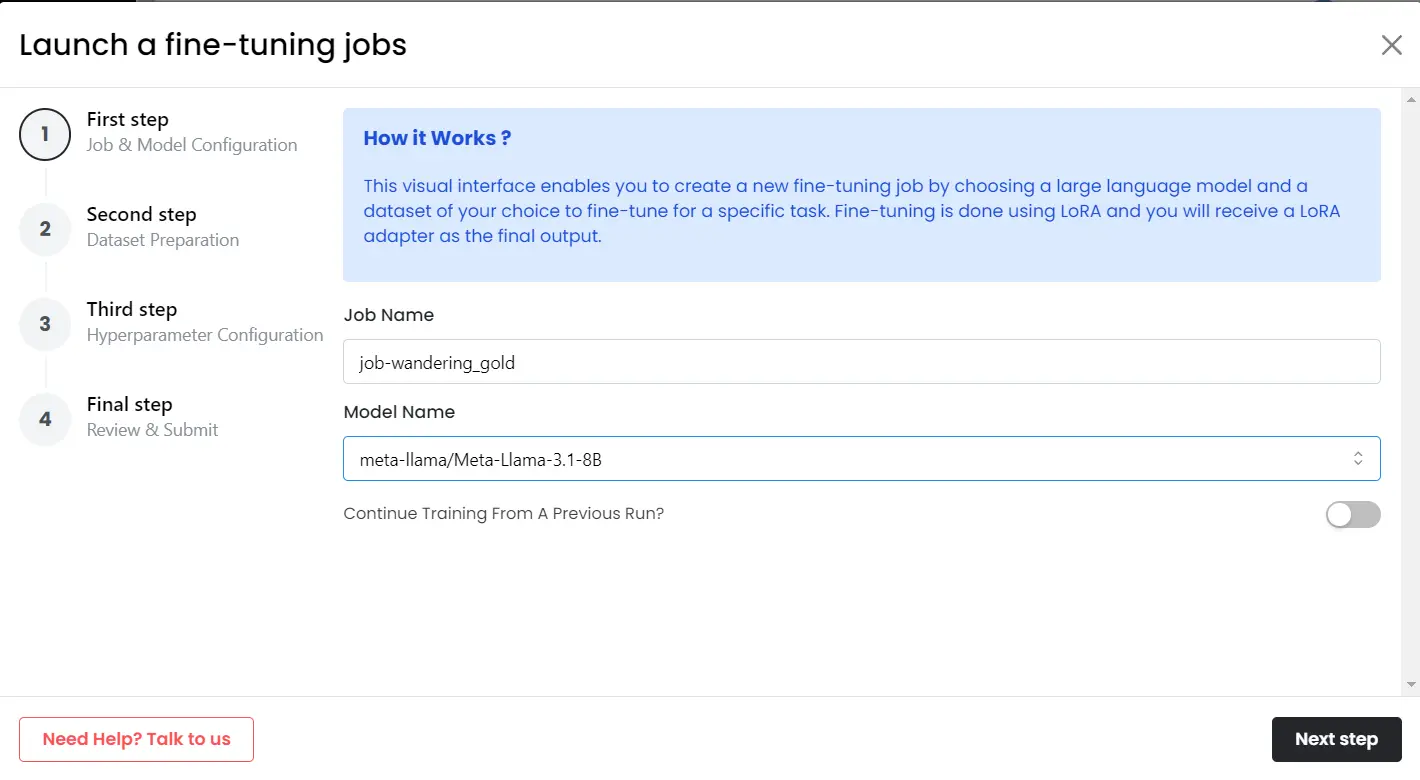
Step 1: Choose Model
- Login to MonsterAPI and go to the Dashboard.
- From the left panel, click on Fine-Tuning.
