
Achieving 62x Faster Inference than HuggingFace with MonsterDeploy
In this case study, we compare the inference times of Hugging Face and MonsterDeploy. Here's how we achieved 50X faster inference than Hugging Face.


As the role of Artificial Intelligence (AI) grows in businesses, there is increasing demand for model deployment. Inference time is a model's time to process input and deliver output. It has become a key parameter in model performance benchmarks.
One of the key challenges faced is poor inference time offered by large AI models. Poor inference time causes slow user experience, increased operational costs, and impact on scalability which ultimately affects the business.
In this case study we will compare the inference times achieved by deploying models through Hugging Face and MonsterAPI, and compare the improvements in efficiency and responsiveness.
In the later sections, we will see different and effective strategies for making AI models faster and more efficient in real-world applications.
Demonstrating Model Inference Time on Hugging Face
The primary goal of this experiment is to evaluate the inference performance, and for that, we will use the Meta-Llama-3.1-8B text-generation model. We also take a set of 10 diverse prompts to simulate real-world tasks.
To meet the goal of our study we will calculate the inference time for the comparison purpose. We can see the input for the model which has 10 diverse text prompts for the model.

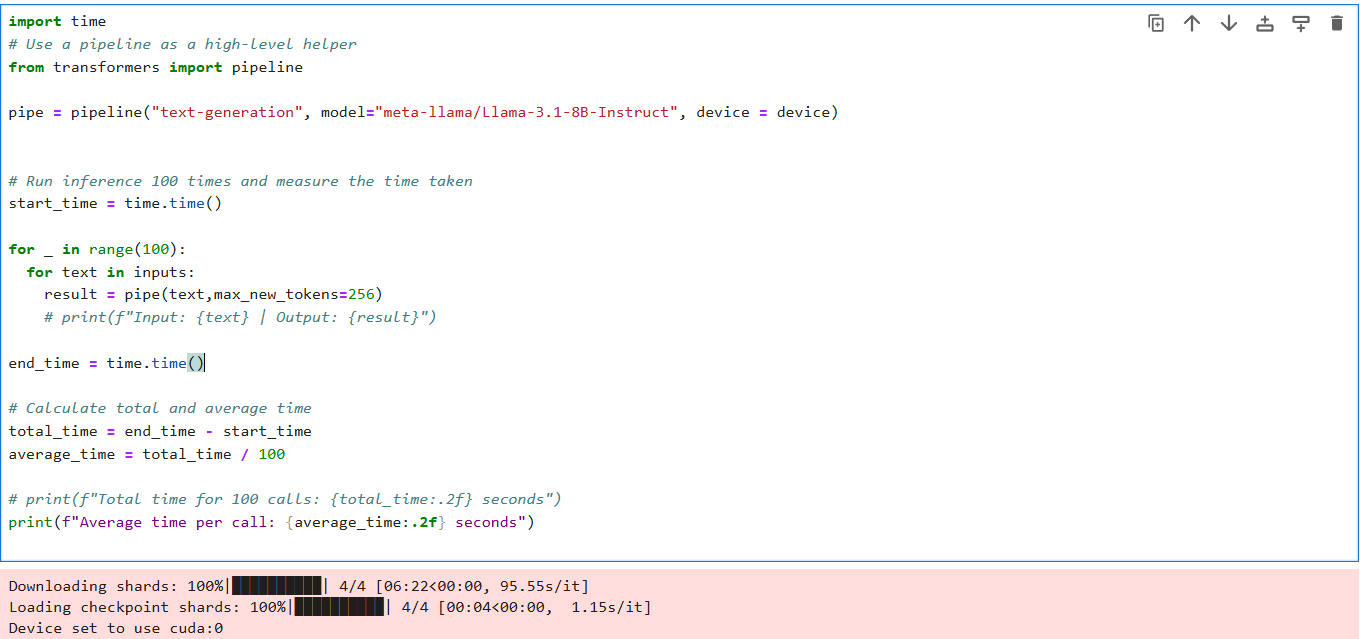
The script below measures inference time for a model from Hugging Face using the transformers library. Here, we have taken a text-generation model “meta-llama/Meta-Llama-3.1-8B” and 100 calls were made and the total and average inference times are computed to assess the model's efficiency.
For loading the model we use pipeline API from Hugging Face, and then each of the prompts in the input list was passed to the model sequentially, and the process was repeated 100 times.
We used Python's time module to calculate the time and then we took differences to get the inference time. The total time was divided by the number of calls (100) to calculate the average inference time per call.
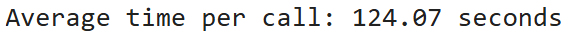
Now we will deploy the same model from MonsterAPI for the same number of calls and compare which one has less inference time.
Demonstrating Model Inference Time by Deploying a Model on MonsterAPI
To ensure a fair comparison, we will use the same model, and input prompts, and make the same number of calls as were used for Hugging Face. First, we will deploy the model from MonsterAPI, below we see the deployment of the model from MonsterAPI.
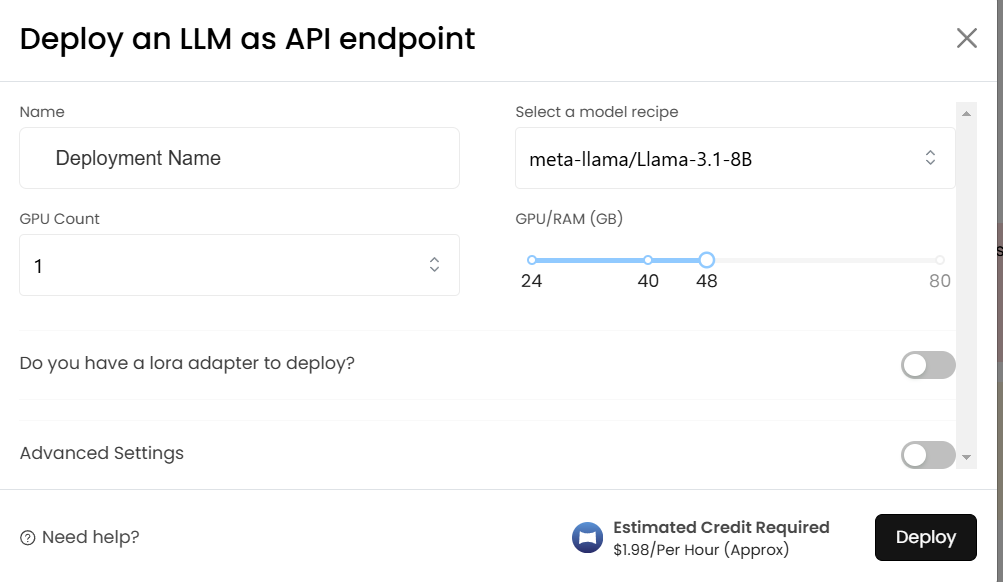