- Click on “Create a new fine-tuning job”
- Choose the job name & choose the model you want to fine-tune (we’re using the LLaMa 3.1 8B model in this example)
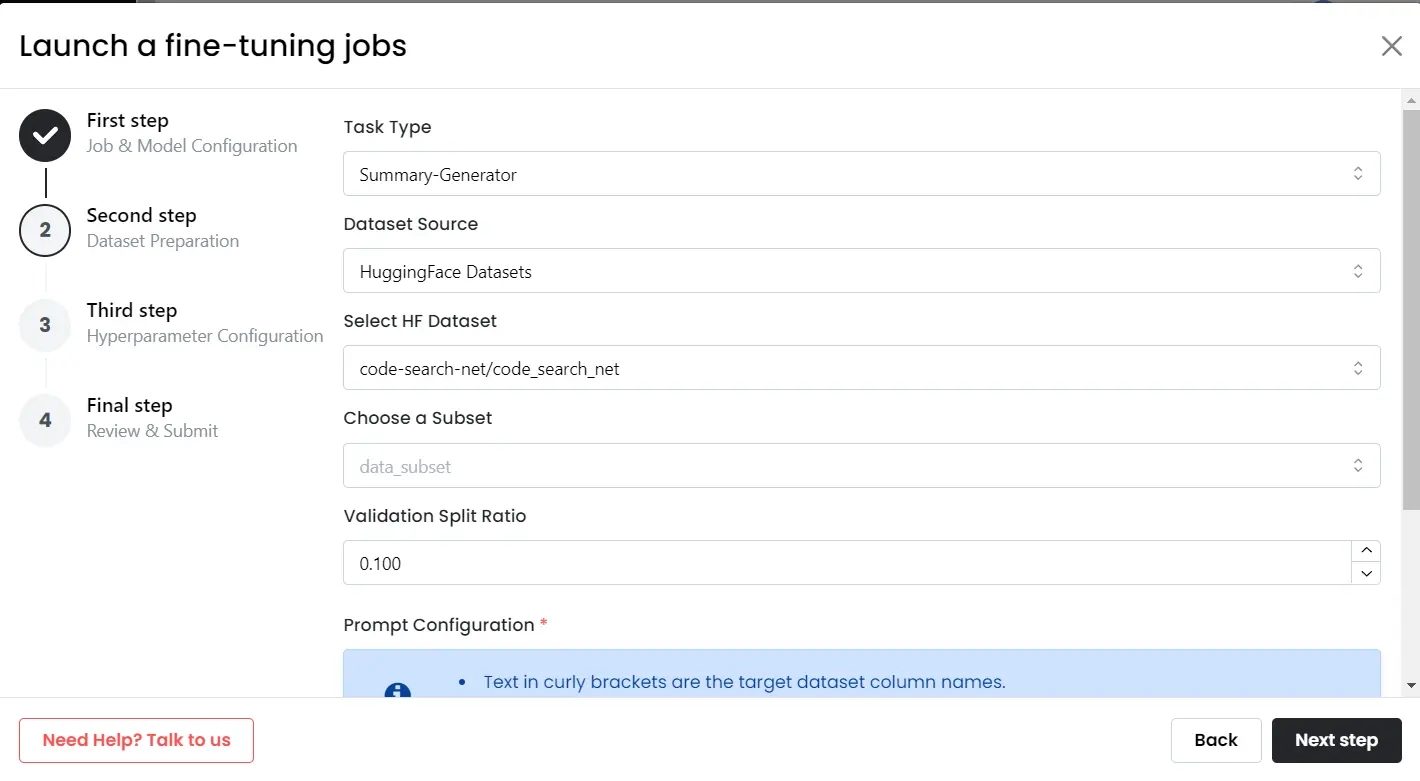
Step 2: Upload Dataset
- In the new window, choose the task type for fine-tuning.
- You can choose to upload a HuggingFace dataset or your personal dataset.