After deployment, we get the colab notebook to use the model, and the following script in the same notebook measures inference time for the model deployed through MonsterAPI.
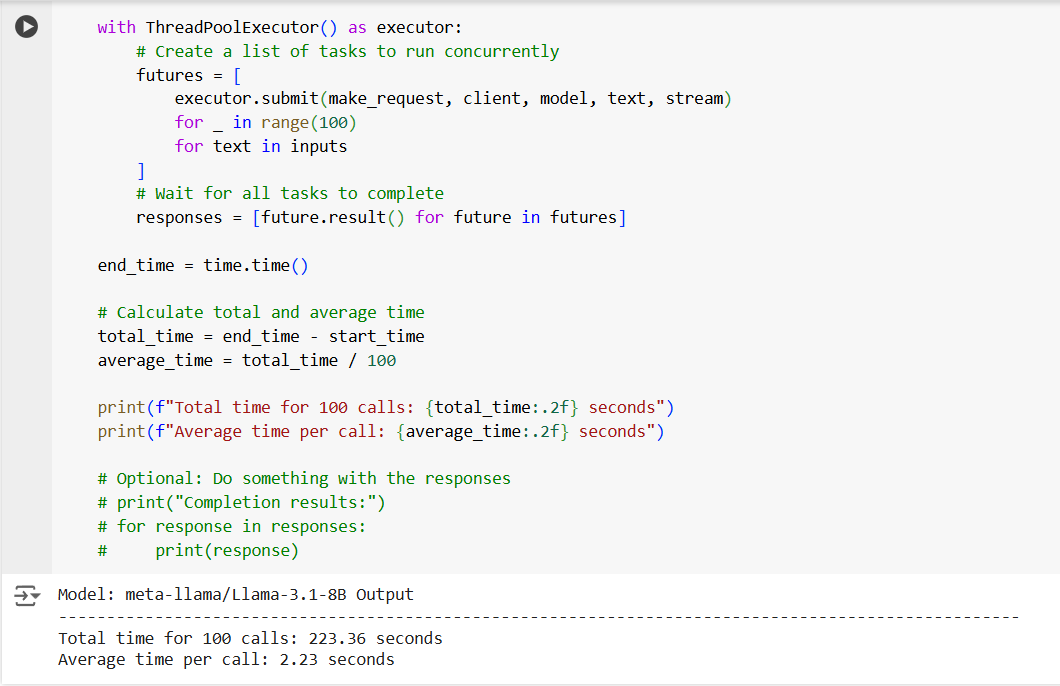
Here, you can see average time per call is just 2.23 seconds, which is 50 times faster than the average time per call on Hugging Face.
Real-World Deployment: Hugging Face vs. MonsterAPI
Now, we can observe a substantial difference in the inference times for both deployments.
Deployment through MonsterAPI significantly outperforms the deployment of the model from Hugging Face, offering up to 62x faster inference. The reason MonsterAPI performs significantly better is because of techniques like Dynamic Batching, Quantization, etc, which we will explore in the next part of this study.
Top Techniques to Boost AI Model Efficiency
Optimizing inference time involves various ways like using GPUs, using algorithms like Dynamic Batching, and using libraries like ONXX and many more. In this section, we will explore the techniques to reduce inference time in detail.
- Dynamic Batching
Dynamic batching is an optimization technique that is used to make models adapt to process multiple requests and minimize the wait times. It is the real-time adjustment of Batch Sizes. By grouping the multiple requests it reduces the duplication of tasks, reduces the costs, and also boosts the output.

To see the reference click here.
- Model Compilation
Optimizing the model involves two things, the first is reducing its memory footprint and the other is computational complexity to increase the performance. This we can achieve through two approaches: reducing the model size and compiling the model. Here we will see the Model compilation:
Model compilation means converting a trained model into an executable format optimized for particular hardware platforms. Deep learning frameworks like PyTorch, while developer-friendly, are Python-based and interpret code at runtime, making them slower compared to compiled languages like C/C++. By compiling the model, we can achieve significant speed-ups, making it 10-20 times faster.
- Quantization
Quantization is a compression technique to reduce a model's size by reducing the precision of parameters and weights in the model. The parameters are generally stored as 32-bit floating-point numbers by compression them to low precision numbers so we can make them less memory intensive. This reduces both the memory footprint and computational demands of the model.

For implementation, we can use popular libraries like PyTorch for PyTorch models, Transformers (supporting GPTQ and AWQ algorithms) for large language models, and ONNX for models in the ONNX framework.
Here is the link for ONNX you can refer to know more about the topic:
- Flash Attention 2 for Memory Management
Flash Attention 2 is also an advanced algorithm to speed up attention and reduce its memory footprint. The algorithm is an extension of a Flash Attention algorithm but with better working partitioning and parallelism. It leverages classical techniques (tiling, recomputation) to significantly speed it up and reduce memory usage from quadratic to linear in sequence length.
To know more about it check the research paper by Stanford here: paper link.
- CUDA Optimization for NVIDIA GPUs
CUDA optimization is a powerful technique for enhancing inference performance on NVIDIA GPUs. It is built on NVIDIA’s parallel computing platform, CUDA enables developers to write highly efficient code that runs directly on GPUs, significantly improving both speed and computational efficiency.
In this space, we have NVIDIA TensorRT, which is for high-performance deep learning inference built on top of CUDA. It optimizes ML models on many different levels, from model data type quantization to GPU memory optimizations. With these optimizations, TensorRT can achieve 4–5x faster inference compared to unoptimized GPU performance and up to 40x faster than CPU-only inference.
Conclusion
Optimizing inference time is crucial for businesses relying on AI. It not only enhances the user experience but also helps to reduce costs, and improve performance, and overall business growth. As discussed earlier, there are several ways to reduce inference time, such as quantization and dynamic batching.
Curious about deploying your model, start by deploying a small model on MonsterAPI to see how it performs. Here’s a helpful guide to get started: MonsterAPI Documentation.