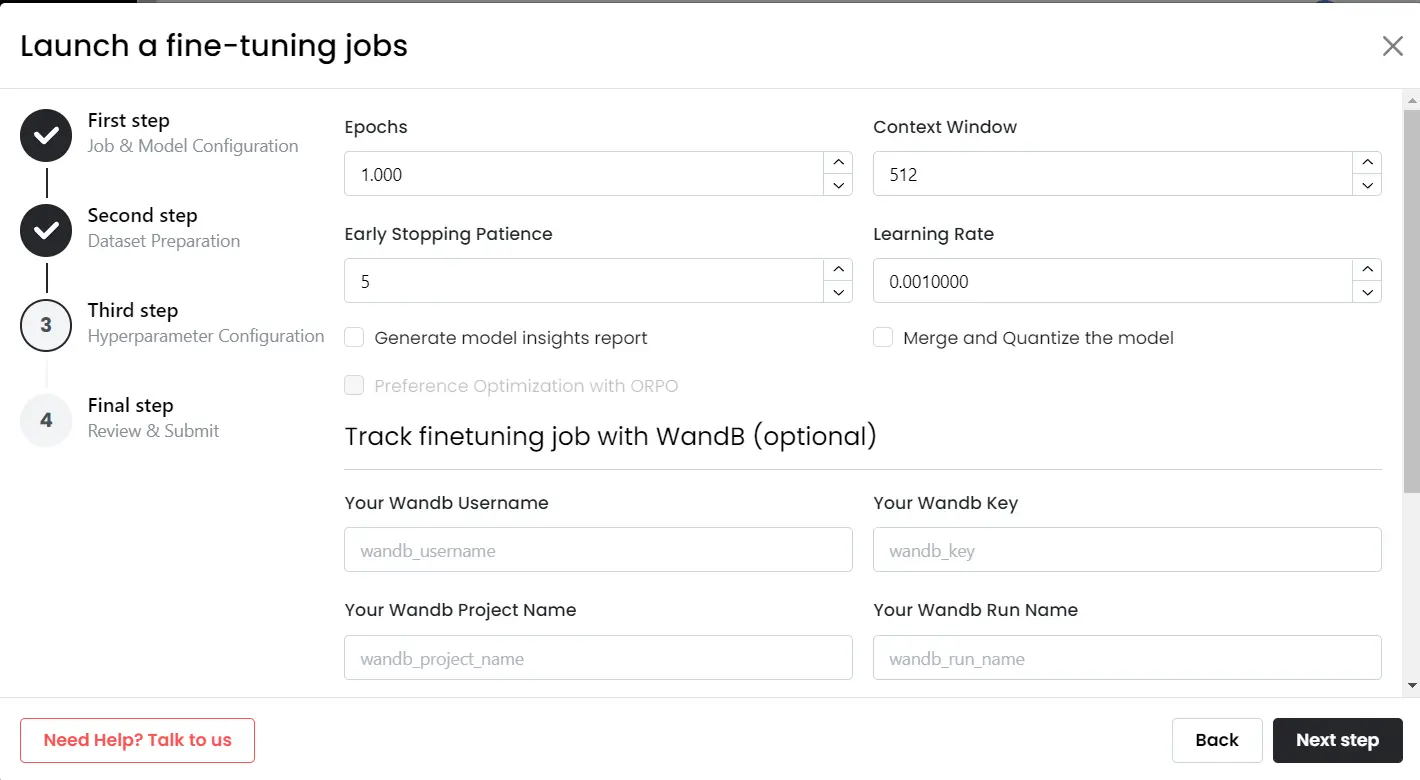
Step 3: Setup Hyperparameters & Launch Job
MonsterTuner automatically fills hyper-parameter information for you. In case you need to make adjustments to any parameters, you can. Once finalized, click on the “Next Step” button.
In the next window, click on Launch Job.
- Testing and Iteration
Once fine-tuning is complete, it’s time to test the model on unseen data. Generate summaries for a set of research papers that weren’t included in the fine-tuning dataset. Compare the model’s output against human-generated summaries to evaluate its performance.
Understanding the Use Case: Code Generation
Now, let’s switch to a different use case—code generation. Let’s take the example of Startup Y. They want to develop an AI assistant for their developers that can generate code snippets based on the prompts.
This task requires a model with a deep understanding of programming languages and the ability to generate syntactically correct and efficient code.
- Narrow Down the Model Choices
For code generation, the models of interest might include:
- Mistral 7B & Mixtral - Mistral 7B and Mixtral both outperform LLaMa 2 models on a variety of tasks. It matches the performance of CodeLlama 7B on coding tasks, making it a great choice for an AI code generator.
- CodeLlama - Code LLaMa the model from Meta is exceptional in understanding complex programming tasks, code generation, and solving coding problems. All of it makes it a strong contender for AI code generator.
- LLaMa 3.1 - The latest LLaMa models from Meta are incredible, showing exceptional performance on a variety of tasks. By fine-tuning the model, LlaMa 3.1 can be made into an AI code generator.
- Evaluate Pre-Trained Models
Give some basic prompts to the base models to verify the base performance. For example, you might input a description like “write a Python function to reverse a string” and compare the outputs. Key evaluation criteria include:
- Accuracy: Does the generated code perform the intended task?
- Efficiency: Is the code optimized and free from redundant steps?
- Readability: Is the generated code easy for a developer to understand and maintain?
- Fine-Tuning the Selected Model
Let’s say Startup Y decides to go forward with Code LLaMa for a code-generation agent. Fine-tuning it for their exact needs can be a challenge. Using MonsterAPI startup Y can fine-tune Code LLaMa in 3 easy steps.
Step 1: Choose Model
- Login to MonsterAPI and go to the Dashboard.
- From the left panel, click on Fine-Tuning.
- Click on “Create a new fine-tuning job”
- Choose the job name & choose the model you want to fine-tune (in this case CodeLLaMa)
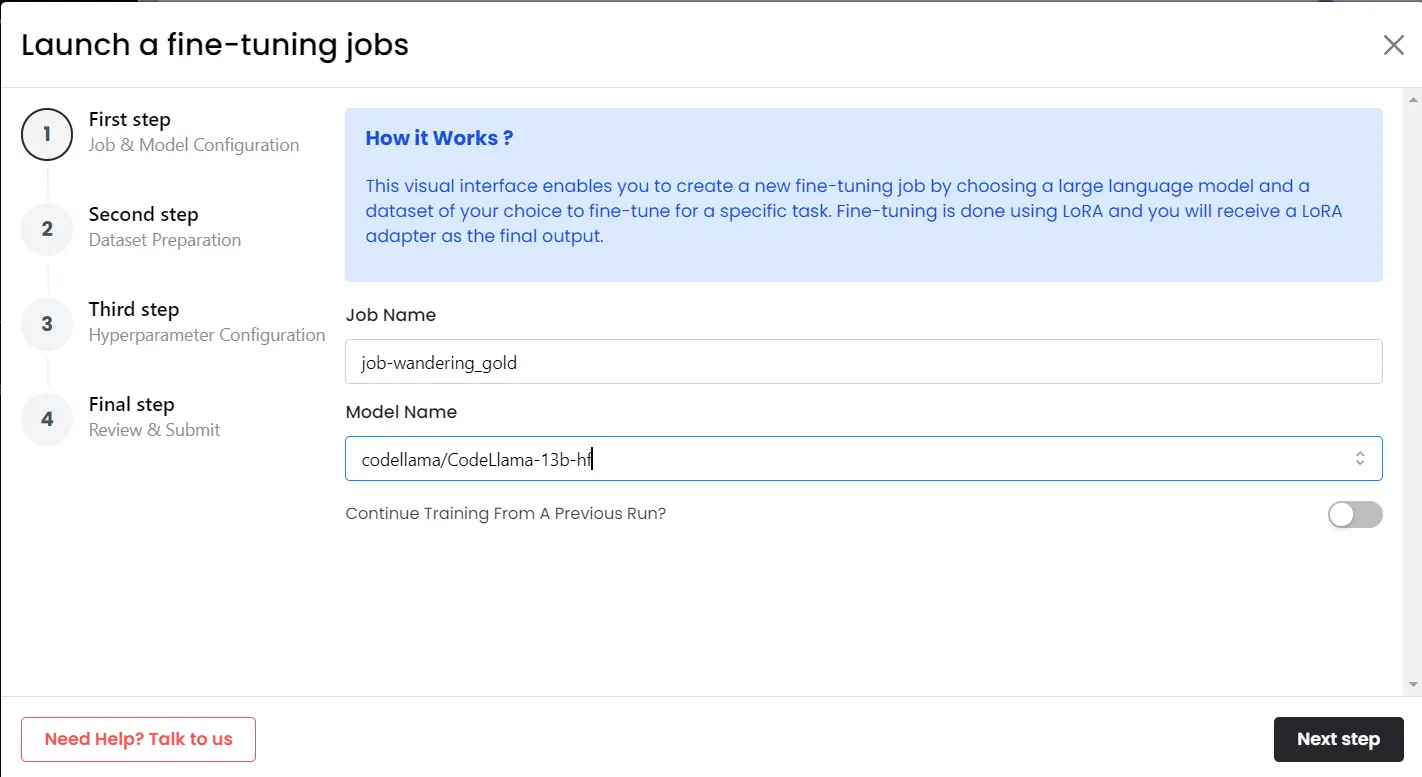
Step 2: Upload Dataset
- In the new window, choose the task type for fine-tuning.
- You can choose to upload a HuggingFace dataset or your personal dataset.
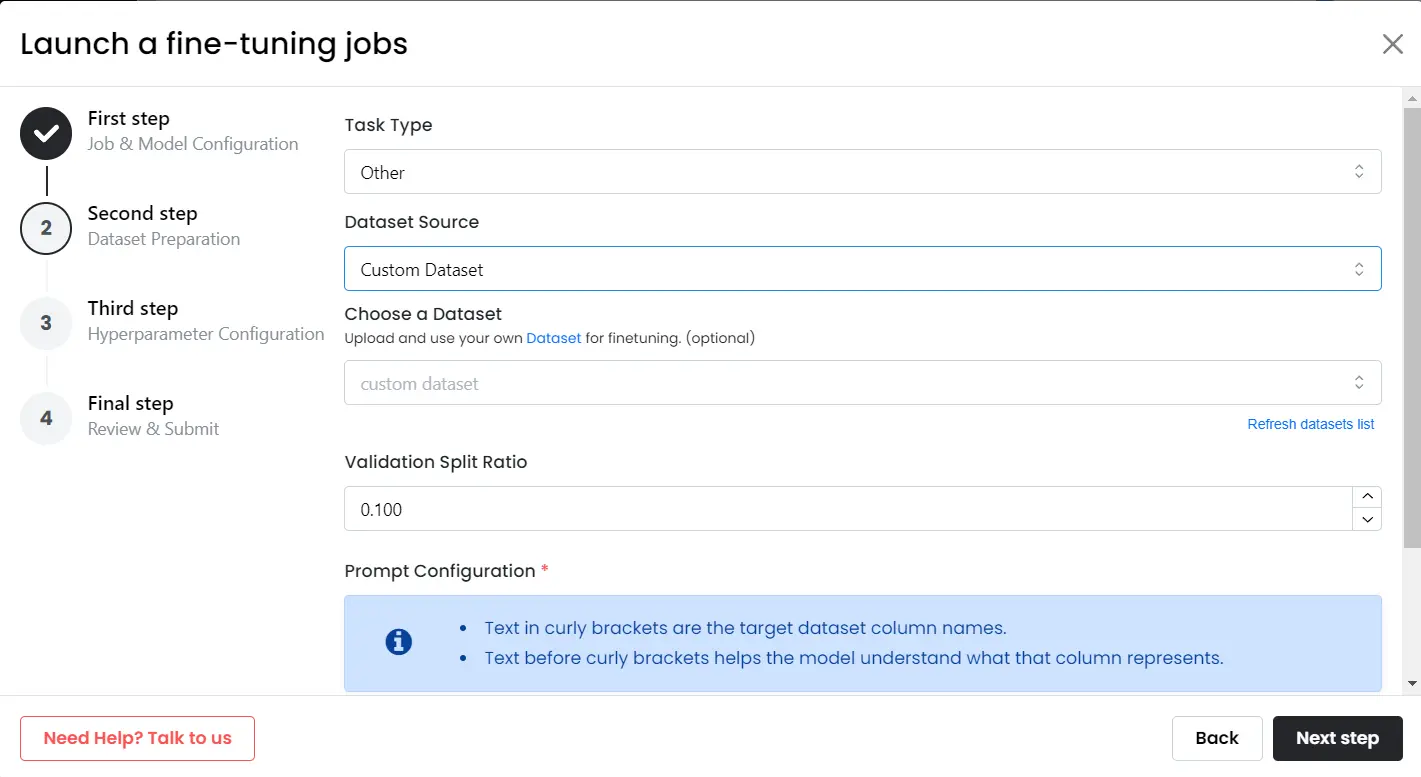
Step 3: Setup Hyperparameters & Launch Job
MonsterTuner automatically fills hyper-parameter information for you. In case you need to make adjustments to any parameters, you can. Once finalized, click on the “Next Step” button.
In the next window, click on Launch Job.
- Testing and Iteration
After fine-tuning, test the model by inputting new code generation tasks and comparing the outputs against manually written code. You might discover that the fine-tuned Codex generates highly accurate code snippets, making it suitable for integration into your AI assistant.
Conclusion
Selecting the right LLM for fine-tuning involves understanding the specific requirements of your use case, evaluating pre-trained models, and carefully fine-tuning the selected model to meet your needs.
Whether you’re working on summarization or code generation, the process requires careful consideration, rigorous testing, and continuous iteration to achieve the best results. By following this case-study approach, you can optimize your workflow to fine-tune and deploy an LLM that excels in your specific application.